TiDB 学习课程 Lesson-8
这一节的主要内容,是讲解 TiKV 如何执行下推计算的。
本文中涉及到的图片来源,都来自 PingCAP 官方网站。
通过先前的课程我们了解到,tidb 在生成执行计划时,先生成逻辑计划,之后将逻辑计划翻译成物理计划。而物理计划最终都是以 task 的形式来执行的,task 分 root task 和 coptask,coptask 通常就会下推至 tikv 来执行。
下推计算
在进行较大规模的分布式计算时,我们知道,在各节点之间传递数据,由于网络开销的原因,它的效率远没有在节点之间传递算子高,比如在用 Hadoop 进行 MapReduce 计算时,Hadoop 正是将我们写的 MapReduce 计算代码分发至各 Worker 节点,而不是从各节点读取大量数据,最后在主节点筛选计算。
tidb 也一样,既然数据可能分布在多个 tikv 节点的不同 region 中,最好的办法当然是尽量将计算靠近数据,也就是将一些能够分发的计算尽可能的分发给多个 tikv 节点里计算。一方面减少了数据传输量,节约了带宽和时间,另一方面将大任务拆分成了多个小任务并行执行,提高了执行速度。
Coprocessor
我们知道 tikv 的本职工作只是一个分布式 kv 存储,所以这些额外的计算工作需要单独的模块来负责,这就是 Coprocessor。
下图展示了 coprocessor 是如何工作的:
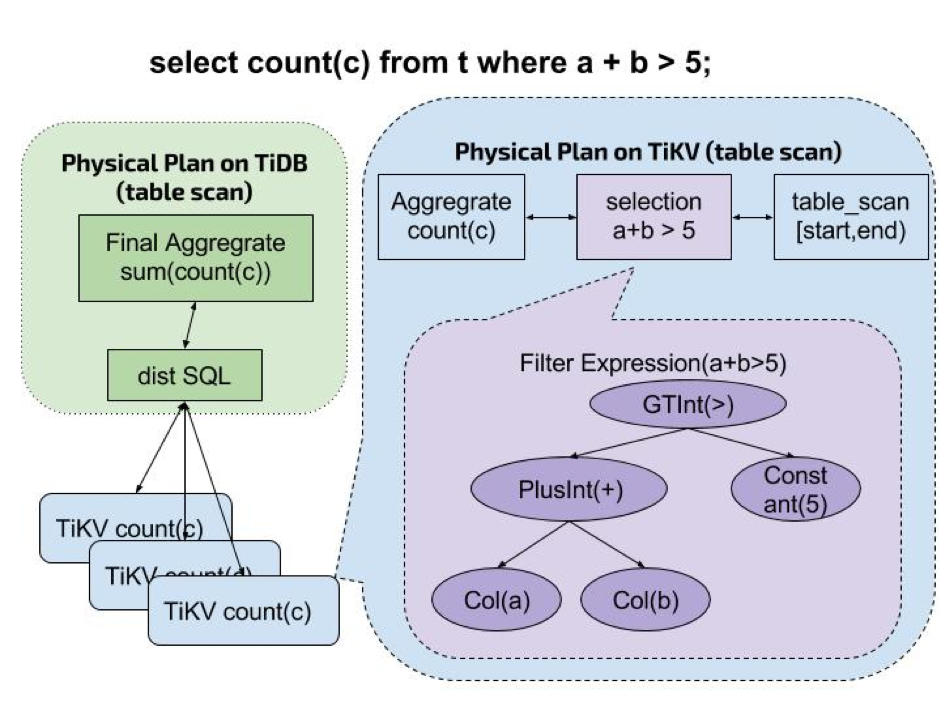
图中展示的就是一个典型的任务分发路径,tikv 收到 coptask 后进行工作,之后各节点将工作结果再返回给上层 tidb 进行整合。
在 tikv 中,coprocessor 能够处理的任务类型分三种:
- DAG:即执行 SQL 相关的物理算子,最多使用,上图即执行的 DAG 任务
- Analyze:分析型任务,将表相关的统计信息返回给 tidb,用于优化器
- CheckSum:对表数据进行校验,用于导入数据后一致性校验
DAG
DAG 即有向无环图,它类似 tidb 生成的执行计划,不同的是 tikv 收到的 DAG 是一个包含多个互相依赖的算子的图。