Kubernetes master is running at https://127.0.0.1:59370 KubeDNS is running at https://127.0.0.1:59370/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
> helm repo add stable https://kubernetes-charts.storage.googleapis.com/ "stable" has been added to your repositories > helm repo add pingcap https://charts.pingcap.org/ "pingcap" has been added to your repositories
安装 TiDB Operator 到集群
接下来为 TiDB 创建一个 namespace:
1 2
> kubectl create namespace tidb-admin namespace/tidb-admin created
万事俱备,现在可以正式开始安装 TiDB Operator 到我们的 K8S
集群了:
1 2 3 4 5 6 7 8 9 10 11
> helm install --namespace tidb-admin tidb-operator pingcap/tidb-operator --version v1.1.3 NAME: tidb-operator LAST DEPLOYED: Thu Aug 20 22:11:51 2020 NAMESPACE: tidb-admin STATUS: deployed REVISION: 1 TEST SUITE: None NOTES: Make sure tidb-operator components are running:
kubectl get pods --namespace tidb-admin -l app.kubernetes.io/instance=tidb-operator
如同上述输出所要求的,我们来查看一下 pod 信息:
1 2 3 4
> kubectl get pods --namespace tidb-admin -l app.kubernetes.io/instance=tidb-operator NAME READY STATUS RESTARTS AGE tidb-controller-manager-588848b7b6-mr9cv 1/1 Running 0 67s tidb-scheduler-764cfb57d9-97tvx 2/2 Running 0 67s
# 下载 CRD 到本地 > curl -o crd.yaml https://raw.githubusercontent.com/pingcap/tidb-operator/master/manifests/crd.yaml % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 703k 100 703k 0 0 439k 0 0:00:01 0:00:01 --:--:-- 439k # 安装 > kubectl apply -f crd.yaml customresourcedefinition.apiextensions.k8s.io/tidbclusters.pingcap.com created customresourcedefinition.apiextensions.k8s.io/backups.pingcap.com created customresourcedefinition.apiextensions.k8s.io/restores.pingcap.com created customresourcedefinition.apiextensions.k8s.io/backupschedules.pingcap.com created customresourcedefinition.apiextensions.k8s.io/tidbmonitors.pingcap.com created customresourcedefinition.apiextensions.k8s.io/tidbinitializers.pingcap.com created customresourcedefinition.apiextensions.k8s.io/tidbclusterautoscalers.pingcap.com created customresourcedefinition.apiextensions.k8s.io/tidbgroups.pingcap.com created customresourcedefinition.apiextensions.k8s.io/tikvgroups.pingcap.com created # 查看 tidbclusters > kubectl get crd tidbclusters.pingcap.com NAME CREATED AT tidbclusters.pingcap.com 2020-08-20T15:08:03Z
> helm search repo pingcap NAME CHART VERSION APP VERSION DESCRIPTION pingcap/tidb-backup v1.1.3 A Helm chart for TiDB Backup or Restore pingcap/tidb-cluster v1.1.3 A Helm chart for TiDB Cluster pingcap/tidb-drainer v1.1.3 A Helm chart for TiDB Binlog drainer. pingcap/tidb-lightning latest A Helm chart for TiDB Lightning pingcap/tidb-operator v1.1.3 tidb-operator Helm chart for Kubernetes pingcap/tikv-importer v1.1.3 A Helm chart for TiKV Importer pingcap/tikv-operator v0.1.0 v0.1.0 A Helm chart for Kubernetes
# 创建一个 namespace:tidb-cluster > kubectl create namespace tidb-cluster namespace/tidb-cluster created # 用 helm 安装 > helm install --namespace tidb-cluster tidb-cluster pingcap/tidb-cluster --version v1.1.3 NAME: tidb-cluster LAST DEPLOYED: Thu Aug 20 23:16:07 2020 NAMESPACE: tidb-cluster STATUS: deployed REVISION: 1 TEST SUITE: None NOTES: Cluster Startup 1. Watch tidb-cluster up and running watch kubectl get pods --namespace tidb-cluster -l app.kubernetes.io/instance=tidb-cluster -o wide 2. List services in the tidb-cluster kubectl get services --namespace tidb-cluster -l app.kubernetes.io/instance=tidb-cluster
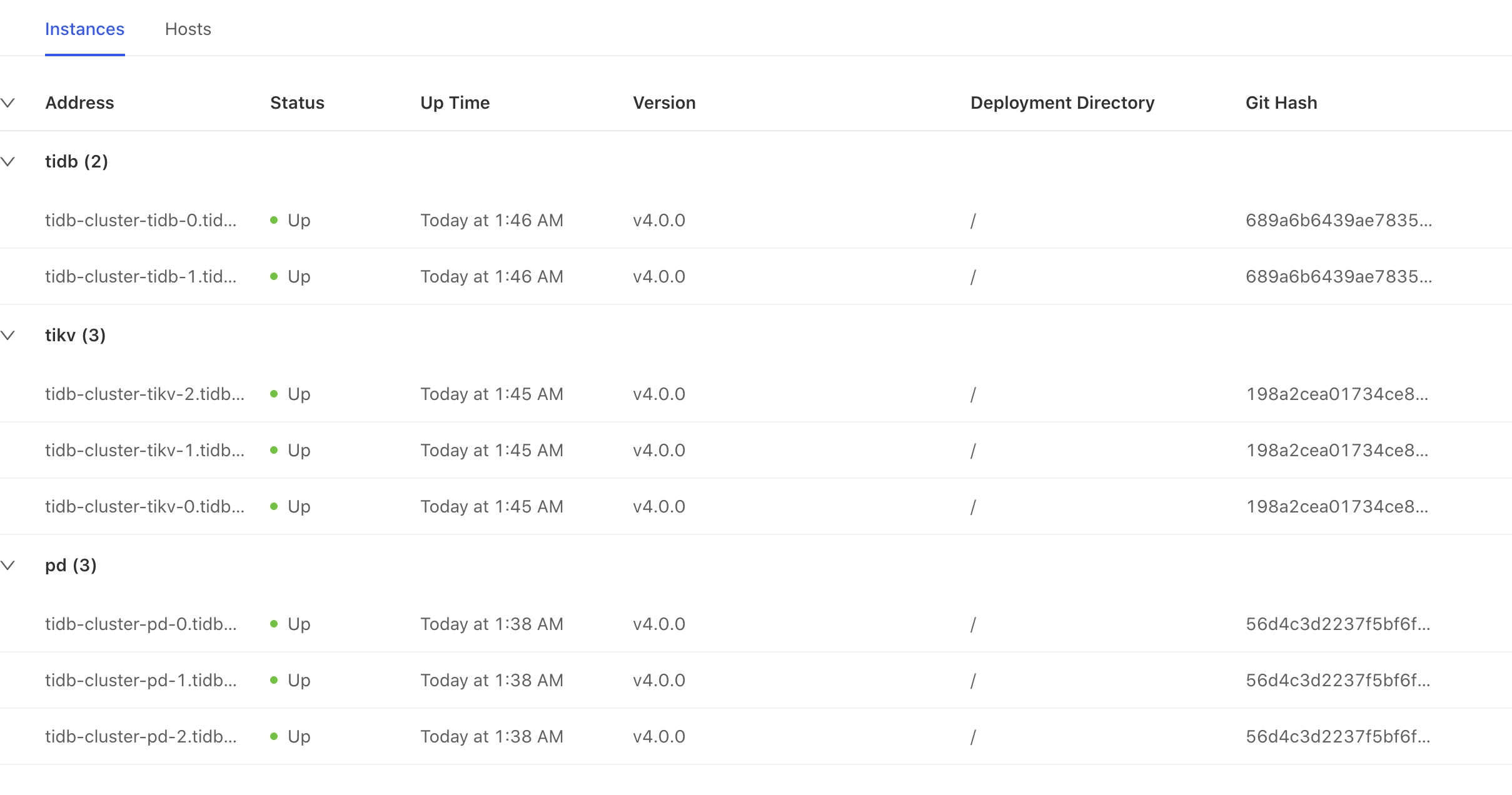
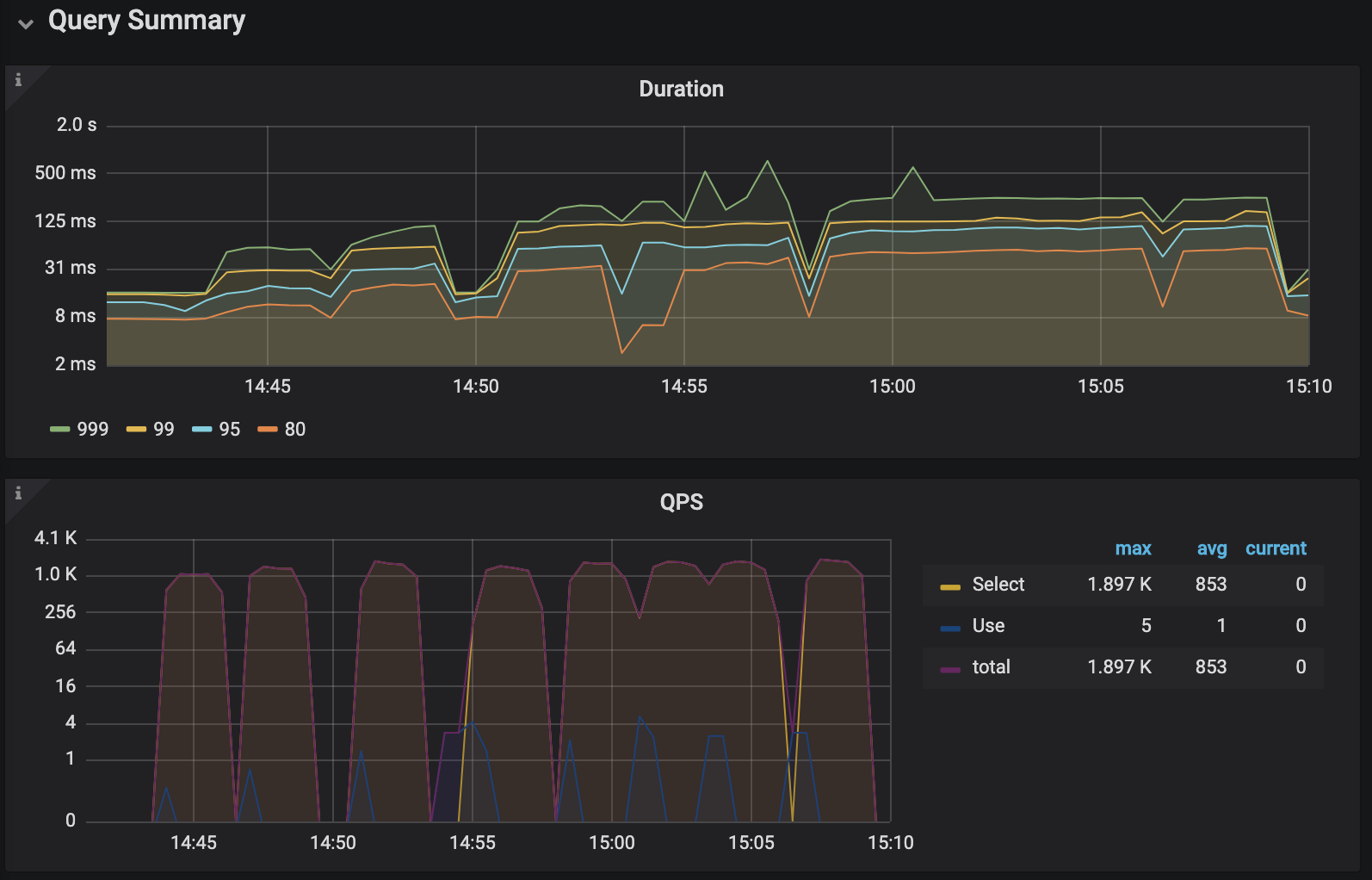
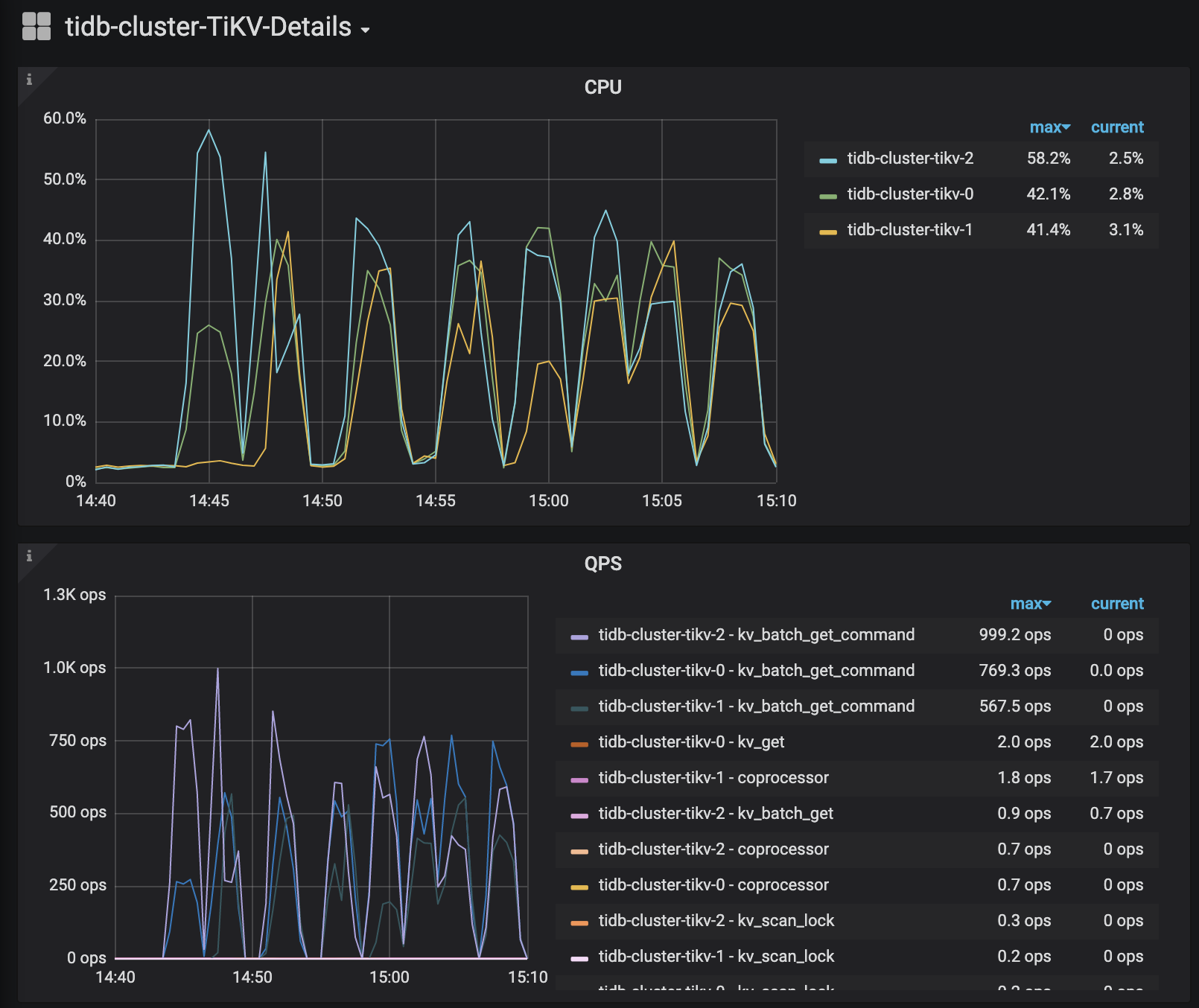
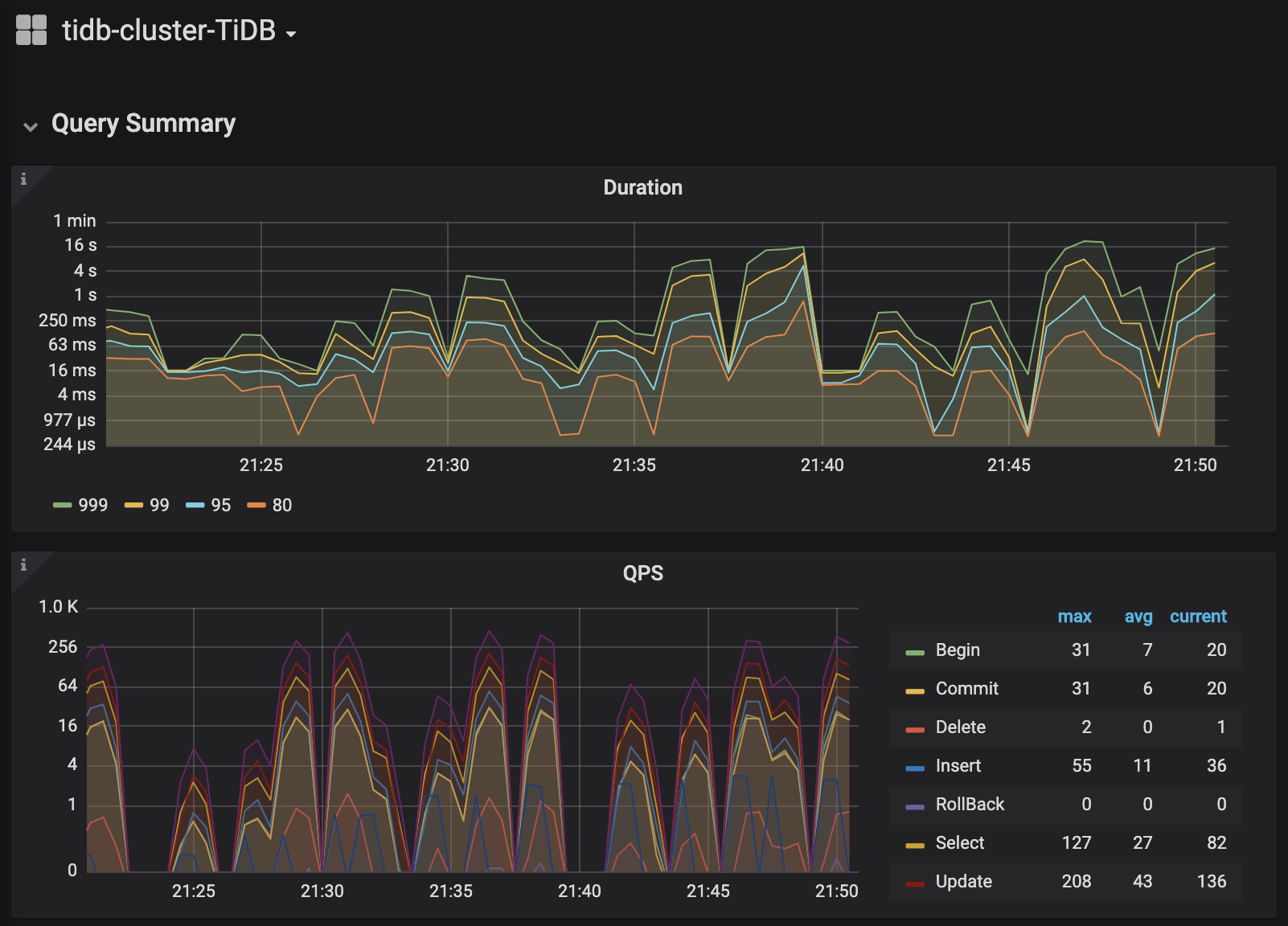
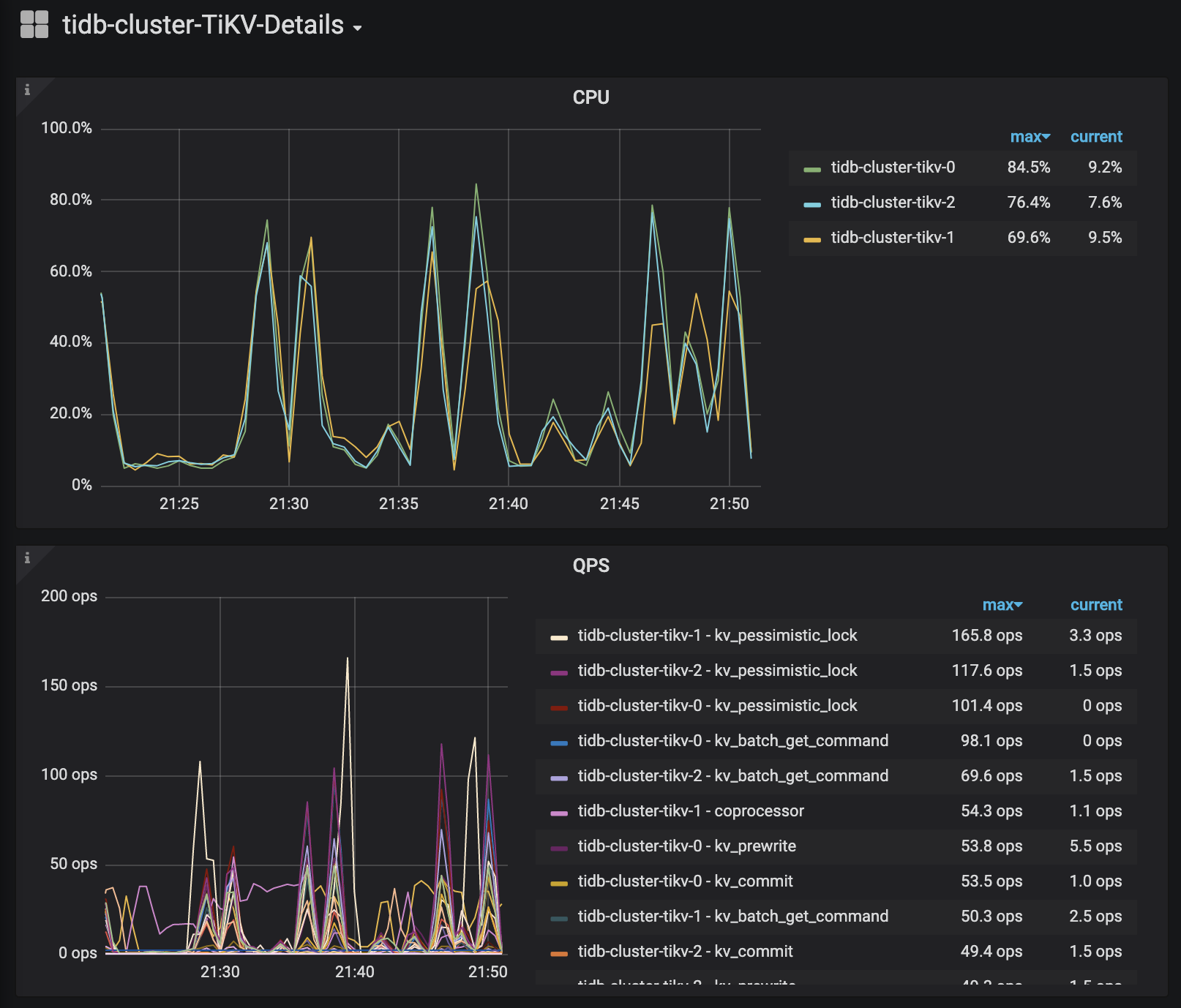
Cluster access * Access tidb-cluster using the MySQL client kubectl port-forward -n tidb-cluster svc/tidb-cluster-tidb 4000:4000 & mysql -h 127.0.0.1 -P 4000 -u root -D test Set a password for your user SET PASSWORD FOR 'root'@'%' = '3l4hWfGDpQ'; FLUSH PRIVILEGES; * View monitor dashboard for TiDB cluster kubectl port-forward -n tidb-cluster svc/tidb-cluster-grafana 3000:3000 Open browser at http://localhost:3000. The default username and password is admin/admin. If you are running this from a remote machine, you must specify the server's external IP address.
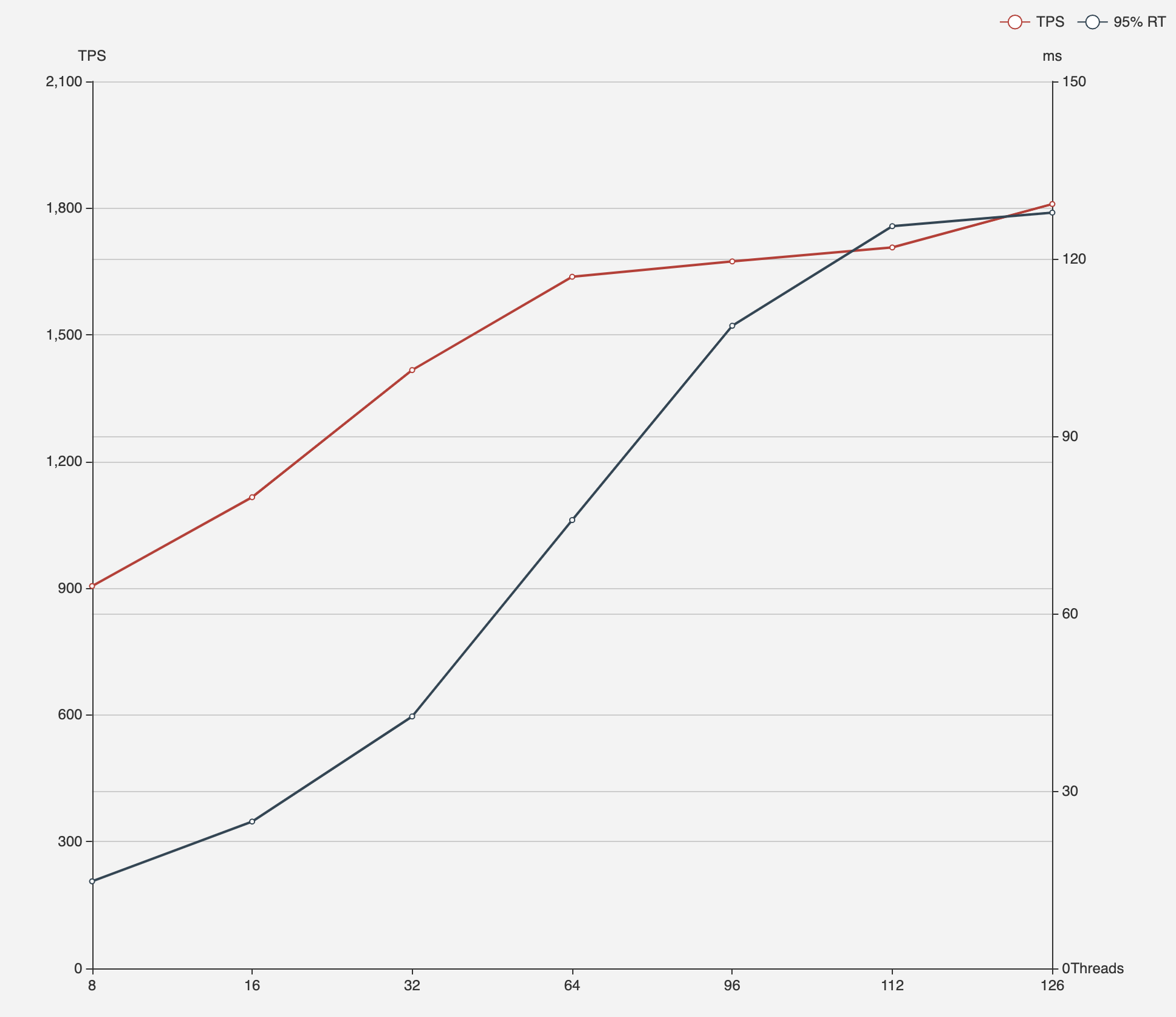
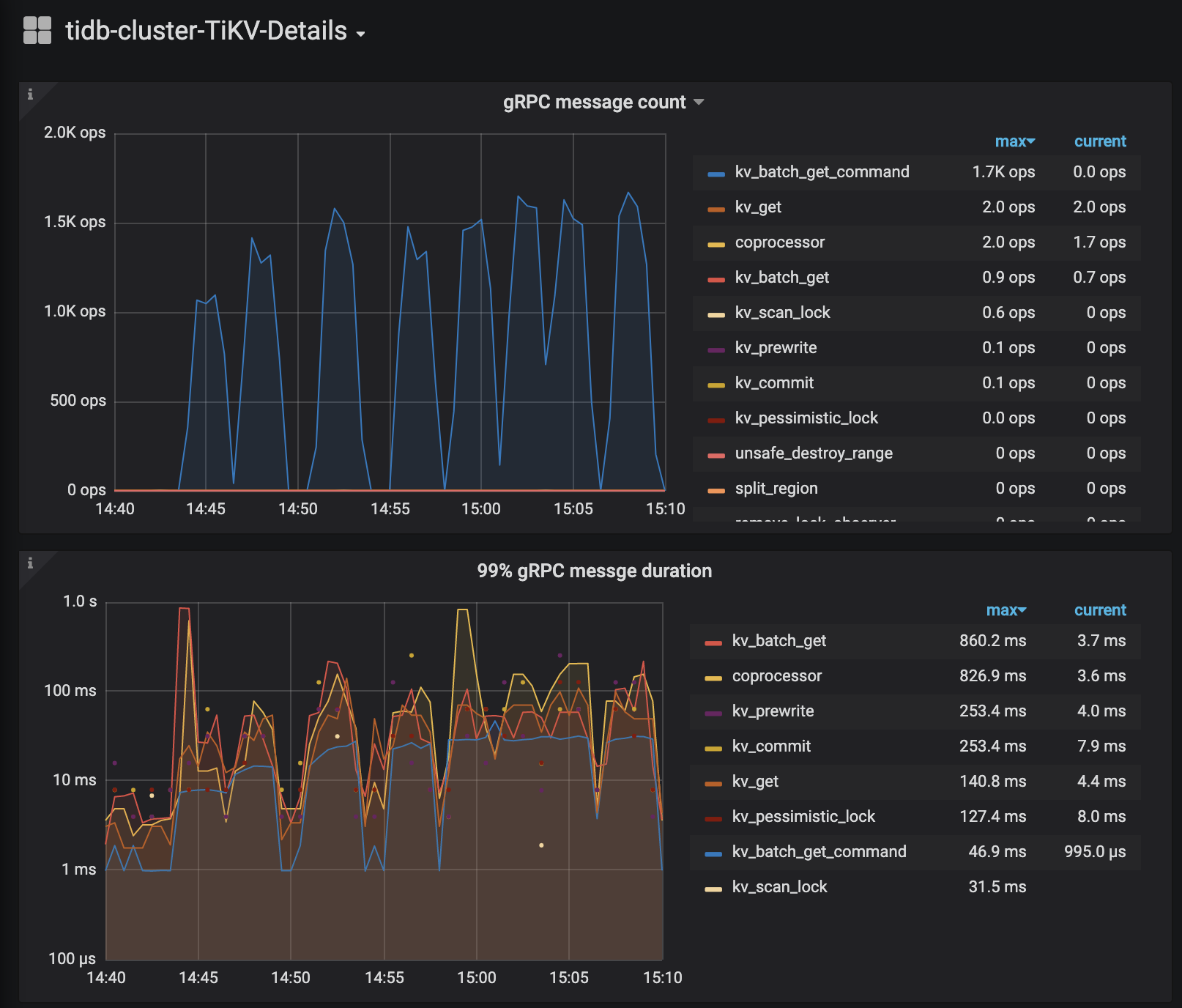
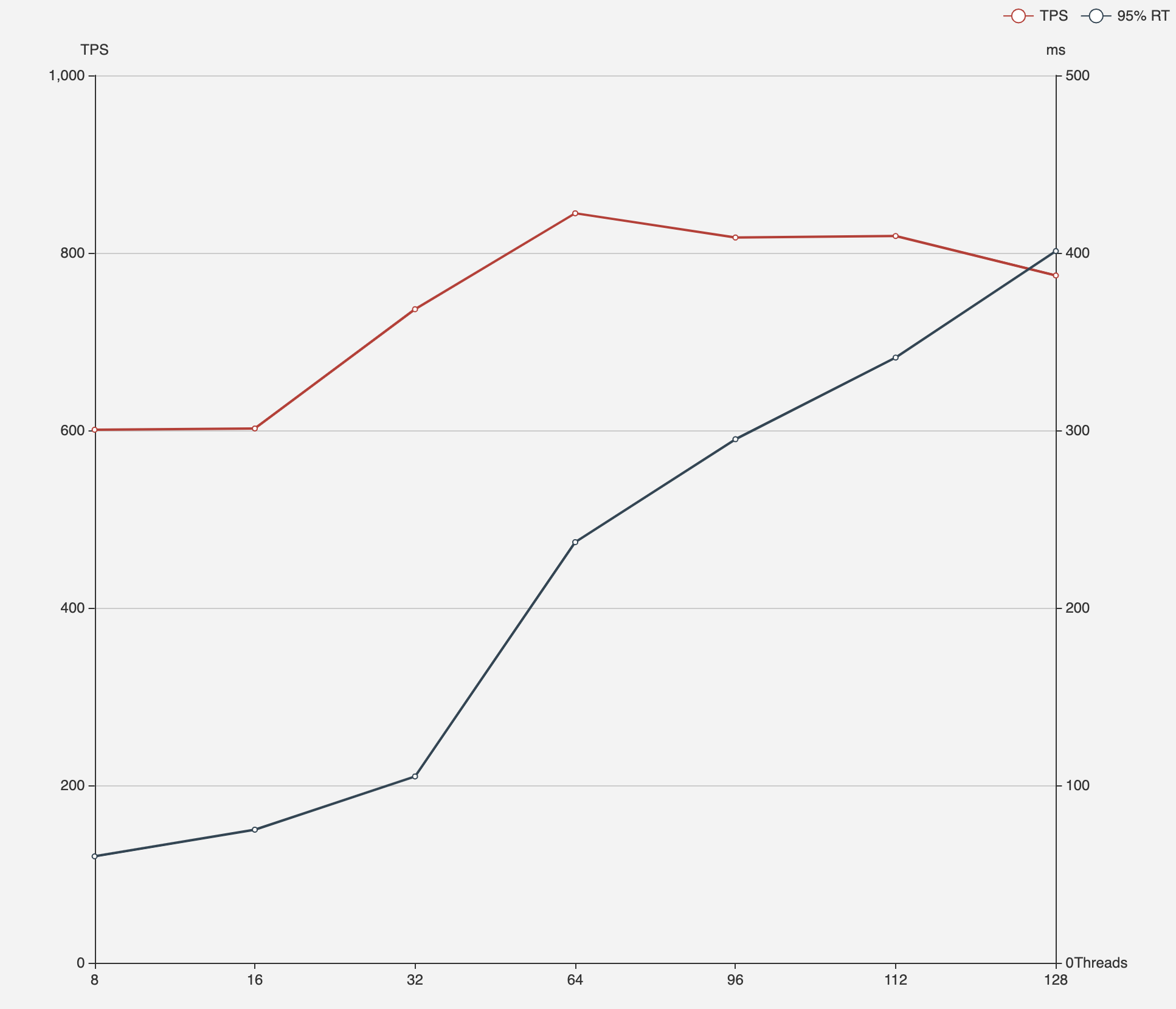
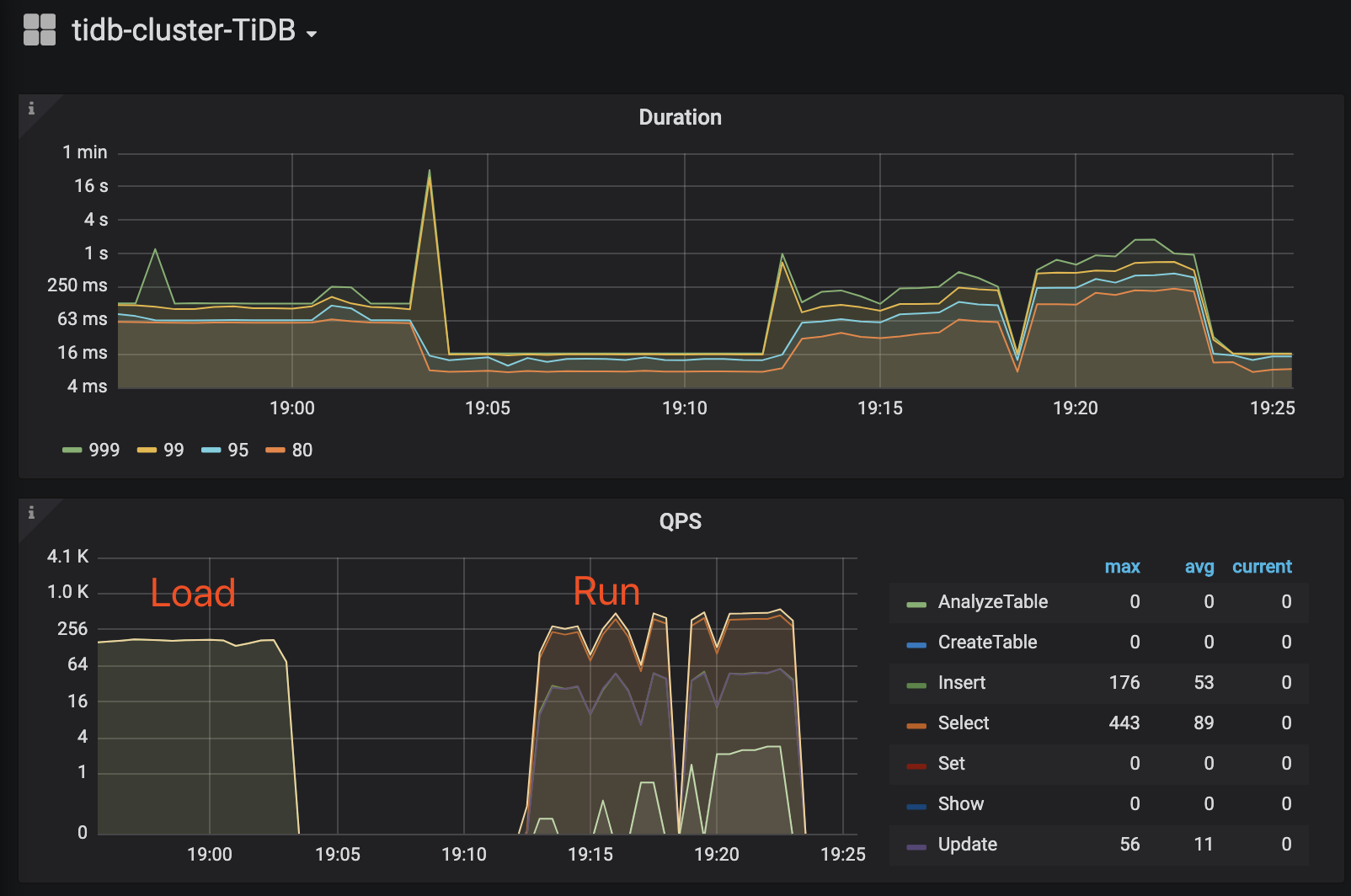
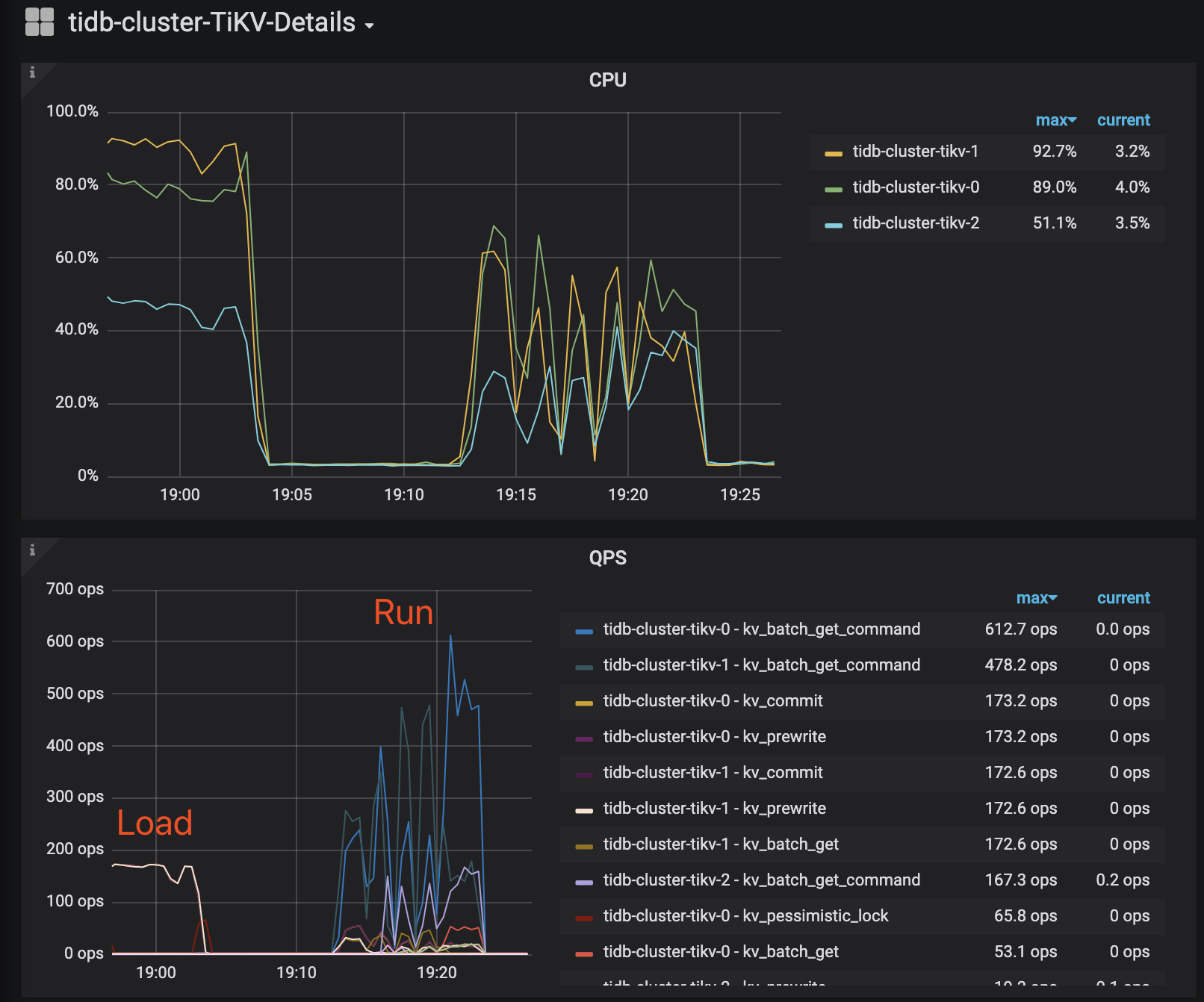
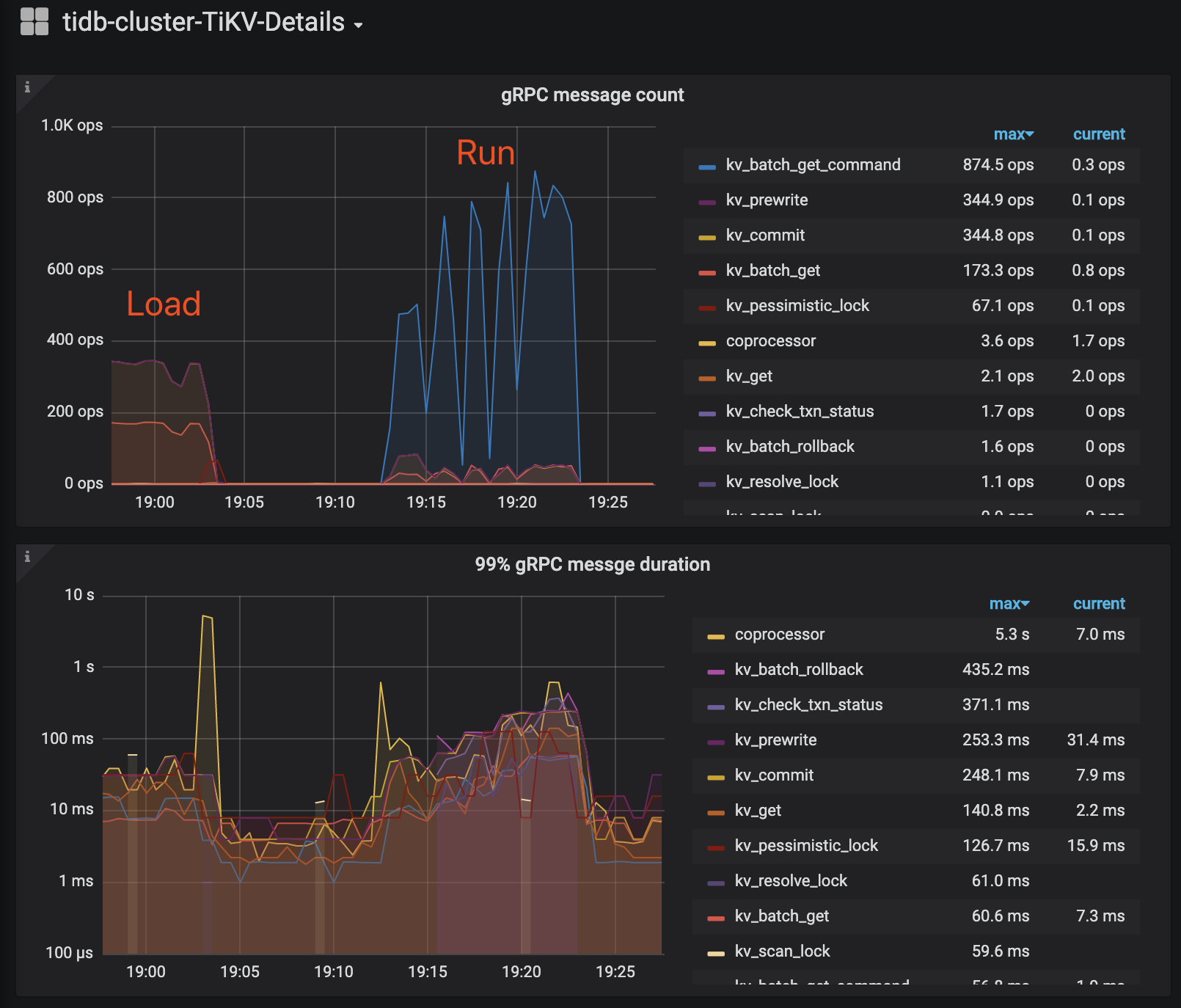
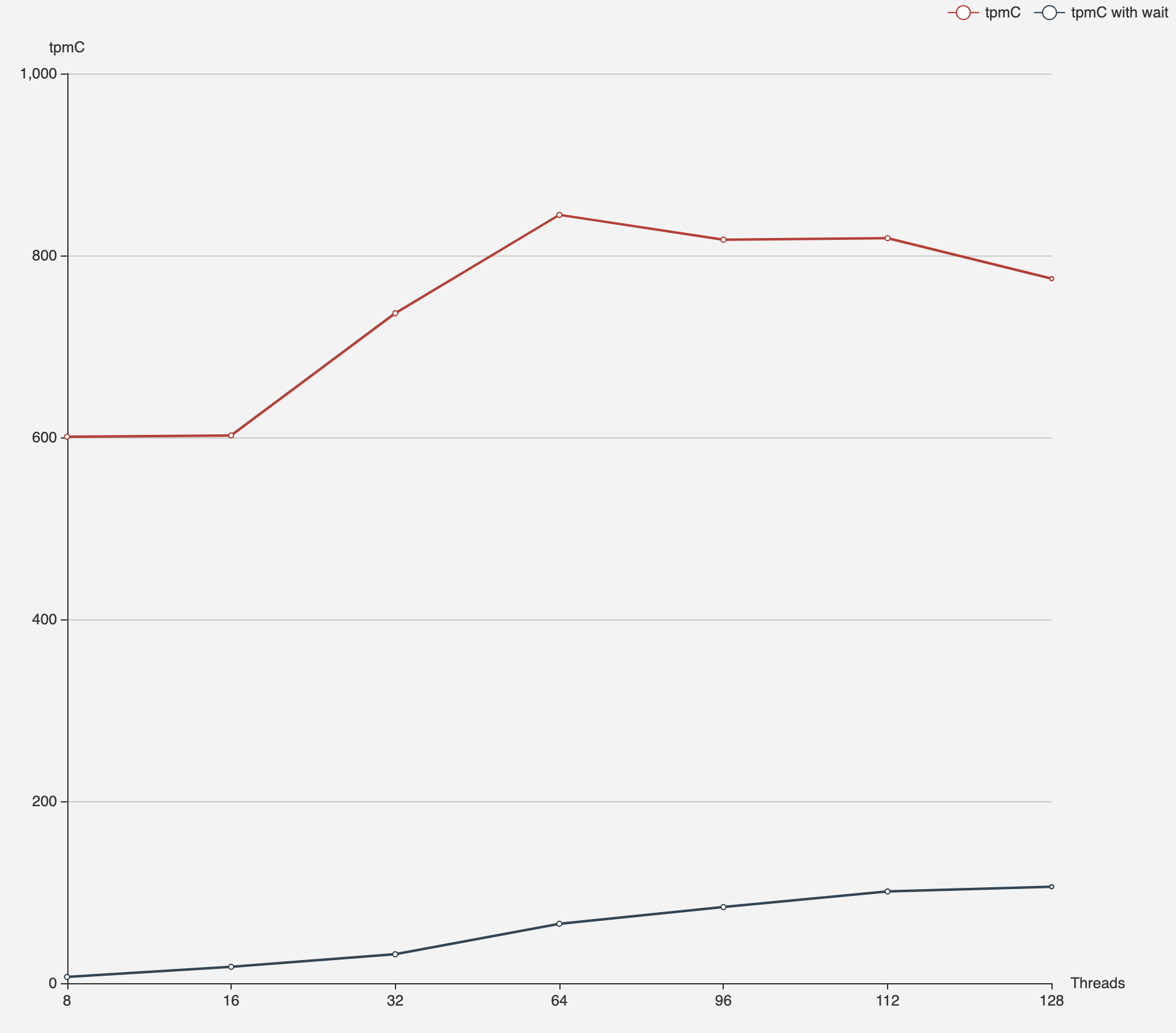
# load data > ./bin/go-ycsb load mysql -P basic.properties -P runtime-config/workload.properties --thread=8 # run test > ./bin/go-ycsb run mysql -P runtime-config/basic.properties -P runtime-config/workload.properties --threads=8