本次课程主要涉及 TiDB 中的 Executor 组件。
TiDB SQL 层
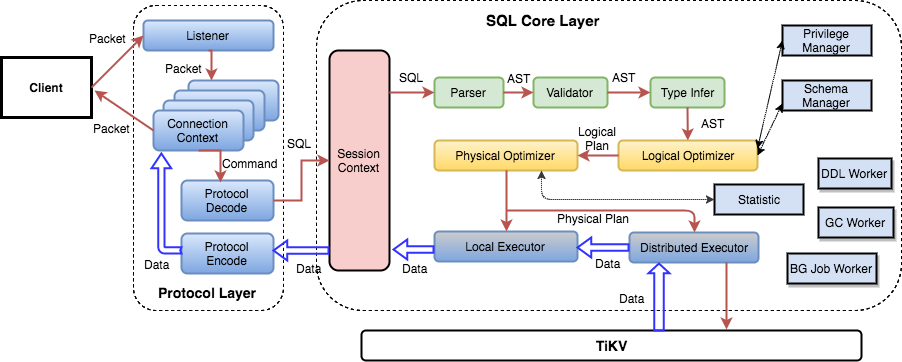
在介绍 Executor 层之前,我们先从总体上来看一看 TiDB 的 SQL
架构,这里借用一张官方博客的图 :
我们可以看到,从客户端发来的一个 SQL 请求,会先经过 Protocol Layer
进行预处理,每一个请求都转换成一个 Session Context,之后进入 SQL
层进行操作。粗略的看,我们能发现在 Executor
处,整个操作有可能会继续下探到 TiKV 层,也有可能直接由 Local Executor
返回。
仔细看 SQL
层的架构,实际上还是像一条生产线,通过对指令进行理解,来执行相应的操作。
绿色部分:从协议层解析出来的 SQL
语句,是以文本形式存在的,那么如何让程序去理解这条语句的意图、嵌套结构,以及校验语句的正确性呢?通过
Parser(实际上采用了 yacc Parser Generator 来生成复杂的转换器)将 SQL
语句转换为一颗 AST(抽象语法树),对这颗树进行分析、校验后生成一个 stmt
结构。
黄色部分:分析上述生成的
AST,并生成实际的执行计划,对该执行计划进行逻辑与物理优化,使之尽可能达到性能最优。这里生成最终的执行计划,即我们执行
Explain xxx 语句返回的执行计划了。
深蓝色部分:执行计划会被转化为具体的执行器(Executor),执行器采用了
Volcano
模型 来实现,Volcano
模型简单来讲就是一颗操作树,树的每一层都先调用下层获取数据,之后对获取到的数据进行加工后返回给上层。
所以,我们可以从 SQL
语句的复杂性与多样性来得出判断:不同的操作(DML、DQL、join、sort、aggregate、index...)会生成不同的执行计划,不同的执行计划会转化为不同的执行器,因此需要通过多样的执行器来满足多样的
SQL 操作。
Executor 的执行路径
上一节我们了解了在 SQL 层的执行路径,这一节我们一起梳理一下 Executor
的执行路径。
Executor 的所有逻辑都放置在 executor
包下,其中:adapter.go 对应了包模块的上层出入口。
adapter.go顾名思义是用于适配,它主要与执行计划交互,用于由外部调用来执行操作,并返回操作结果。adapter.go
提供了 ExecStmt 来实现构造执行器并执行,提供了
RecordSet 通过执行器获取结果集。
与下层 tikv 的交互逻辑,则散落在各种不同的 Executor 实现中。
Executor 都提供了 Open() 与 Next()
方法来实现对自身的初始化以及实际的执行。
Executor 类型
根据不同的操作,Executor 包含了很多种类,不过总体来看,所有的
Executor 都能分成两类:
需要返回结果的类型:例如各种单表、连表查询
不需要返回结果的类型:例如插入、更新等
对于不需要返回结果类型的 Executor,其 Next()
会立即执行,相关的逻辑在adapter.go的handleNoDelay()
方法中实现,参加如下代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 func (a *ExecStmt) error ) { ... e, err := a.buildExecutor() if err != nil { return nil , err } if err = e.Open(ctx); err != nil { terror.Call(e.Close) return nil , err } ... if handled, result, err := a.handleNoDelay(ctx, e, isPessimistic); handled { return result, err } ... }
而对于需要返回结果的
Executor,不会立即执行,而是会在Open()被调用后,构造一个
ResultSet
结构,包含相关上下文,最终的读取过程在conn.go 的
handleStmt() 方法中
err = cc.writeResultset(ctx, rs, false, status, 0)
这句话里实际的执行,并获取结果,参见如下代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 func (cc *clientConn) bool ) error { ... rs, err := cc.ctx.ExecuteStmt(ctx, stmt) reg.End() ... if rs != nil { ... err = cc.writeResultset(ctx, rs, false , status, 0 ) if err != nil { return err } } else { ... } return nil }
接下来会指定两个具有代表性的 Executor
来分别介绍上述两种类型的操作过程。
InsertExec 执行过程介绍
连接 TiDB 后执行:
1 2 3 4 5 6 7 8 9 10 11 > create table test ( id int primary key, name varchar (20 ) ); > explain insert into test values (1 , 'a' );+ | id | estRows | task | access object | operator info | + | Insert_1 | N/ A | root | | N/ A | +
我们可以看到对于一个最简单的插入语句,TiDB 给出的执行计划是仅使用
Insert 执行器来执行。
简单来看一看InsertExec:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 type InsertExec struct { *InsertValues OnDuplicate []*expression.Assignment evalBuffer4Dup chunk.MutRow curInsertVals chunk.MutRow row4Update []types.Datum Priority mysql.PriorityEnum } func (e *InsertExec) error { req.Reset() if len (e.children) > 0 && e.children[0 ] != nil { return insertRowsFromSelect(ctx, e) } return insertRows(ctx, e) }
具体的逻辑一部分在insert_common.go中,一部分在
insert.go 中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 func insertRows (ctx context.Context, base insertCommon) error ) { ... for i, list := range e.Lists { ... if batchInsert && e.rowCount%uint64 (batchSize) == 0 { ... if err = base.exec(ctx, rows); err != nil { return err } ... } } ... } func (e *InsertExec) error { ... if len (e.OnDuplicate) > 0 { ... } else if ignoreErr { ... } else { for i, row := range rows { ... if i%sizeHintStep == 0 { ... } else { err = e.addRecord(ctx, row) } if err != nil { return err } } } ... }
可以看到,插入操作是按批进行插入的,先准备好数据后,再调用
exec() 来执行插入动作,exec()
中的err = e.addRecord(ctx, row) 又会继续调用下层与 TiKV
交互的相关 api。
因此,从 exec()
方法的实现角度来看,每一批待插入数据,最终都是按行插入的。
TableReaderExec 执行过程介绍
1 2 3 4 5 6 7 8 9 10 11 12 > create table test ( id int primary key, name varchar (20 ) ); > explain select * from test;+ | id | estRows | task | access object | operator info | + | TableReader_5 | 10000.00 | root | | data:TableFullScan_4 | | └─TableFullScan_4 | 10000.00 | cop[tikv] | table :test | keep order :false , stats:pseudo | +
从执行计划中,我们能看到,简单的 select
语句被拆分成了两个执行步骤(关于阅读
TiDB 的执行计划 ):
TableFullScan_4 (cop task):下推到 TiKV 的全表扫描计算
TableReader_5 (root task):在 TiDB 层对子任务进行组合
所以我们来看一看 TableReaderExec的实现:
1 2 3 4 5 6 7 8 9 type TableReaderExecutor struct { ... resultHandler *tableResultHandler ... }
我们从前面的执行计划里知道,TableReader 的操作实际上是要从 TiKV
中获取下游查询结果的,实际上获取结果的动作,就是在上述结构里面的
resultHandler 中定义的。
此外,前文中我们已经提到,Executor 定义了
Open() 与 Next() 两种操作,以下便是
TableReaderExec 的实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 func (e *TableReaderExecutor) error { ... e.resultHandler = &tableResultHandler{} ... firstPartRanges, secondPartRanges := splitRanges(e.ranges, e.keepOrder, e.desc) firstResult, err := e.buildResp(ctx, firstPartRanges) ... if len (secondPartRanges) == 0 { e.resultHandler.open(nil , firstResult) return nil } var secondResult distsql.SelectResult secondResult, err = e.buildResp(ctx, secondPartRanges) ... e.resultHandler.open(firstResult, secondResult) return nil } func (e *TableReaderExecutor) error { ... if err := e.resultHandler.nextChunk(ctx, req); err != nil { e.feedback.Invalidate() return err } ... }
整个 select 的逻辑,实际上是划分在上面这两部分的。
首先,Open()
会先被执行,在该方法内我们看到,firstResult, err := e.buildResp(ctx, firstPartRanges)
构造了一个下推查询任务(后文会涉及),之后将该返回值作为参数传入了
resultHandler.open()(所谓 firstPartRanges 与
secondPartRanges 是被拆开的两部分分区,基于我们当前的查询,只会使用到
firstPartRanges,secondPaartRanges 为 nil)。
我们一起来看一看 buildResp() 的实现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 func (e *TableReaderExecutor) error ) { ... result, err := e.SelectResult(ctx, e.ctx, kvReq, retTypes(e), e.feedback, getPhysicalPlanIDs(e.plans), e.id) ... return result, nil } func (sr selectResultHook) fieldTypes []*types.FieldType, fb *statistics.QueryFeedback, copPlanIDs []int , rootPlanID int ) (distsql.SelectResult, error ) { if sr.selectResultFunc == nil { return distsql.SelectWithRuntimeStats(ctx, sctx, kvReq, fieldTypes, fb, copPlanIDs, rootPlanID) } return sr.selectResultFunc(ctx, sctx, kvReq, fieldTypes, fb, copPlanIDs) } type selectResult struct { ... resp kv.Response ... } type Response interface { Next(ctx context.Context) (resultSubset ResultSubset, err error ) Close() error }
从以上代码中我们能得出:
实际上在 Open() 阶段就已经通过 distsql
向下游 TiKV 分发了查询任务
在 distsql 返回的 selectResult
中,可以通过 resp 来获得返回值
至此整个
Open()的流程介绍完毕了。我们可能会有一些疑问:
Open() 仅仅是通过 buildResp()
拿到了selectResult,但并没有调用
resp.Next()来获得结果,那么,
实际上获取结果的逻辑,是在上文中提到的
handleNoDelay()中完成的吗?
实际上不是的,在前文我们还提到了:对于有返回结果的
Executor,其结果的获取,在
err = cc.writeResultset(ctx, rs, false, status, 0)
中完成,现在我们来看一看:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 func (cc *clientConn) bool , serverStatus uint16 , fetchSize int ) (runErr error ) { ... var err error if mysql.HasCursorExistsFlag(serverStatus) { err = cc.writeChunksWithFetchSize(ctx, rs, serverStatus, fetchSize) } else { err = cc.writeChunks(ctx, rs, binary, serverStatus) } ... return cc.flush(ctx) } func (cc *clientConn) bool , serverStatus uint16 ) error { ... for { err := rs.Next(ctx, req) ... for i := 0 ; i < rowCount; i++ { data = data[0 :4 ] if binary { data, err = dumpBinaryRow(data, rs.Columns(), req.GetRow(i)) } else { data, err = dumpTextRow(data, rs.Columns(), req.GetRow(i)) } ... if err = cc.writePacket(data); err != nil { reg.End() return err } } reg.End() ... } return cc.writeEOF(serverStatus) }
关键行就是err := rs.Next(ctx, req),该语句中,ResultSet
的Next() 最终会调用
TableReaderExec.Next()来获取数据,并放入 req
中(req 是 ResultSet 中存放的一个
Chunk 结构)。
结尾
前文讲解了最基本的两种 Executor
的实现逻辑,除此之外,一些较为复杂的操作,如 Join,Aggregation
等都会通过类似的过程来完成执行,只不过嵌套更深,逻辑更复杂。
){kind=link}