TiDB 学习课程 Lesson-3
本节课程作业,我们会采用多种 profile 工具来对 TiDB 的性能进行分析,寻找其性能瓶颈,并根据分析结果来给出优化建议。
主要内容如下:
- TiUP 部署最小集群
- TiDB CPU Profile
- 性能瓶颈分析与优化建议
TiUP 部署最小集群
为了确保与官方文档中建议的环境一致,我选择在 docker 容器中启动 centos7 环境,再借助 TiUP 部署本地集群。 1. 给出 Dockerfile:
1
2
3
4
5
6
7
8
9
10
11
12
13
14## 使用 centos7 作为基础镜像
FROM centos:centos7
## 安装 tiup
RUN /bin/bash -c 'curl --proto '=https' --tlsv1.2 -sSf https://tiup-mirrors.pingcap.com/install.sh | sh'
## 设定环境变量
ENV PATH /root/.tiup/bin:$PATH
## 安装 tiup playground 所需的所有组件
RUN /bin/bash -c 'tiup install playground | tiup install prometheus | tiup install pd | tiup install tikv | tiup install tidb | tiup install grafana'
## 设定 entrypoint 启动 playground 集群,host 映射到 0.0.0.0
ENTRYPOINT tiup --tag=local-tidb-cluster playground --db=1 --kv=3 --pd=1 --tiflash=0 --monitor --host=0.0.0.0
启动容器环境: docker-compose.yaml 如下所示,
1
2
3
4
5
6
7
8
9
10
11
12version: '2.0'
services:
tiup-playground-cluster:
build:
context: .
dockerfile: Dockerfile
ports:
- "4000:4000"
- "2379:2379"
- "9090:9090"
- "3000:3000"
- "10080:10080"1
2启动容器
docker-compose up -d通过上一次课程作业提到的压测工具,对部署的 TiDB 集群进行测试。
TiDB CPU Profile
由于采用多种测试手段(例如上一节课讲到的 sysbench、ycsb、tpcc)对 TiDB + TiKV 进行全方位的 CPU + IO + Memory 的 profiling 并对其结果进行整合分析是一项比较大的工程。
因此,本文对 Profiling 的 scope 做了限定,只针对在 tpcc 测试方法下的 TiDB 的 CPU 使用情况进行 Profiling,并分析。
在确定了方向后,我们开始动手:
环境:
前文已经提到过了,在 docker 虚拟的 centos7 下部署 1 pd + 1 tidb + 3 tikv 。
测试方法:
tpcc 100 warehouse,相关命令如下:
1
2
3
4
5prepare base data
./bin/go-tpc tpcc --warehouses 100 prepare
run tpcc
./bin/go-tpc tpcc --warehouses 100 run --time 3m --threads 64Profiling:
采用在 TiDB 内已经开启的 go-pprof 进行数据采集,相关命令如下:
1
2
3
4
5
6
7
8do 60 seconds profiling at tpcc prepare stage (tidb set pprof port as 10080)
curl http://127.0.0.1:10080/debug/zip\?seconds\=60 --output tpcc-w100-prepare.zip
do 60 seconds profiling at tpcc run stage
curl http://127.0.0.1:10080/debug/zip\?seconds\=60 --output tpcc-w100-run.zip
after unzip the downloaded zip package, use pprof tool to illustrate profile result
go tool pprof -http=:8080 {unziped dir}/profile
经过上述步骤,我们已经能够拿到在测试期间对 TiDB 的 CPU Profiling 数据了:
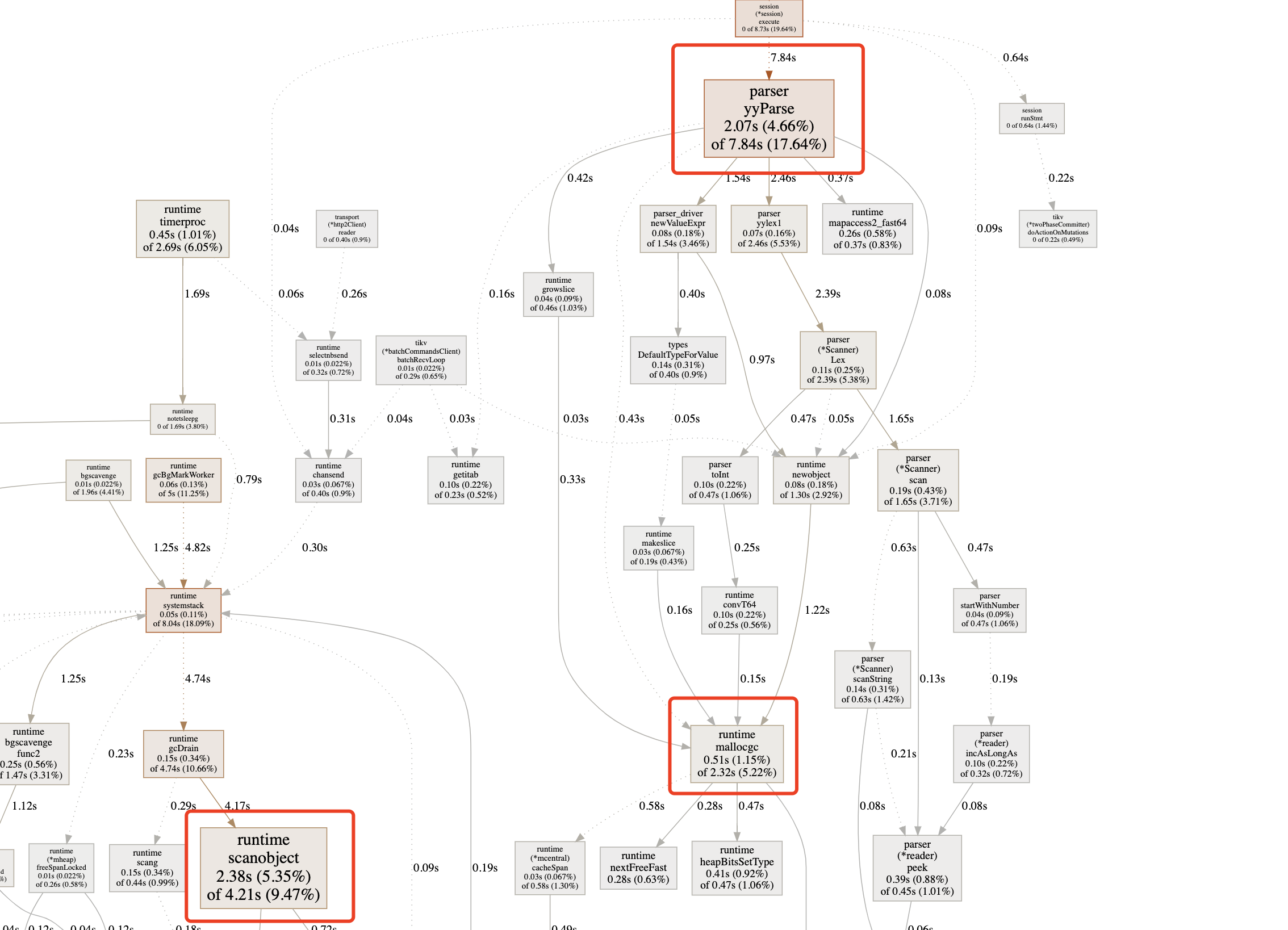
- prepare 期间的 CPU Profiling:
- run 期间的 CPU Profiling:
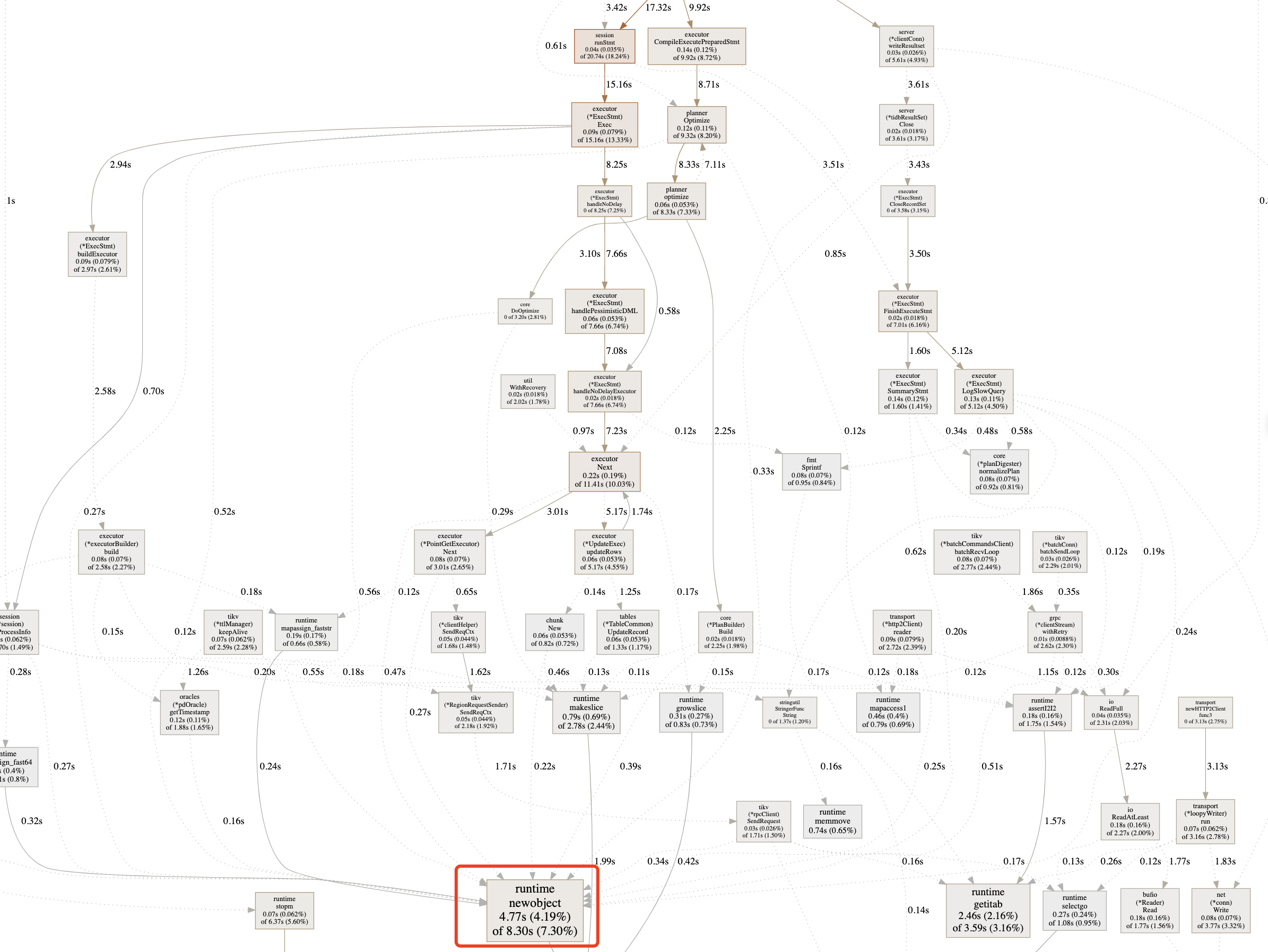
从上述结果中我们可以清晰地看出:
- prepare 阶段 Parser 的 CPU usage 占比很大
- run 阶段没有特别明显的 CPU usage 占比大的函数,其对 CPU 的消耗表现为整体平均
- 底层 gc 相关的逻辑显著的占用了 CPU 资源
性能瓶颈分析与优化建议
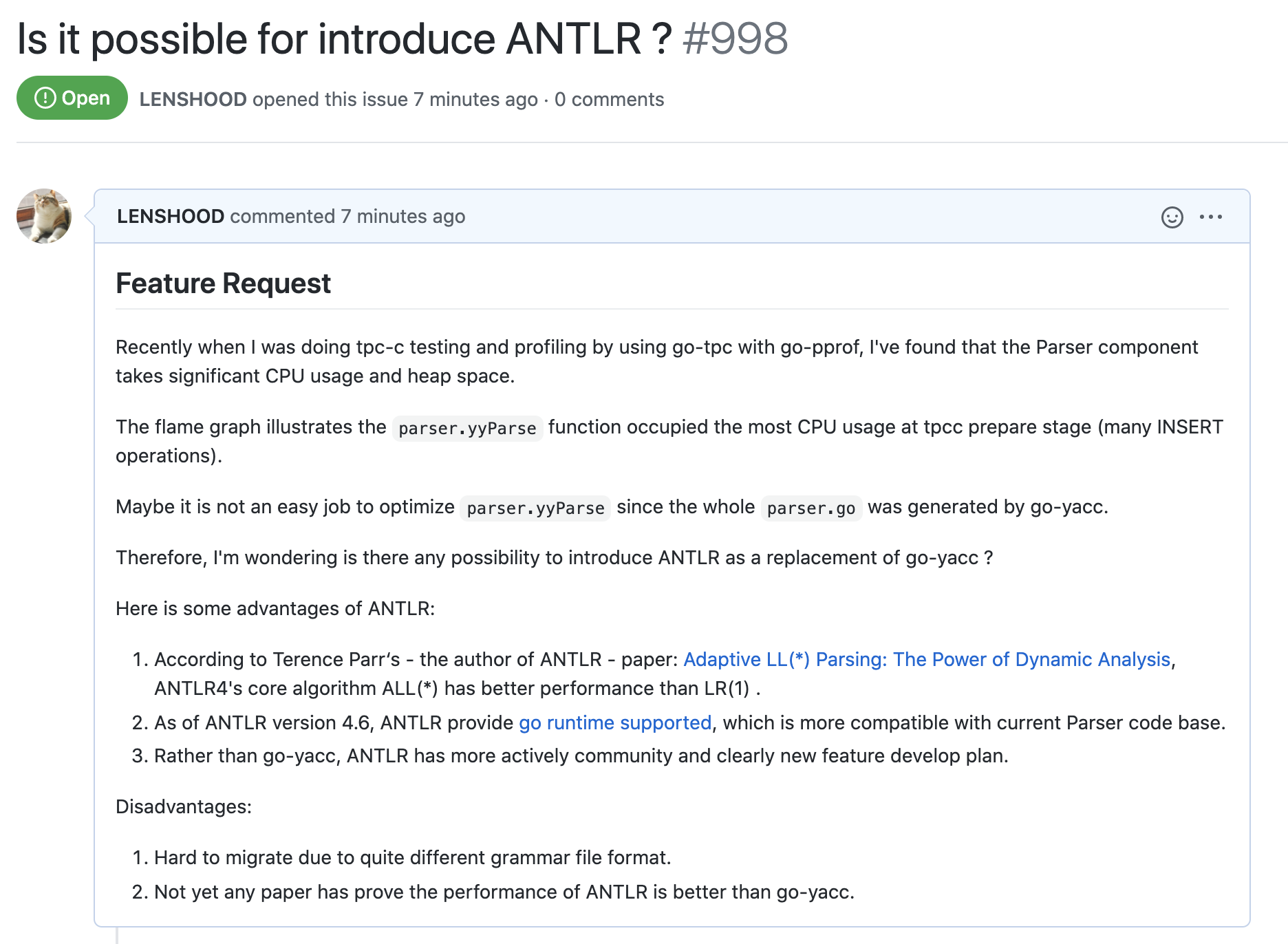
从上一节的 Profiling 结果中,我们发现,除了与 gc 相关的 go 底层逻辑 CPU 占用率很高以外,对 SQL 语句进行转换的 parser 在大量插入数据时也是一块 CPU 热点。
由于对 gc 的优化可能会横跨各个功能,需要对各种模块的实现细节有一定的理解,因此本文中我们并不会对这部分做分析,而是转为对 parser 这一较为独立的模块进行分析。
TiDB Parser
Parser 的功能边界很清晰,就是将请求中包含的字符串格式的 SQL 语句转换为符合 SQL 语言标准的 AST 抽象语法树,以便于后续对其进行校验、优化以及转化为执行计划。
目前 parser 已经被封装为模块,独立出来,名字仍旧叫做 parser。对 parser 的原理及实现进行初步的了解,可以参考TiDB SQL Parser 的实现。
简单来说,parser 采用 lex + yacc 的方式实现对 SQL
字符串的转换,其中词法分析 lex 的部分由 lexer.go
实现,用以将 SQL 字符串拆分为各种不同的 token,其中 token 定义在
parser.y 文件的第一部分中。
之后,yacc 的部分由 go-yacc 工具通过读取
parser.y 来生成 parser.go 实现。生成过程可参考
makefile 中的片段:
1 | bin/goyacc -o parser.go -p yy -t Parser parser.y # generated and printed by makefile |
parser.go 将会读取实现特定 interface 的词法分析器生成的
token,并对其进行表达式解析,最终生成 AST。
整体流程借用一张图(原图出处):
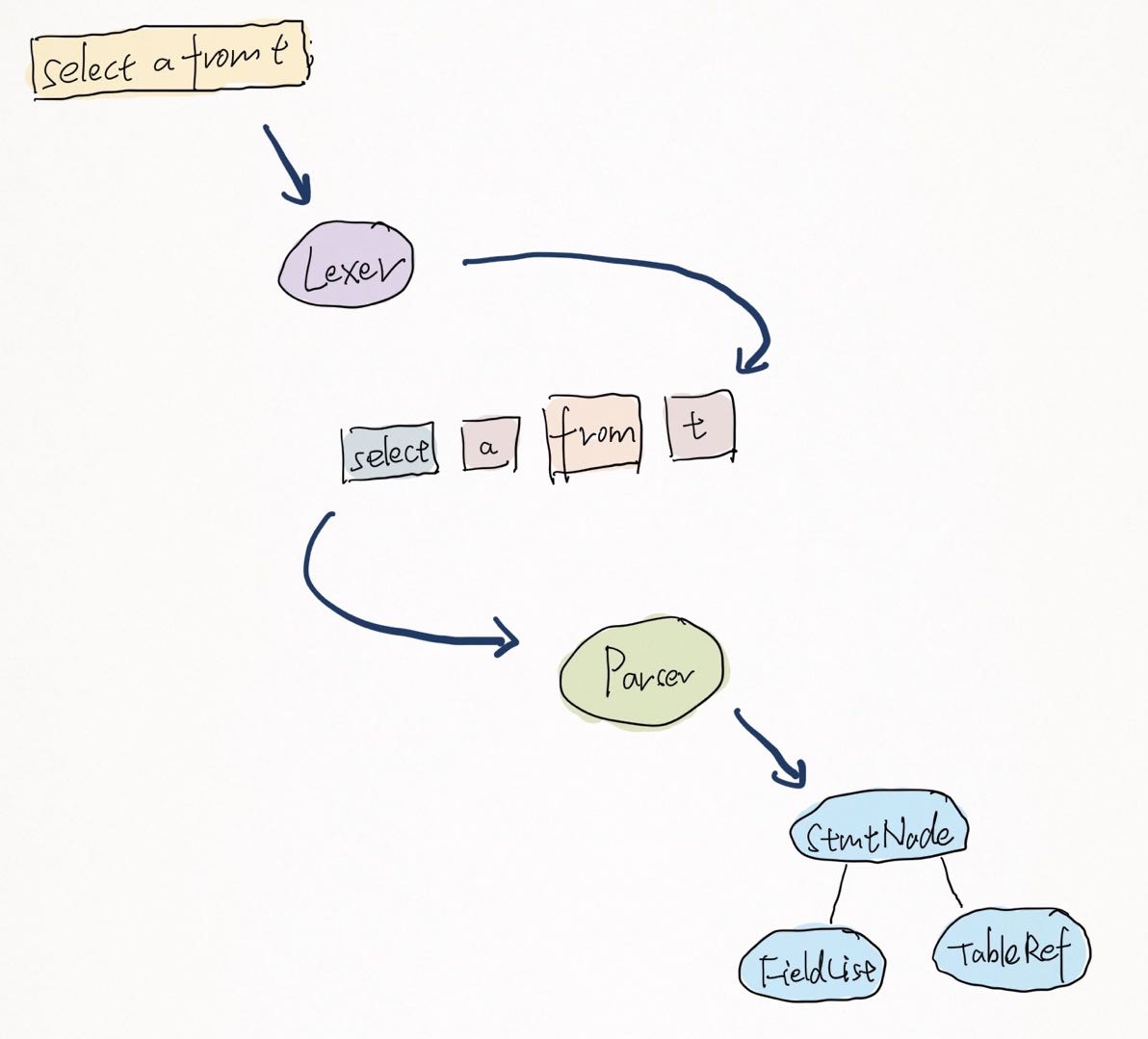
yy_parser.go 的 Parse()
方法实现了这一过程:
1 | func (parser *Parser) Parse(sql, charset, collation string) (stmt []ast.StmtNode, warns []error, err error) { |
yyParse()方法是由 goyacc
工具生成的语法解析器,而 goyacc 用 go 重写了 plan 9 开源的 c
语言实现,因此可知 goyacc 是一种 采用了 LR(1) 算法的
yacc parser。
yacc 是由 Stephen C. Johnson 在 1975 年发表的一种解析器,距离今天已有 45 年历史。
ANTLR
ANTLR 是由 Terence Parr 开发维护的一种 parser generator,相比 yacc,ANTLR 采用 Java 开发,它更年轻,作者也在持续不断的维护。ANTLR 采用了一种由作者自己对 LL 算法改进的算法: Adaptive LL(ALL(*))算法。Spark SQL 的 SQL Parser 实现就采用了 ANTLR 方案。
ANTLR 的语法分析描述文件的格式与 yacc 不同,这里引用官网的一个例子:
1 | grammar Expr; |
在上述定义下,对于表达式 100+2*34 ANTLR 会生成如下
AST:
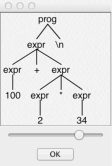
目前最新的 ANTLR 4 已经支持根据语法定义文件生成多种语言的实现,包括 Go。
ANTLR vs. yacc
通过前文,我们了解了 TiDB 目前的 parser 方案采用了 yacc,此外我们了解到一种目前很流行的新型 parser generator —— ANTLR。那么,ANTLR 相对 yacc 它的优势都有哪些呢?
参考 Why you should not use (f)lex, yacc and bison 中总结的:
- ANTLR 目前还在活跃开发期,而相比之下 yacc / bison 很稳定同时也不再有新功能的开发了
- 作为现代的 parser generator,ANTLR 的语法更强大且友好,而 yacc / bison 的语法老派且难以阅读
- ANTLR 支持各种类型的 Unicode
- ANTLR 采用 BSD 协议,而使用 GPL 协议的 Bison 放弃了大多数许可
- ANTLR 支持 EBNF
- ANTLR 支持 context-free 表达式,这能简化一些通用元素的定义
- 相比 Bison 支持两种不同扩展性与性能的算法,ANTLR 只支持一种在多数情况下性能不错的算法
- ANTLR 拥有完整的社区和文档
从上述描述,我们能发现,较为年轻的 ANTLR 相比古老的 yacc / bison,更符合现代的需求,也更易用。
不过,本文我们主要关注的是 TiDB Parser 的性能瓶颈问题,那么,假设 TiDB Parser 采用的是 ANTLR 的方案实现,其性能相比目前会怎么样呢?
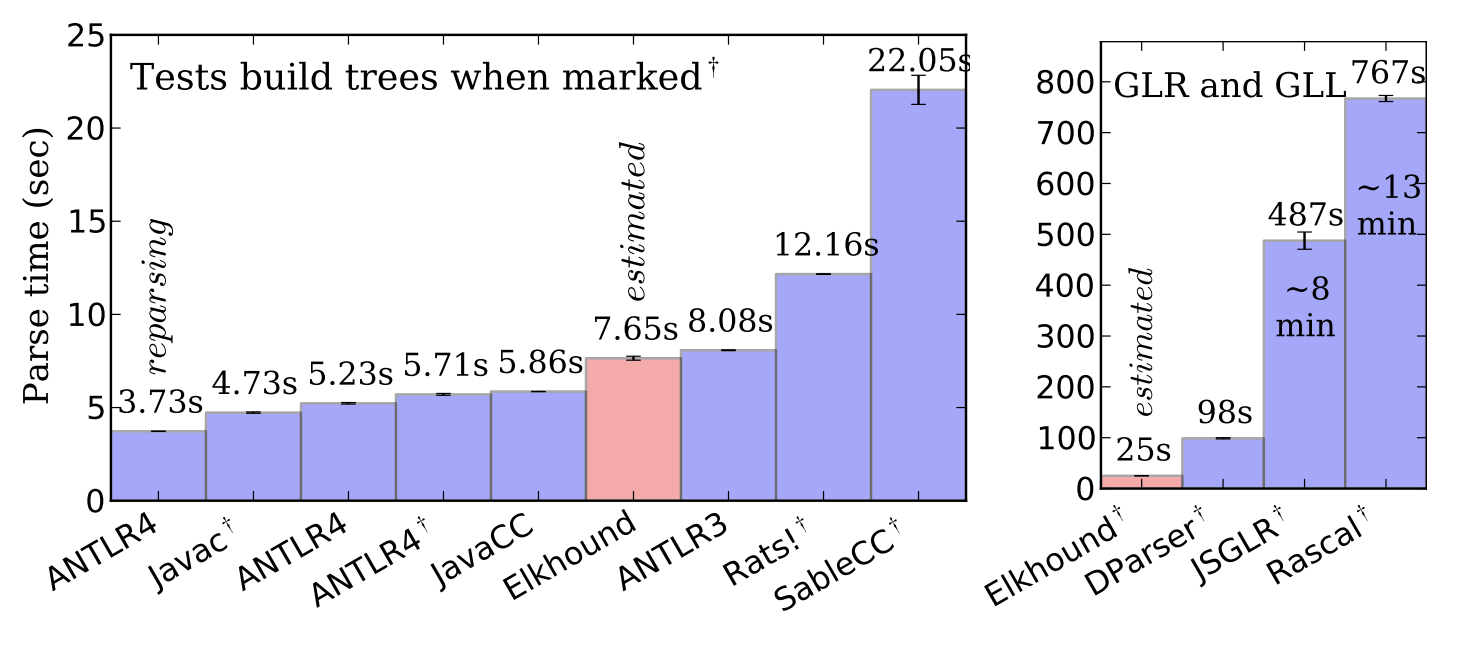
ANTLR 的作者在他的一篇论文中对包括 ALL(*) 在内的几种不同的 parser 算法的性能进行了对比分析,结果表明采用 ALL(*) 实现的 ANTLR 的性能超过实现 GLR 算法的 Elkhound 4.4 倍,超过实现 GLL 算法的 Rascal 135 倍。
而在我们关注的 LALR 算法的对比中,虽然测试结果中 ANTLR 的性能超过实现 LALR 算法的 SableCC 数十倍,但作者认为这是 SableCC 的实现问题而不是 LALR 算法的问题,实际上的 LALR 性能应该与 ALL(*) 不相上下。
作者的测试结果如下:
性能优化建议
根据前文的介绍与分析,我们也许能得出以下假设:
- 作为 SQL Parser,TiDB Parser 采用的 goyacc 方案实现比较古老,可以预见如果不做定制化的优化,goyacc 项目本身在今后应该不会有大的功能开发与性能优化。
- ANTLR 的性能理论上与实现了 LALR 算法的 goyacc 不相上下。但 ANTLR 的作者的一个 FAQ 回答 Why do we need ANTLR v4? 中,作者提到目前 ANTLR4 仍然主要聚焦在易用性而不是性能上,作者在后续会考虑优化 ANTLR 的性能,因此作为一个活跃的开源项目,ANTLR 的性能会越来越好。
- ANTLR4 目前已经支持生成 Go 语言 parser generator,更容易与 TiDB 兼容。
基于上述假设,TiDB Parser 作为从 TiDB 拆分出来的独立项目,也许可以考虑提供一个基于 ANTLR 的实现,并支持用户自定义切换,以这种方式来提升 Parser 的性能和扩展性。
本节的建议已经在 TiDB Parser 项目中提出了一个 Issue,Issue num: #998。