TiDB 学习课程 Lesson-1
今年了解到 TiDB 这样一个 HTAP 数据库,在 Github 上面热度超高,再加上国人开发与维护,因此产生了很大的兴趣。
正好社区搞了一个《高性能 TiDB 课程学习计划》通过 12 节课来使学员能达到 Committer 的水平,因此就报名参加啦。
第一节课的课程作业是尝试在本地启动一个最小集群,并在开启事务时打印 “hello transaction” 并将这一过程写成一片文章,因此本文将会主要描述这一过程。
简单介绍 TiDB 架构
TiDB 是一款支持 SQL 语义并直接兼容 MySQL 通信协议的分布式关系型数据库。可以看到这句话里面包含了三个很重要的信息:
- 兼容 MySQL
- 关系型数据库
- 分布式
假如作为一个业务开发者,从外部来看,TiDB 在绝大多数情况下直接表现为一个 MySQL,业务中的各种 Select 查询,表关联,以及对事务、ACID 的要求,它都能满足。在此基础上,通过分布式实现了方便的动态扩缩容,以及高性能。
那么 MySQL + 分布式
这样一个在传统互联网应用中想要而不可得的东西,TiDB
是如何实现的呢?请看下图(转载自 PingCAP 官网,一切版权归其所有):
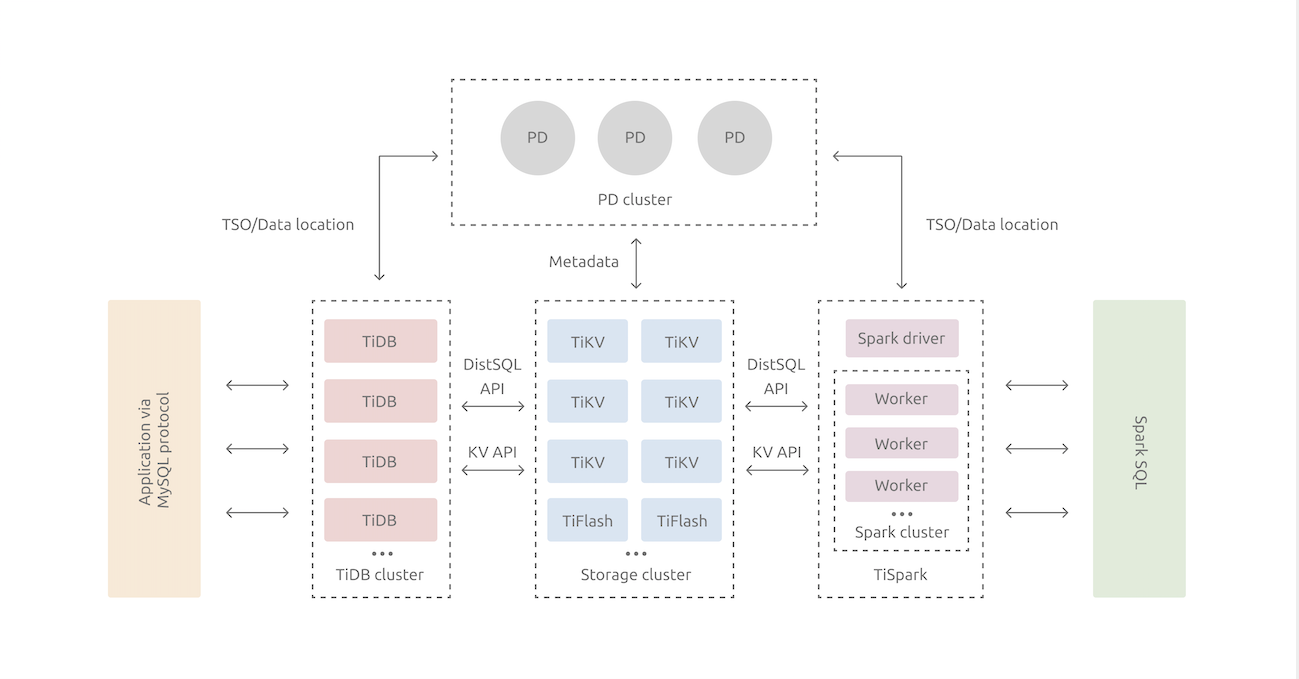
整个数据库集群分为三类模块:
- tikv:分布式 K-V 存储,通过 Raft 协议保证强一致性实现多副本的高可用,是数据的实际存储位置
- tidb:接受客户端连接,解析 SQL 语句,并转换为访问 tikv 的计算,最后收集数据并返回
- pd:placement driver,管理整个集群的元信息,并负责 tikv 节点的调度。
上述模块全都都可以多节点部署。
了解了总体架构后,我们发现,外表上看似乎是一台 MySQL,实际上除了对 MySQL 协议的支持以外,其内部结构已经和 MySQL 没有太大关系了。相比之下,TiDB 可能更像一个 Spark 集群,因此其实 TiDB 就是一个根正苗红的分布式数据库方案。
从源码开始部署
如果只谈部署的话,其实 TiDB 提供了一个非常方便的集群部署工具:TiUP,在《TiDB in action》的安装部署章节中,非常清楚的描述了 TiUP 的使:不论是部署单机测试环境还是部署集群,几条命令就能全部搞定了。
不过在我们当前的上下文中,是想要从源码开始部署的,所以,接下来我会暂时先抛开 TiUP,直接从源码开始。
STEP 1:前期准备
1. 安装 Go 环境
三大件中,tidb 和 pd 都是基于 go 开发的,所以我们首先需要安装 Go 语言的环境:
- 方法一 :官网直接下载安装包安装即可。
- 方法二:
brew install golang,但 brew 目前安装的版本是 1.14.7,实际上 1.15 已经发布了。 - 方法三:安装一个 GoLand, 在里面直接安装
安装完成后需要配置 GOROOT 和
GOPATH两个环境变量,详情可以见官网。
2. 安装 Rust 环境
直接进入 Rust 官网,可以看到在 Mac 环境上,最佳方式是通过安装
rustup 来安装 Rust 环境。就如同官网所述,Rust 采用 6
周的快速发布流程,因此在任何时候都可以通过执行
rustup update 来更新本地的 Rust。当前最新版是
1.45.2。
在安装rustup 后,相关组件都会被默认放置在
~/.cargo/bin 且环境变量都会自动被正确的配置。
3. 学习 Golang
因为先前没有接触过 Go 语言,所以先花了两天时间简单学习了 Go,从 java 切换过来入门不算太难。推荐官网教程。
4. 学习 Rust
先前我对 Rust 有过初步的了解,了解了其内存分配与释放的模型等等,官网教程很详细,但也很长... :(
STEP 2:编译运行三大件
1. 编译运行 tidb
直接 clone master 分支到本地,我们可以看到源码中提供了
Makefile,default target 会以
tidb_server/main.go作为入口进行编译。编译完成后的 binary
会输出在 bin
目录,可以直接通过./bin/tidb-server执行。
在这里大家可能会有疑问,作为集群的一份子,tidb 组件可以单独直接运行吗?
我们可以参考其命令行参数配置页面中所描述的:
--store
用来指定 TiDB 底层使用的存储引擎
默认:"mocktikv"
可以选择 "mocktikv"(本地存储引擎)或者 "tikv"(分布式存储引擎)
--path
- 对于本地存储引擎 "mocktikv" 来说,path 指定的是实际的数据存放路径
- 当
--store = tikv时,必须指定 path;当--store = mocktikv时,如果不指定 path,会使用默认值。- 对于 "TiKV" 存储引擎来说,path 指定的是实际的 PD 地址。假如在 192.168.100.113:2379、192.168.100.114:2379 和 192.168.100.115:2379 上面部署了 PD,那么 path 为 "192.168.100.113:2379, 192.168.100.114:2379, 192.168.100.115:2379"
- 默认:"/tmp/tidb"
- 可以通过
tidb-server --store=mocktikv --path=""来启动一个纯内存引擎的 TiDB
实际上在我们做出任何配置以前,默认的 tidb 不需要连接
pd,而是直接连接了其内置的
mocktikv(显然这种方式符合架构的组件依赖原则
SDP,组件之间通过抽象来定义接口)。
这种方式很方便单独对 tidb 进行开发调试。
2. 编译运行 pd
直接 clone master 分支到本地,同样的,Makefile 中已经指明,default
target 会以 cmd/pd-server/main.go作为入口进行编译。
编译完成后的 binary 会输出在 bin
目录,可以直接通过./bin/tidb-server执行。
从官方文档中可以得知,在
pd 中内置了 GUI 监控工具 TiDB Dashboard,我们将本地编译好的
pd-server
启动起来,进入浏览器输入http://127.0.0.1:2379/dashboard
即可进入 Dashboard 登录页,我们尝试使用 tidb 默认的root +
空密码登录:
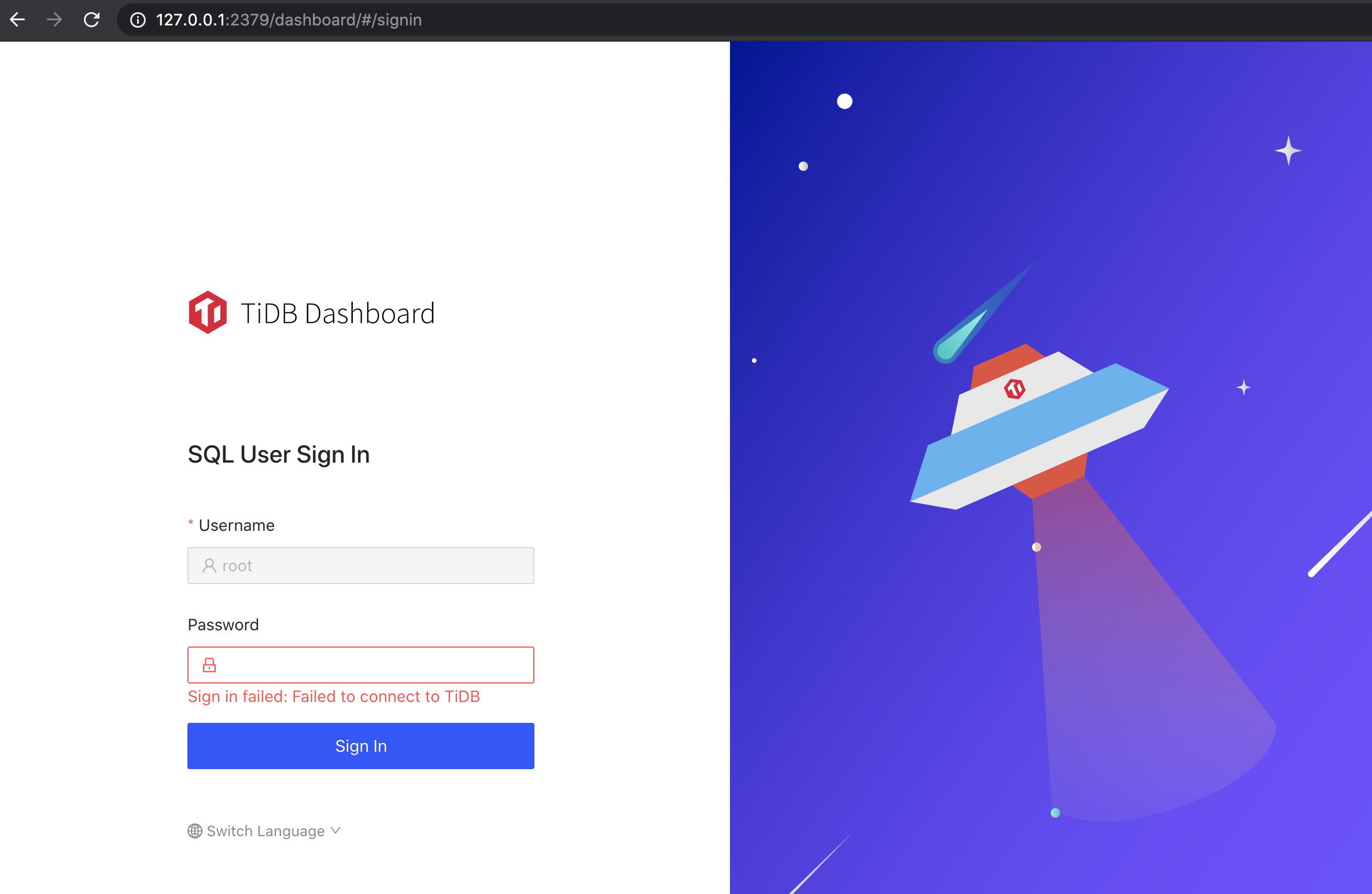
提示我们 TiDB 连不上,这是因为目前我们的集群里还没有 tidb 组件。
3. 编译运行 tikv
与 tidb 和 pd 一样,master 分支 clone 到本地后,执行
make 即可,编译挺慢,在我的 mac 上整个编译花了 16min。
Makefile 中默认是采用 release 编译,因此输出的 binary 需要到
./target/release下面找到 ./tikv-server。
之后就可以尝试启动它,在我的 mac 上遇到了一个问题:
the maximum number of open file descriptors is too small
导致启动失败,实际上是由于 mac 默认的 ulimit
中最大打开文件数是 256,而 tikv 要求的最小文件数是
82920,因此需要执行以下语句来满足要求:
sudo launchctl limit maxfiles 82920
之后就能够正常启动了。(实际上需要 3 个 tikv 节点才可以正常启动,详见下一节)
4. 启动一个最小集群:one tidb + one pd + three tikv
根据 TiKV 官方文档,我们可以采用文档中的方式来启动一个最小集群:
启动 pd:
1
2
3
4
5
6
7
8./pd-server --name=pd1 \
--data-dir=pd1 \
--client-urls="http://127.0.0.1:2379" \
--peer-urls="http://127.0.0.1:2380" \
--initial-cluster="pd1=http://127.0.0.1:2380" \
--log-file=pd1.log
*注1:其实 pd 的默认配置中都包含了上述 config 参数,因此默认单 pd 节点时可以不加任何参数。
*注2:--log-file 参数会将输出重定向到 log 文件,假如我们在 shell 中测试,可以不要该参数,输出就打印到控制台了启动 tikv (最小要求 3 个节点)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15./tikv-server --pd-endpoints="127.0.0.1:2379" \
--addr="127.0.0.1:20160" \
--data-dir=tikv1 \
--log-file=tikv1.log
./tikv-server --pd-endpoints="127.0.0.1:2379" \
--addr="127.0.0.1:20161" \
--data-dir=tikv2 \
--log-file=tikv2.log
./tikv-server --pd-endpoints="127.0.0.1:2379" \
--addr="127.0.0.1:20162" \
--data-dir=tikv3 \
--log-file=tikv3.log
*注:--log-file 参数会将输出重定向到 log 文件,假如我们在 shell 中测试,可以不要该参数,输出就打印到控制台了启动 tidb
1
./tidb-server --path="127.0.0.1:2379" --store="tikv"
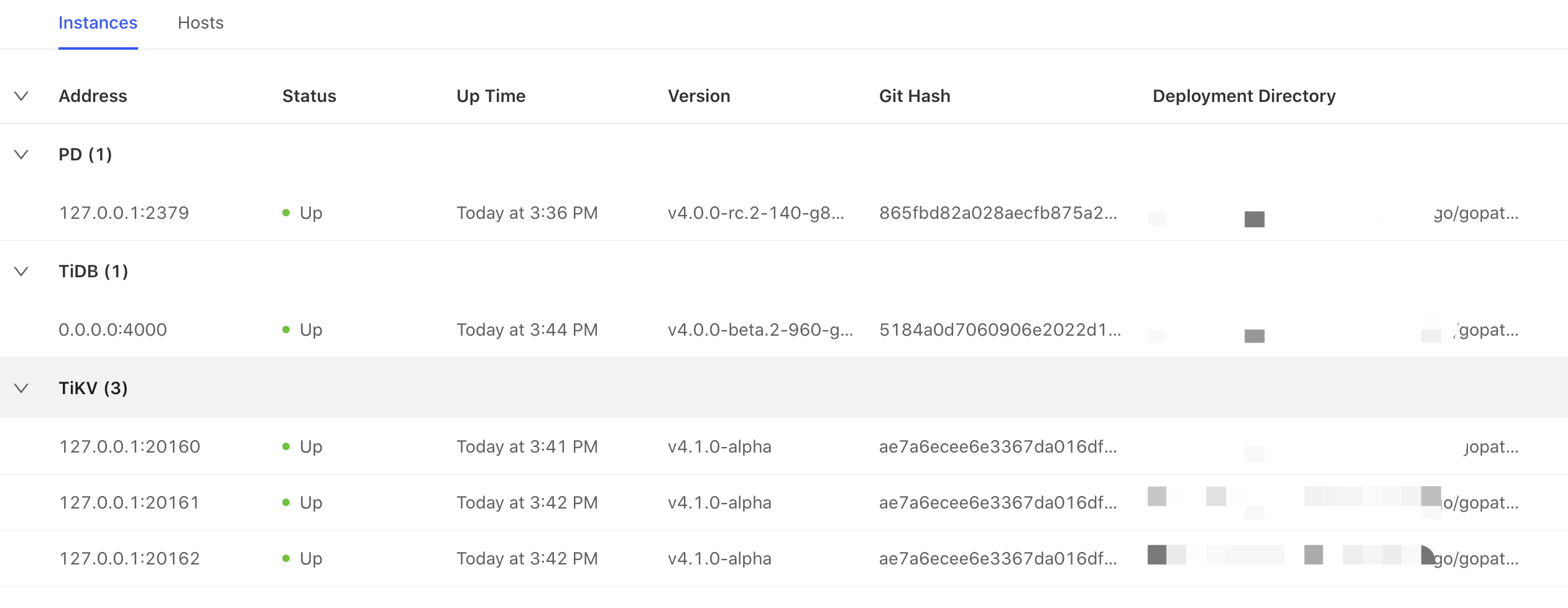
如果一切顺利的话,在互相通信的过程中它们会打印大量的日志,现在我们再进入 TiDB Dashboard,就能够顺利的登录了,然后看看 Instance 页面:
开启事务时打印 “hello transaction”
1. tidb 执行 SQL 命令的总体步骤
从源码中我们可知,tidb-server/main.go 的
main
函数作为程序入口,在启动后会执行一些读取配置、初始化等操作,之后会创建一个
server,并执行server.Run()启动 server。
之后 server 获取到的每一个 tcp 连接,都会开启一个 go routine,在 go routine 中执行连接的具体工作(go routine 真简单... 想想 netty 的 reactor 模型...):
1 | go s.onConn(clientConn) |
处理连接的主要逻辑在 conn.go包中,其中主要包括了读取 tcp
数据并分发(readPacket() 和
dispatch(ctx, data)),之后对第一个字符进行解析,解析为不同的
command,我们关注 DML
语句的执行,因此可以直接进入handleQuery(ctx, dataStr)
函数。
之后对来源数据进行 parse,将字节数组转化为 ast.StmtNode
,这里没有深入看,应该是引入了抽象语法树来描述 SQL。
之后的工作就转交至了 session.go这个包,由 session
包来执行相应的
statement,具体函数可见:ExecuteStmt(ctx, stmt)。
执行 statement
的过程中,就会涉及到对事务的操作,一开始回先将事务准备好:s.PrepareTxnCtx(ctx),之后在执行具体动作时,通过
Txn(active bool)
函数来开启事务(该函数会在等待事务时阻塞)。
2.
func (s *session) Txn(active bool) (kv.Transaction, error)
具体对事务的操作就是本函数了:
1 | func (s *session) Txn(active bool) (kv.Transaction, error) { |
可以看到,当输入参数为 false 时,代表不需要激活事务,因此直接将当前 session 的 txn 返回即可,否则,需要判断事务是否在 pending 中,如果是则等待其解除 pending(实际上是等待一个 future 完成)。
所以可以看到,我们的题目要求在开启事务时打印 “hello transaction”,那么就可以将相应代码啊添加到注释处。
3. Executor
对不同的 SQL 操作,tidb 定义了许多 Executor
来执行,例如:SelectionExec、DeleteExec、DDLExec等等。
为了验证在执行 DML 时真的开启了事务,我们可以任意选择一个
Executor,来看看在执行时是不是真的开启了事务。这里我们选择
UpdateExec。(tidb 默认开启了 auto
commit,且新版本默认开启悲观事务)
update 动作一共分为了五个步骤,
转换被修改的值
处理 null 错误
数据比较
将需要更改的值写入 on-update-now
删除旧值,插入新值
可以看到,真正的更新操作是在第五步,选取第五步中的 ”删除旧值“ 相关逻辑:
1 | func (t *TableCommon) removeRowData(ctx sessionctx.Context, h kv.Handle) error { |
我们发现在 txn.Delete(key)之前,确实先执行了
ctx.Txn(true)。
4. 运行结果
最后,将改动后的 tidb 重新编译,加入到先前的集群中,执行一下 insert 或者 update 语句,我们就能看到如下输出:
1 | [2020/08/16 16:55:21.158 +08:00] [INFO] [set.go:216] ["set session var"] [conn=2] [name=tx_read_only] [val=0] |
以上是对有主键约束的一行进行重复插入而打印的日志,可以看到打印的:["hello transaction"]。
另外,在做了上述修改后,tidb 会每隔 3 秒打印 7 条
["hello transaction"],怀疑是后台定时任务所致。
1 | [2020/08/16 16:58:59.661 +08:00] [INFO] [session.go:1454] ["hello transaction"] |