TiDB 学习课程 Lesson-5
这一节,我们涉及的知识是 TiDB 如何实现 DDL。
TiDB DDL 工作原理
我们知道,TiDB 的元信息,与数据一样是以 k-v 的形式存储在 TiKV 的,DDL 操作,包括了对元数据本身的修改,以及必要时对相关数据的修改。
那么作为一个多实例分布式部署形态的数据集群,TiDB 是如何完成 DDL 操作的呢?他又是如何避免多实例之间不一致的问题呢?TiDB 在 DDL 期间,会像 MySQL 一样产生锁表的动作吗?
我们来一一解答上述问题。
任务分发模型
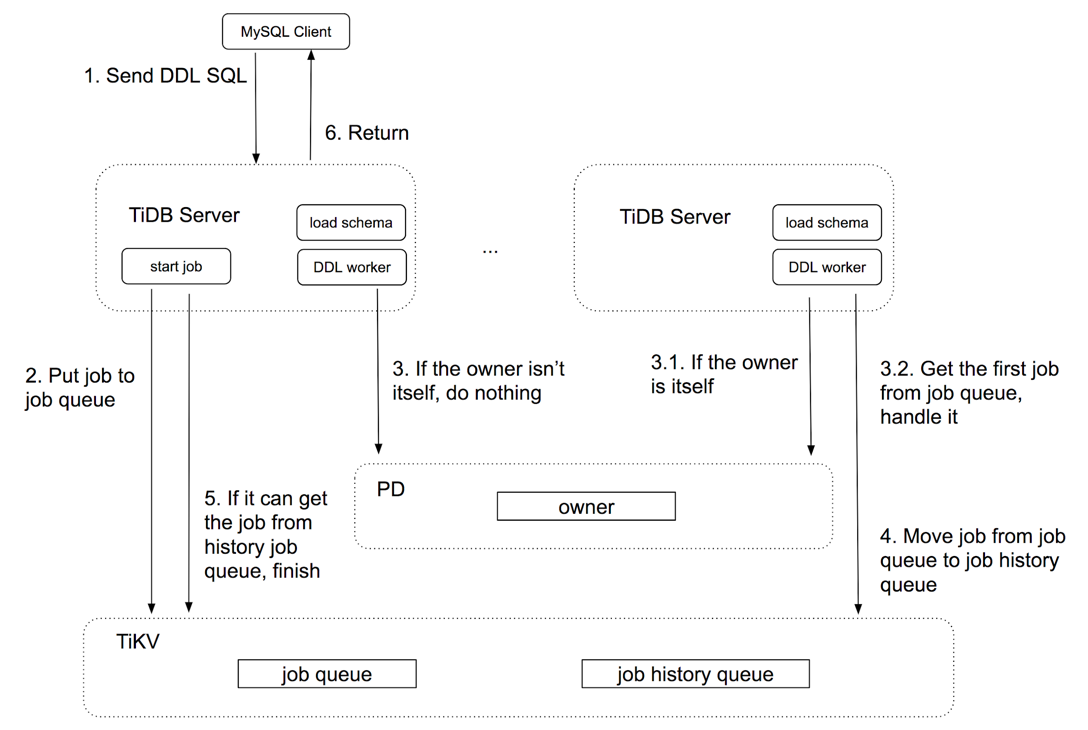
由于 TiDB 本身是无状态的服务,用户的 DDL 请求,可能会发送到任意一个 TiDB 实例上,进而要求对基于元数据考虑分布式一致性问题。为了简化实现,TiDB 采用了 owner 的概念,即每个集群内只有一个实例作为 DDL owner 来真正的执行 DDL 任务,而不论哪个实例接收到 DDL 请求,最终该 DDL 任务的实际执行都会被分发给 owner。
为了实现这一目标,TiDB 的 DDL 操作采用了基于 worker 的任务分发模型实现上述要求。
简单来说,一个 DDL 被处理的流程如下:
- TiDB 接收到 DDL 请求,将该请求解析并封装为一个 DDL job,扔进 ddl job queue(该队列放在 TiKV)
- 每一个 TiDB 实例都会启动一个 worker goroutine,用来从 ddl job queue 中领取任务来执行。但注意前文的要求是只有 owner 才能执行任务,因此 worker 会判断自己所在的实例是否是 owner,如果不是则不会领取任务。当 owner worker 执行完任务后,将执行结果扔进 history ddl job queue(该队列放在 TiKV)
- 发起 DDL 任务的 TiDB 实例会持续等待 history ddl job queue 中返回对应的 job,获取成功后整个 ddl 操作结束。
根据上述描述,一切 DDL 操作都会遵循该流程来执行,这种方式实现了在线无锁 DDL。
下图是 TiDB 官方博客中提供的关于 DDL 执行过程的示意图:
异步 Schema 变更原理
TiDB 的 Scheme 变更过程,借鉴了 Google F1 的异步 Schema 变更算法。
实际上 TiDB 的设计基础本身就是基于 Google 的 Spanner / F1,在 F1 的 Schema 变更论文摘要中就已经提到,他的算法:
- asynchronous—it allows different servers in the database system to transition to a new schema at different times
- online—all servers can access and update all data during a schema change.
这种算法不仅不要求各节点 Schema 的状态保持一致,还实现了 Schema 变更完全的无锁,我们可以一边更新数据,一边更新数据表。
我们可以想一想,对于 TiDB 这种分布式数据库,如果期望实现简单的同步带锁的 Schema 变更,似乎也不那么容易:
- TiDB 节点本身无状态,且没有一个地方可以保存所有节点列表的最新状态(这本身就需要同步),那么想要让所有节点的 Schema 在同一时刻变更到新的状态就会非常复杂,且不可靠。
- 由于节点众多,时间不统一,数据规模庞大等等多种因素,Schema 变更的时间可能不会太快,如果在此期间与对应表相关的 DML/DQL 不可用,那么将极大地影响正常业务(MySQL 5.6 以后也引入了 Online DDL 来在绝大多数 DDL 场景下保证业务连续性)
那么既然客观条件要求 Schema 变更期间数据可用,同时无法实现状态同步变更,那么异步无锁的 Schema 变更策略就是唯一的选择了。
异步变更存在的问题
从上文中我们已经知道,很难保证所有 TiDB 节点暂存的 Schema 信息都是最新状态的,那么异步变更时就会存在问题:
假如有 A/B/C 三个 TiDB 节点,目前对 table t 增加了一列 c,且当前 A/B 节点都已经更新的该状态,即表 t 包含了列 c,那么业务方此时就可能在 insert t 的时候,加上 c 相关的信息,例如:
insert into t (c) values('c-value')
假如该语句被定向到节点 C 时,就会产生错误,因为 C 并不知道表 t 中已经包含了 c 列,这就产生了数据的插入失败。
类似的,当我们进行添加索引操作时,假如部分节点已经获知索引的信息,而另一部分并未获知,则索引列就很可能产生有的值有索引,有的值没有索引的情况。
状态拆分解决不一致问题
既然我们无法确保所有节点在同一时刻达到统一状态,那么有没有一个折中的办法,允许状态不一致的情况暂时存在,并且最终达到一致呢?
F1 引入了中间状态的概念,仍旧以添加列为例:
直接状态变更:
original ---> column added
中间状态变更:
original ---> column added but not valid ---> column added
对于中间状态变更,我们只要保证,同一时刻所有的节点只能处于两个相邻状态中的一个,例如:
- A/B/C 三个节点,A/B 节点处于初始状态,C 节点已经变更,进入中间状态,column 已经增加,但不发布。
- 此时,即使 C 节点已经先添加了列,但并没有发布,从外部看,表仍然是原来的样子,因此所有包含新列的 insert 语句都会报错
- A/B 节点逐步到达中间状态,此时 C 节点进入最终态,增加 column 的状态被发布出来。
- 此时,对于 insert 语句中包含新列的请求,如果进入 C 节点,一切按照正常流程,而如果进入 A/B 节点,则由于 A/B 也已经存在新列,因此 insert 语句也可以成功
- 最后 A/B/C 都达到终态
我们看到,采用这种方式就可以逐步地让整个集群的状态趋于一致。那么如何确保,同一时刻只有两种状态可以共存呢?
在 F1 中,采用 租约(lease) 来实现,租约本身有时间限制,节点会强制在租约到期后重新加载 Schema。这种方式是采用宽松的时间段来规避了各节点时间不统一的问题。
假设节点的Schema 租约时间是 30s,A/B/C 节点的本地时间分别有 5s 的延迟误差,因此,A 节点首先刷新租约进入中间状态,5 秒后 B 节点进入,再 5 秒后 C 节点进入,这样就保证了同一时刻只有两个 Schema 状态可以同时存在。另外我们也能看到,假如节点间的时间误差大于租约期时,就可能破坏我们的预期(因此我们可以通过提升时间精度的办法来降低租约期,提升 DDL 速度)。
真实示例
显然,很多 DDL 操作可能会比较复杂,因此实际中,仅有一个中间状态是不现实的,通常至少会有两个中间状态:
- write only:变更的 schema 元素仅对写操作有效,读操作不生效
- delete only:变更的 schema 元素仅对删除操作有效,读操作不生效
那么实际的添加 column 操作中,状态变更流程是这样的:
1 | absent --> delete only --> write only --(reorg)--> public |
其中,reorg 不指代一个状态而是在 write only
状态后,需要做的一系列操作,例如对所有现存数据增加索引,增加默认值等等。
而对于删除列,则正好相反:
1 | public --> write only --> delete only --(reorg)--> absent |
- public:能够对该列数据进行读写
- write only:列数据不可读,只可写,确保写操作正常进行(此时仍存在 public 节点,因此写操作仍然需要支持,删除操作会被忽略)
- delete only:列数据不可读,只可删除,处于该状态的节点,已经不会再有任何被删除列上的新数据被插入了。
- reorg:此时可以开始逐步删除列上数据,就算有节点处于 delete only 状态,且成功删除了列上的数据,reorg 时只需要忽略删除失败的行即可。
- absent:最终状态
TiDB DDL 实现
TiDB DDL 的实现主要在 ddl.go 、
ddl_api.go、ddl_worker.go、syncer.go
几个文件中。
首先,根据 TiDB 的设计架构,DDL 操作首先会被封装为一个
DDLExec 的 Executor,作为执行器来执行。在
DDLExec.Next() 方法中,根据不同的 DDL
操作,执行路径被分发到不同的逻辑中(实际上调用了 ddl 的逻辑):
1 | // executor/ddl.go |
以 Alter Table XXX Modify XXX 的操作为例,在
ddl_api.go 的实现如下:
1 | ... ... |
首先通过 getModifiableColumnJob 构造对应的 ddl
job,之后通过 doDDLJob 执行任务。
结合 doDDLJob 的逻辑:
1 | func (d *ddl) doDDLJob(ctx sessionctx.Context, job *model.Job) error { |
首先将 job 封装为 task 塞入
limitJobCh 中,之后 asyncNotifyWorker() 提醒
ddlWorker 有任务塞入,最后通过 getHistoryDDLJob(jobID)
轮询已完成的任务,获取当前任务的执行状态。
因此,对于 DDL
任务的发起方而言,它只需要将任务发出,并等待最终的执行结果即可,实际的工作,都是由
worker 来完成的。
DDL 初始化
在 domain 初始化时,ddl
被初始化,整个初始化动作,主要包含三部分:
- 启动一个 go-routine 来执行向 tikv 任务队列中塞入任务的工作
- 创建 worker 并在 go-routine 中启动
- 启动一个 go-routine 来清理过期的 Schema 信息(当超过租约期仍未更新时)
对于将任务塞入队列的操作,大致实现如下:
1 | func (d *ddl) addBatchDDLJobs(tasks []*limitJobTask) { |
EnQueueDDLJob 最终会调用底层的 kv
方法,而实际上任务队列是储存在 tikv 中的一个 list。
在第二步,会创建两个 worker:general worker 和 add index
worker,其中 add index worker 专职于添加索引动作,其余动作都由 general
worker 来执行(这是为了防止添加索引可能的长时间执行会阻塞到其他 ddl
操作)。
worker 在被创建之后,由 ddl 初始化逻辑分别在独立的 go-routine 中启动。
###DDL Worker
有关 workder 的代码,都放在 ddl_worker.go
中。
1 | func (w *worker) start(d *ddlCtx) { |
可以看到,worker 实际上同时接收 ticker 和
ddlJobCh
的信号,不论是到达检查时间,还是被通知有新任务到来,worker
都会开始handleDDLJobQueue()。
1 | func (w *worker) handleDDLJobQueue(d *ddlCtx) error { |
具体的执行中,首先获取队列中第一个任务,然后执行runDDLJob(),完成后执行updateDDLJob()更新
job 的状态(参考前述的中间状态变化),在下一次循环中,如果 job
已经结束,则执行finishDDLJob() 将任务放入 history
队列。
runDDLJob()中实现了47 种 DDL
任务的执行过程,由于篇幅原因,不再详述。
in place / instant
在目前的 DDL 任务中,根据其执行时间的不同,将所有 DDL 任务分成了两类:
- in place:执行时间长、执行速度慢,如 add index 操作
- instant:执行时间短、执行速度快,如 add column 操作
之所以分为两类,是由于 TiDB 的 DDL 机制限制:前文提到过,TiDB
为了简化 DDL 的操作,实际上不论有多少个节点,只有一个 owner
节点才能处理 DDL,其他节点只接受 DDL 请求,并将实际任务转发给
owner 来执行。
那么就会存在一个问题,只有一个 owner,相当于所有 DDL
任务是串行执行的,对于通常的 DDL 比如建表、增加列、删除 schema
等操作,速度很快,串行执行没有任何问题,然而对于例如添加索引这种操作,每一条记录都要添加对应的索引,一旦遇到大表,就会明显的阻塞其他
DDL 请求。
为了解决这一问题,TiDB 专门将原先的模式进行改造,再目前现有的 DDL
任务队列基础上,单独增加了一个队列,专门用于存放各种添加索引任务。同时,在
DDL 初始化时,也专门增加了一个
worker,专门处理添加索引任务。这样就解决了 in place
任务阻塞 instant
任务的情况(实际上目前删除带有组合索引的列以及修改列数据类型的
DDL 任务同样执行时间很久,这些任务也会阻塞其他任务,Issue19397正在讨论如何处理这一情况)。
由于增加了一个
worker,原本的串行执行变成了部分并行,那么就会存在先添加列,之后给新添加的列添加索引时,由于添加的列还在排队,导致添加索引操作失败的现象。解决这一问题的方法,TiDB
是通过任务依赖的方式:对于同一张表,不论是 in place 还是
instant,标号较大的 job 会依赖标号较小的 job。