Richardson 成熟度模型(通往 REST 的荣光之路)
原文请见:https://martinfowler.com/articles/richardsonMaturityModel.html
最近我正在阅读一本我的几个同事一直在写的书的草稿,书名叫 Rest In Practice。他们写这本书的目的,是为了解释怎么样用 Restful web 服务来处理企业中经常面对的许多集成问题。这本书的核心概念是,web 是一种对大规模可扩展分布式系统能够工作良好的一个真实证明,并且,我们能够从中总结出一些如何更简单的构建集成系统的想法。
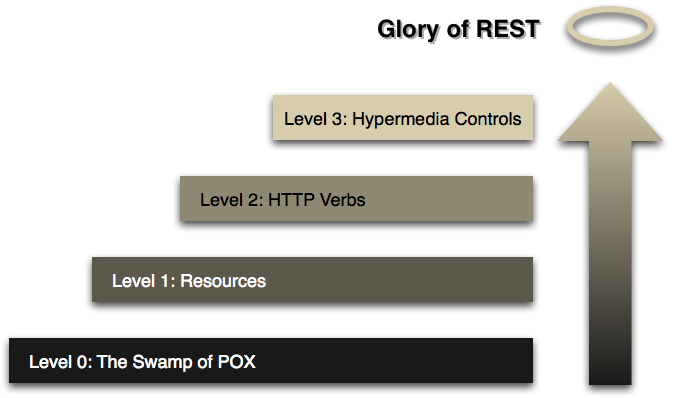
图 1:走向 REST
作者们使用了一种由 Leonard Richardson 在 QCon 大会上介绍的“restful 成熟度模型” ,来帮助解释 web-style 系统的特定属性。该模型是理解如何使用这类技术的一个好办法,因此我想尝试用自己的方式来解释它。(这里用到的协议示例仅仅用于展示,我并不觉得它值得用代码和测试来表述,因此在细节上可能存在些许问题。)
Level 0
成熟度模型的起点,是将 HTTP 用作远程交互的手段,而并不引入任何 web 机制。本质上,在这一层你只是把 HTTP 当做一个管道用在自己的远程交互机制中(通常基于 Remote Procedure Invocation)。
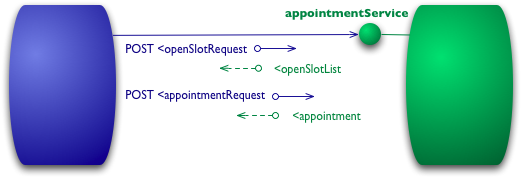
图 2:Level 0 的一个例子
假设我想预约我的医生。那么我的预约软件首先需要了解该医生在我指定的日期内还有没有空闲的时间段,所以它向医院的预约系统发了一个请求来获取这一信息。在 level 0 的场景下,医院会在某个 URL 上暴露一个服务 endpoint。首先我会向该端点发起一个 post 请求,请求体是一个包含了请求详情的文档。
1 | POST /appointmentService |
接着服务器会返回一份文档来向我说明我请求的信息
1 | 200 OK |
这里我用 XML 来举例,但实际的内容形式可以多种多样:JSON, YAML, 键值对,或任意自定义格式。
我的下一步动作就是做预约,我仍然可以通过给前面提到的 endpoint 发送一个 post 请求来实现。
1 | POST /appointmentService |
如果一切顺利的话,我会得到服务器的返回,告诉我预约成功了。
1 | 200 OK |
但假如有个人先于我完成了这一时间段的预定,我就会得到一个包含相应错误信息的返回。
1 | 200 OK |
到现在为止,这纯粹是一个 RPC 式的系统。它很简单,因为它只是来回的投递 Plain Old XML(POX)。假如你使用过 SOAP 或 XML-RPC,那么这和它们是一个类似的机制,惟一的区别在于你将 XML 信息封装成了某种不同的信封(见SOAP Envelope)。
Level 1 - Resources
RMM(Richardson Maturity Model)通往 REST 荣光之路的第一步,是引入资源(resources)。因此相较于之前我们将所有的请求都发往一个相同的 endpoint,现在我们开始讨论单独的资源。
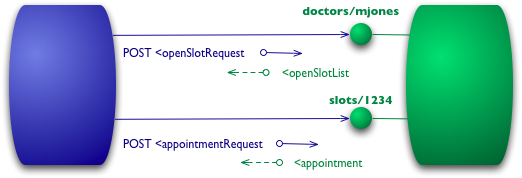
图 3:Level 1 添加资源
所以对于我们的初始查询,我们可能会指定一个 “医生资源”。
1 | POST /doctors/mjones |
服务器的返回中包含了类似的基础信息,但这一次每一个时间段都变成了一个能够单独寻址的资源。
1 | 200 OK |
对于特定的资源,预约操作就是向特定的时间段发送 post 请求。
1 | POST /slots/1234 |
如果一切顺利,我们会得到一个与前文类似的返回。
1 | 200 OK |
现在的区别就是假如某人需要对该预约进行一些操作,比如测试预定,他们会先通过类似这种
URL:http://royalhope.nhs.uk/slots/1234/appointment
来持有该预约资源,并向该资源发送 post 请求。
对于一个像我这样的对象小子(object guy),这就像是对象 id 的概念一样。我们不是调用网络上的函数并传送参数,而是在一个特定的对象上调用一个方法,提供参数来获得其他信息。
Level 2 - HTTP Verbs
在 level 0 和 1 的交互过程当中,我已经用到了 HTTP POST 动词,有些人也可能会用 GET 来实现。不过在这两层用哪一种动词都无关紧要,因为他们都是被当做隧道机制通过 HTTP 来承载你的交互动作的。Level 2 更进一步,将 HTTP 动词以尽可能接近于 HTTP 本身的用法来使用。
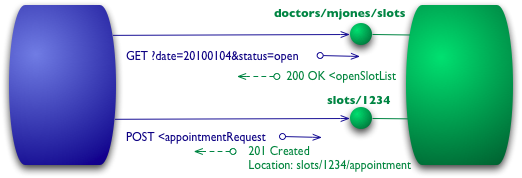
图 4:Level 2 添加 HTTP 动词
对于获取可用时间段列表,这意味着我们应当使用 GET。
1 | GET /doctors/mjones/slots?date=20100104&status=open |
对方返回与先前 post 请求一样的内容
1 | 200 OK |
在 Level 2 中,对这类请求使用 GET 是非常关键的一点。HTTP 将 GET 定义为安全操作,即它不会对任何事物的状态产生任何明显的改变。这允许我们安全的调用任意多次 GET,并且每一次都能够得到相同的结果。这样做的一个重要的结果,就是它允许请求路由中的任意参与者都能使用缓存,而缓存是让 web 发挥其应用性能的一个关键因素。HTTP 包括各种用于支持使用缓存的措施,在通信中的所有参与者都可以使用缓存。通过遵循 HTTP 的规则,我们能够从它所提供的能力中获益。
为了进行预约,我们需要一个能修改状态的 HTTP 动词,即 POST 或 PUT。我将会使用与前文类似的 POST。
1 | POST /slots/1234 |
POST 和 PUT 之间的权衡已经超出了本文的范畴,也许某日我会单独写一篇文章来讨论它们。但在这里我想指出,部分人错误的将 POST/PUT 映射为 create/update。其实这与如何选择它们毫无关系。
即使现在我像在 level 1 一样的使用 post,然而在远程服务的响应上,它们会存在显著的区别:如果一切顺利,服务器会返回一个 201 响应码来指明这世界上多了一个新的资源。
1 | 201 Created |
这个 201 响应在 URI 中包含了一个位置属性,通过这个属性,将来客户端可以通过 GET 来获取该资源当前的状态。同时该响应还包含了该资源本身,省得客户端再单独发送一个请求来获取。
在出错时(比如另一个人同时也在预约),这一层的表现也会与先前不同。
1 | 409 Conflict |
响应中的要点就是通过 HTTP 响应码来指明发生了错误。在这个例子中,用 409 似乎是个不错的选择,来指示有人已经通过一个不兼容的方式更新了该资源。相比于返回一个响应码 200 但包含了错误信息的方式,level 2 中我们显式的使用这样的错误响应。到底使用什么响应码,是由协议设计者来决定的,但只要当错误突然出现时,我们都应该返回一个非 2xx 的响应。Level 2 引入了 HTTP 动词和 HTTP 响应码。
这里有个不一致的地方。REST 的鼓吹者会说要使用所有的 HTTP 动词。他们还辩称 REST 正尝试从 web 的实际成功中学习。但实际上万维网并不经常使用到 PUT 或 DELETE。PUT 和 DELETE 有其合理的使用理由,但目前已存在的 web 并不能证明这一点。
Web 所能支持的关键元素是安全操作(如 GET)和非安全操作之间的强分离,以及使用状态码来帮助传达遇到的各种错误。
Level 3 - Hypermedia Controls
最后一层介绍了一些你经常会听到的东西,其丑陋的缩写是 HATEOAS(作为应用状态引擎的超文本)。它解决了一个问题,即如何从一个时间段列表中获悉如何去预定时间段。
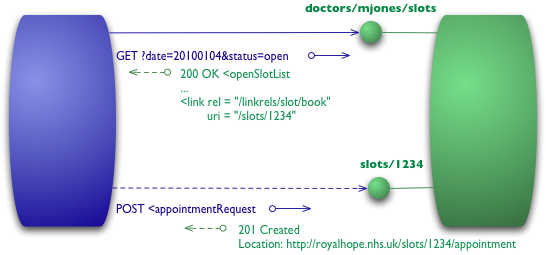
图5:Level 3 添加超媒体控件
我们以一个与 level 2 相同的初始 GET 请求为开始
1 | GET /doctors/mjones/slots?date=20100104&status=open |
但这次返回体中多了一个元素
1 | 200 OK |
现在每个时间段都多了一个包含 URI 的链接元素,它能告诉我们如何发起一次预定。
超媒体控件的意义在于它能告知我们下一步可以干什么,并且包含我们需要操作的资源的 URI。我们不需要提前了解去哪里发送我们的预约请求,而是在响应中的超媒体控件直接告诉我们如何去做。
POST 请求也还和 level 2 中的一样
1 | POST /slots/1234 |
同样的,返回中包含了一系列接下来可以干的不同事情的超媒体控件。
1 | 201 Created |
超媒体控件的一个明显的好处就是允许服务器在不影响客户端的前提下改变其 URI 设计。只要客户端找的到 “addTest” 的链接,那么服务器团队就能改变除了其初始查询入口外的一切 URI。
另一个好处是这能帮助客户端来探索整个协议。这些链接能够给客户端开发者一个提示,指出接下来可能会发生什么。但它也并不会给出所有的信息:虽然 “self” 和 “cancel” 使用了相同的 URI,但客户端开发者需要事先知道其中一个是 GET 请求,另一个是 DELETE 请求。但至少它为客户端开发者提供了一个起点,让他们思考如何获取更多信息,以及在协议文档中寻找类似的URI。
同样的,它允许服务器团队通过放置新的链接在返回中来宣布新功能。如果客户端开发者持续的关注未知的链接,那么这可能能够触发其进一步的探索。
对于超媒体控件,并没有一个标准来规定以何种形式展示。在这里我能做的是引用
“REST in Practice” 团队目前给出的建议,即遵循 ATOM (RFC 4287) ,用一个
<link> 元素结合一个目标 URI 的 uri
属性和一个描述其关系的 rel 属性来表示。一些著名的关联(如用
self
来关联该元素自身)并不存在,任何特定于该服务器的关系都是全限定的
URI。ATOM 对众所周知的 linkrel 的声明是 Registry of
Link Relations。正如我所写的,这些都局限于 ATOM 所做的事情,ATOM
通常被视为 level 3 层的领导者。
The Meaning of the Levels
我应当强调一下,RMM 虽然是一个思考 REST 元素的好方法,但却并不是 REST 本身层级的定义。Roy Fielding 已经清楚地说过RMM level 3 是实现 REST 的一个先决条件。就像其他很多软件术语一样,REST 有许多种定义,但既然是 Roy Fielding 创造的这个术语,那么他自己的定义应该更有力一些。
我觉得 RMM 有用的原因是它提供了一种一步步的理解 restful 背后的基本思想的好办法。因此我认为它只是帮我们理解概念的工具,而不应该在某种评价机制中用于评估。我认为目前我们还没有足够的示例来证明 restful 方法就是集成系统的正确方法。但我确实认为这是一种非常吸引人的方法,我也愿意在多数场景下推荐它。
在与 Ian Robinson 讨论这些时,他强调说,当 Leonard Richardson 首次提出这一模型时,他就发现了这种模型的吸引力,那就是它与常见的设计技术之间的关系:
- Level 1 通过分而治之的方式解决了处理复杂性这一问题,将一个巨大的服务 endpoint 拆分成多个资源。
- Level 2 引入了一组标准的动词,以便我们用相同的方式来处理相似的情况,消除不必要的变化。
- Level 3 引入了可发现性,提供了一种让协议变得更自说明(self-documenting)的方式。
其结果就是一个模型,它帮助我们思考我们想要提供的 HTTP 服务的形式,并构建想与之交互的人的期望。