TiDB 学习课程 Lesson-7
本节课程主要学习的是 TiDB 的 事务原理。由于 TiDB 的分布式部署的特性,其事务的实现主要借鉴了 Percolator 中分布式事务的实现方式,将 TiDB 与 TiKV 结合起来,共同完成分布式事务的任务。
本文中涉及到的图片来源,都来自 PingCAP 官方网站。
TiDB 事务
我们已经知道,TiKV 基于 k-v 实现了数据的存储,MVCC 层暴露了带版本的 k-v 的操作。而在 MVCC 层以下对每一个 kv pair 的一致性复制,采用 raft 实现。
所以,当一组操作涉及到了对多个 kv pair 的读写时,就需要采用事务来确保这组操作的完整性。另外需要注意的是,被操作数据很有可能分布在多个 TiKV 节点上,那么就要求事务是分布式事务,能够确保跨节点操作的一致性。
kv pair 之间的事务
设想假如只有单个 TiKV 节点,一组操作中涉及到的所有数据都限定在单节点中,那么事物的实现就可以简化对每一个涉及到的 kv pair 进行加锁,处理完之后,在提交时统一解锁就可以了。
扩展到分布式事务场景下,实际上我们也可以照搬加锁后提交的逻辑过程,只是在分布的节点中可能遇到许多不可控的因素来打破我们提交流程:
- 由于网络通信的原因,导致一部分 key 提交成功,一部分 key 没收到提交请求
- 由于不满足约束条件,导致满足约束的节点提交成功,而不满足约束条件的节点提交失败
- 由于节点故障,某个节点失去响应,导致涉及到该节点的数据提交失败
一旦发生上述情况,就会导致事务内的数据出现了部分提交,破坏了一致性。
由于我们无法确保上述现象一定不会发生,那么就只能加固提交的过程来规避这些问题。
既然部分 key 有可能因为种种原因无法成功提交,那么不如这样:
- 大家都先不要提交,而是增加一个准备阶段,发起者向每个节点发送准备请求,要求节点准备好要提交的数据,并等待发号施令
- 所有节点准备好数据后,都回复发起者说,我这里一切就绪了。假如在这一阶段发生了上述的问题,那么因为所有数据都还没有被提交,因此就不会破坏一致性
- 发起者汇总了大家都准备好的信息后,一声令下,全都提交,这时所有节点都在收到命令后开始提交流程。
假如在提交阶段发生了上述问题,那么相应的节点会尽最大努力尝试提交。例如某节点在准备完成后,一直没有收到提交命令,此时他可能会采取继续等待,或与其他节点沟通等等策略。而由于不论是发起者发送请求之前,还是节点接收到请求之后,都会先记录日志(WAF),因此假如在提交过程中宕机,恢复后可以继续执行原来的操作。
以上的事务提交方式就是常见的 2PC 即两阶段提交。
Percolator 事务
前面讲到了在处理跨 key 之间事务一致性时使用的 2PC 事务实现方式。在 Google 的 Percolator 中,也遇到了同样的问题,并且他们正是采用了 2PC 来实现事务。这一节会介绍 Percolator 的 2PC 实现。
Percolator 是 Google 构建的一个专门用于对巨大的数据集进行增量更新的系统,Google 用它来更新其搜索引擎索引。Google 的搜索引擎索引数据有数十 PB 的数据,他们存放在 BigTable 上。BigTable 作为能提供单行事务的表存储系统,无法满足多行修改的事务一致性,Percolator 以如下的方式,实现了基于 BigTable 的多行事务,它保证事务之间能提供 SI 的隔离级别(以下内容整理自 DeepDive TiKV 对 Percolator 的讲解):
- Percolator 的每一个逻辑列,都映射到 BigTable 上的五个物理列:
- lock:锁记录,用于指示当前版本数据是否上锁,无论版本,一行数据至多只能存在一个锁
- write:用于引用一条已经成功被事务写入的数据
- data:实际数据,以多版本存储,形式类似
v:data - notify:用于表明改行已经被修改,也可以作为用户自定义的 observer 的触发器,触发进行定制化的操作
- ack_0:用于保存 observer 最后一次操作的时间戳,防止一次数据变动被错误的 notify 两次
- 通过一个全局时钟服务 TSO(Timestamp Oracle)来提供单调递增的时钟。所有读写之前都需要通过 TSO 获取最新的时间戳。
假如我们暂时不考虑 notify 和 ack_0
列(由于分布式事务的逻辑部分与对 observer 的触发关系不大),那么
Percolator 中的某一条数据可以被展示为如下的结构:
| key | v:data | v:lock | v:write |
|---|---|---|---|
| k1 | 14:“value2" | 14:primary | 14: |
| 12: | 12: | 12:data@10 | |
| 10:“value1” | 10: | 10: |
我们发现,对于 k1 这一行数据,从 v:data
来看,时间戳版本为 10 的数据是 “value1”,并且结合v:write 在
12: data@10 来看,时间戳版本为 10
的数据已经被提交,其提交记录就是
12: data@10。那么同样的,我们也可以得知,14: “value2"
这条数据是最新且未提交的数据,因为还没有任何一个 v:write
引用向它,且在v:lock 列存在一个锁。
写操作
由于 Percolator 也采用 2PC 来进行事务操作,因此事务写的动作一样被分为两个阶段:Prewrite 和 Commit。
在 Prewrite 阶段:
- 从 TSO
获取最新的时间戳,作为事务开始的时间点:
start_ts。 - 将事务涉及到的每一行数据以
start_ts作为版本号写入对应列中,同时在v:lock列写入一个锁。其中,任选一行数据作为主行(primary),其锁的内容为start_ts: primary,而其余行作为附属行(secondary),其锁内容为start_ts: primary@primary_key。 - 假如在这一阶段中发现任意行存在比
start_ts还要新的行或该行已经上锁,则准备失败,当前事务回滚(显然是一个乐观的事务机制)。
在 Commit 阶段:
- 在 TSO
获取新的时间戳,作为事务提交的时间点:
commit_ts。 - 移除 primary 锁的同时在
v:write列中写入一条数据:commit_ts: data@start_ts(BigTable 单行事务),假如此时 primary 锁并不存在,则提交失败。 - 对其他的附属行也执行类似 2 的动作。实际上只要 2 执行成功,Percolator 就认为整个事务已经成功提交,其附属行的操作可以异步化以提升性能(在后面读的过程中采用额外的逻辑来保证事务数据的一致性,详见下文)
举例说明,假设我们在一个事务内修改两条记录,这两条记录的初始状态如下:
| key | bal:data | bal:lock | bal:write |
|---|---|---|---|
| Bob | 6: | 6: | 6:data@5 |
| 5:$10 | 5: | 5: | |
| Joe | 6: | 6: | 6:data@5 |
| 5:$2 | 5: | 5: |
现在 Bob 想要给 Joe 转 $7,那么在 Prewrite 成功后的状态如下:
| key | bal:data | bal:lock | bal:write |
|---|---|---|---|
| Bob | 7:$3 | 7:primary | 7: |
| 6: | 6: | 6:data@5 | |
| 5:$10 | 5: | 5: | |
| Joe | 7:$9 | 7:primay@Bob.bal | 7: |
| 6: | 6: | 6:data@5 | |
| 5:$2 | 5: | 5: |
而当 Commit primary 成功后,状态如下,此时事务已经成功提交:
| key | bal:data | bal:lock | bal:write |
|---|---|---|---|
| Bob | 8: | 8: | 8:data@7 |
| 7:$3 | 7: | 7: | |
| 6: | 6: | 6:data@5 | |
| 5:$10 | 5: | 5: | |
| Joe | 7:$9 | 7:primay@Bob.bal | 7: |
| 6: | 6: | 6:data@5 | |
| 5:$2 | 5: | 5: |
最后,附属列异步执行完成后:
| key | bal:data | bal:lock | bal:write |
|---|---|---|---|
| Bob | 8: | 8: | 8:data@7 |
| 7:$3 | 7: | 7: | |
| 6: | 6: | 6:data@5 | |
| 5:$10 | 5: | 5: | |
| Joe | 8: | 8: | 8:data@7 |
| 7:$9 | 7: | 7: | |
| 6: | 6: | 6:data@5 | |
| 5:$2 | 5: | 5: |
读操作
读操作的执行过程比较简单:
- 从 TSO 获取时间戳
ts。 - 判断在
[0, ts]之间的记录中是否存在锁- 假如存在锁,代表当前存在一个比
ts更早的写事务正在这一行中执行。我们并不清楚这个事务到底会在ts之前还是之后提交,因此本次读操作会终止并重试。 - 假如不存在锁,或锁的版本高于
ts,则可以继续进行读操作。
- 假如存在锁,代表当前存在一个比
- 从
write列选取commit_ts处于[0, ts]范围内最近的记录,该记录中保存了对应事务的start_ts。 - 根据
write列中取出的start_ts找到data列中对应的记录,取出数据。
仍旧延续上述转账的例子,假设我们想要在如下状态中读取 Bob 的余额:
| key | bal:data | bal:lock | bal:write |
|---|---|---|---|
| Bob | 8: | 8: | 8:data@7 |
| 7:$3 | 7: | 7: | |
| 6: | 6: | 6:data@5 | |
| 5:$10 | 5: | 5: | |
| Joe | 7:$9 | 7:primay@Bob.bal | 7: |
| 6: | 6: | 6:data@5 | |
| 5:$2 | 5: | 5: |
- 获取当前时间戳,假设是
9。 - 显然,Bob 的记录中不存在锁,继续读取。
[0, 9]中最大的write记录为8:data@7,即commit_ts = 8, start_ts = 7。- 根据
start_ts = 7取得时间戳为7的数据:$3。
这种读取方法同时提供了无锁读和历史读。在上述例子中,假如我们想要读取
[0, 8] 之间的 Bob 余额,最终就会得到 $10。
处理冲突
通过检查 lock
列来判断冲突。一行数据可以拥有多个版本,但至多只能拥有一个锁。当我们执行一个写操作时,我们会在
Prewrite
阶段给所有涉及到的行加锁。假如其中小部分行加锁失败,整个事务都会被回滚。使用这种乐观事务算法,有时
Percolator 的事务写入性能会在冲突频繁的场景下发生退化。
当需要回滚时,我们只需要删除锁和对应版本的数据即可。
故障容错
Percolator 能够在不破坏数据完整性的情况下从故障中恢复,也正因为如此,对于附属列的写操作可以放心的异步执行。
系统可能会在 Prewrite、Commit 或二者之间发生故障。我们可以简单的将这些故障分为两种:Commit 前故障和 Commit 后故障。
假设当前有一个事务 T1
(读或写事务均可)在执行过程中发现在其期望读取的行 R1
中存在一个比 T1 更早的事务 T0 留下的锁。此时
T1 不会立即回滚,而是先检查 T0 的 primary lock
的情况:
- 假如 primary lock 已经不存在,并且在对应记录的
write列上发现有一条data @ T0.start_ts的记录。那么显然T0已经成功提交,R1作为T0的附属列,其遗留的锁可以被一并提交。在提交后,T1就能继续执行,这种操作称之为rolling forward。 - 假如 primary lock 已经不存在,并且没发现其他的更新,这证明
T0已经被回滚。那么R1上遗留的锁也应该被一并回滚。在回滚后,T1仍可继续。 - 假如 primary lock
存在,但却太旧了(可以设定一个阈值来判断是否过旧),这说明
T0在其提交或回滚之前系统就崩溃了。这时将T1回滚,驱使T0继续。 - 除以上之外的情况,我们都认为
T0还在进行中。那么T1既可以回滚,也可以等待一会儿后重试并检查T0是否会在T1.start_ts之前提交(如果在之后提交,则T1读不到最新数据,必须回滚)。
乐观事务实现
TiDB 的乐观事务基本上是基于 Percolator 的事务模型来实现的,其基本原理完全一致,在具体的实现细节上做了许多优化。
总体上可以由下图来描绘 TiDB 中执行一次完整的乐观事务的过程(图源):
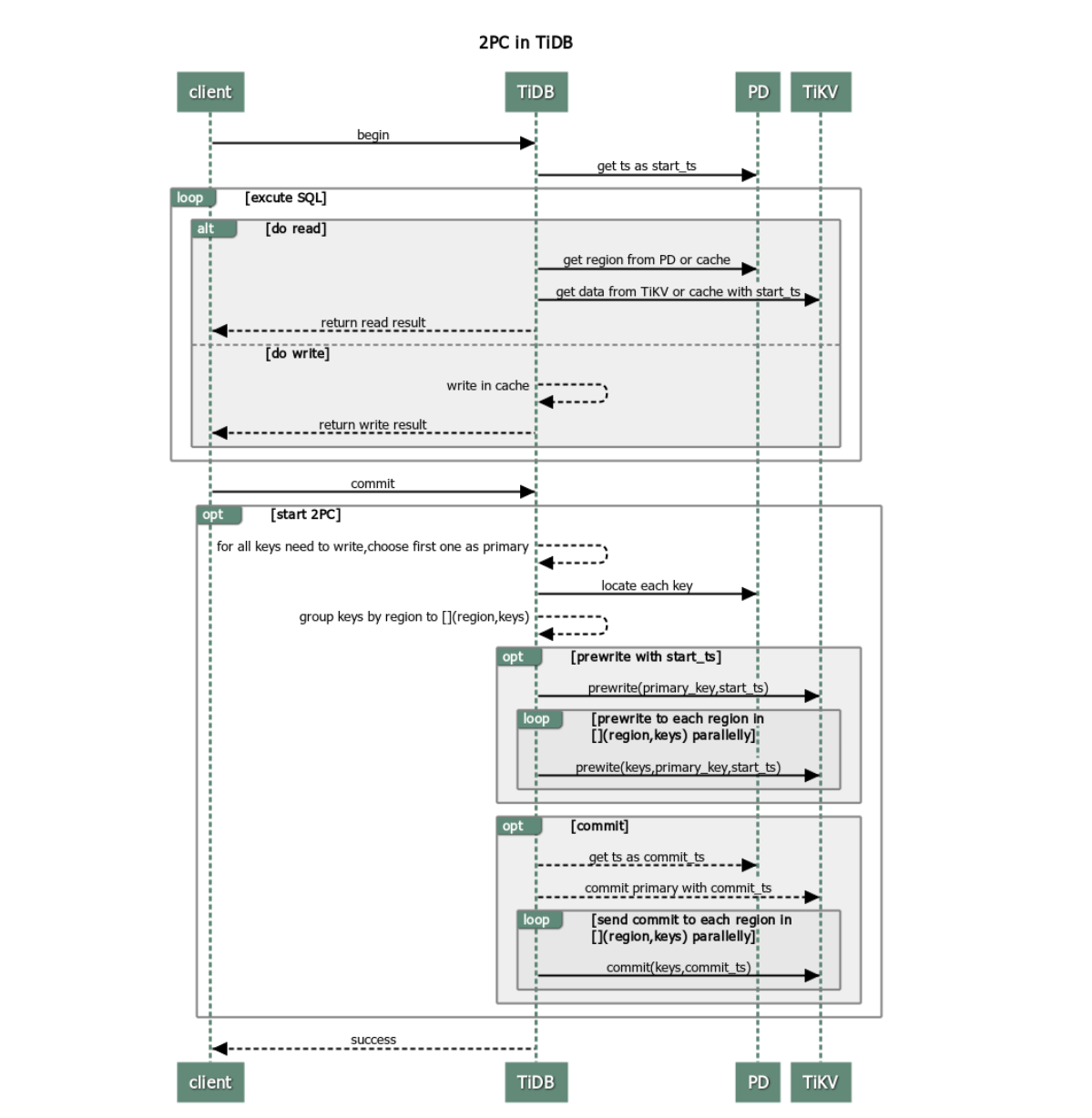
从上图所见,一个完整个 TiDB 事务,需要涉及到 TiDB PD TiKV 三部分,其中,TiDB 一端与 client 交互,进行开启、提交事务;一端与 PD 交互,获得时间戳与数据所在 region 信息;一端与 TiKV 交互,执行 2PC。
在 TiDB 中,对事务的的定义是
kv.Transaction,而由于事务操作都从 session
中发起,因此还定义了 session.Txn() 来从
session 中获取当前的事务。
如下代码片段以 tables.Table.AddRecord()
为例来展示在一次插入记录操作中,如何使用事务:
1 | func (t *TableCommon) AddRecord(sctx sessionctx.Context, r []types.Datum, opts ...table.AddRecordOption) (recordID kv.Handle, err error) { |
开启新事务
在 session.NewTxn() 中,session 通过配置的 store
来开启一个事务:
1 | txn, err := s.store.BeginWithTxnScope(s.sessionVars.CheckAndGetTxnScope()) |
我们来看看 store 是如何开启事务的(以下都以
tikvStore为例 ):
1 | func newTiKVTxn(store *tikvStore, txnScope string) (*tikvTxn, error) { |
我们可以看到,如同前一节 Percolator
的流程所述,所谓开启一个事务,其实只是从 TSO 拿了
start_ts,之后以 start_ts 作为版本号创建了对应
snapshot
的事务。因为乐观事务读不加锁,只在最终提交时才判断是否有冲突。
事务内读写
读
读操作主要通过构造合适的 kv.Request 并通过
distSql.Select()来进行查询。
1 | type Request struct { |
可以看到,上述 request 中包含了
StartTs,因此会以该时间戳来进行查询。
当然,上述通过 distSql
查询的方式主要用于复杂查询,对于简单查询例如直接通过主键查询的场景(PointGetExec)就可以通过
Transaction 的 Get() 来进行查询:
1 | val, err = e.txn.GetMemBuffer().Get(ctx, key) |
写
对于事务内写,我们从上一节已经了解到,所有的写操作都会暂存在本地,最后在提交时一并发出:
1 | memBuffer := txn.GetMemBuffer() |
提交事务
我们直接来看看 tikvTxn 的
Commit()实现:
1 | func (txn *tikvTxn) Commit(ctx context.Context) error { |
(上面的 latch
是作为一个配置选项来进行开启的本地内存锁,默认关闭,文档中提到如果本地事务冲突较多可以考虑开启。)
在对twoPhaseCommitter 进行初始化后,关键逻辑就是
err = committer.execute(ctx)。
1 | func (c *twoPhaseCommitter) execute(ctx context.Context) (err error) { |
不论是 prewriteMutations 还是
commitTxn,实现当中都调用了
1 | func (c *twoPhaseCommitter) doActionOnMutations(bo *Backoffer, action twoPhaseCommitAction, mutations CommitterMutations) error { |
方法,先将本次提交所修改的 mutations 按照
region划分成组,之后根据不同的传入参数(分别是在
prewrite.go中的 actionPrewrite{} 以及
commit.go 中的
actionCommit{})来执行具体的逻辑。
Prewrite
1 | func (action actionPrewrite) handleSingleBatch(c *twoPhaseCommitter, bo *Backoffer, batch batchMutations) error { |
handleSingleBatch() 会按照 Region
拆分为的多个 batch 并行执行,每个 batch
都会执行一次。
显然,prewrite 请求会按照 region 发给对应的 tikv
来实际处理,具体处理流程见请见下一篇。
最后注意c.store.lockResolver.resolveLocksForWrite(bo, c.startTS, locks)
操作用来尝试解锁,解锁的逻辑如注释中所述:
1 | // ResolveLocks tries to resolve Locks. The resolving process is in 3 steps: |
Commit
1 | func (actionCommit) handleSingleBatch(c *twoPhaseCommitter, bo *Backoffer, batch batchMutations) error { |
与 prewrite 阶段类似,commit 阶段也是按照 region 向 tikv
发送了 commit
请求,方法中大量的操作都是在处理可能返回的提交错误,包括重试,返回错误等等方式。