Why Assign Final Field to Local Variable?
Recently there's a friend ask a question in a tech group chat, he said that:
In the implementation of
CopyOnWriteArrayList.add(E e), why the writer assign the final fieldlockto a local variable ?
Then he posted a picture like this:

When I open my local JDK source and get
CopyOnWriteArrayList.add(E e), I found that the
implementation of add(E e) in my version of JDK (jdk-15)
has already refactored to just use synchronized key word
(since now the performance is better than ReentrantLock)
.
Actually the picture's version of
CopyOnWriteArrayList.add(E e) is contained in JDK 1.8, so I
switch my jdk version, and found the code, then I fell into
thought...
It's useless?
Why Doug Lea(the code writer) did like that? It make no sense!
- The
lockfield is defined asfinal, no one can change it - Won't it be optimized by compiler?
After some Google, there's one guy said at StackOverflow:
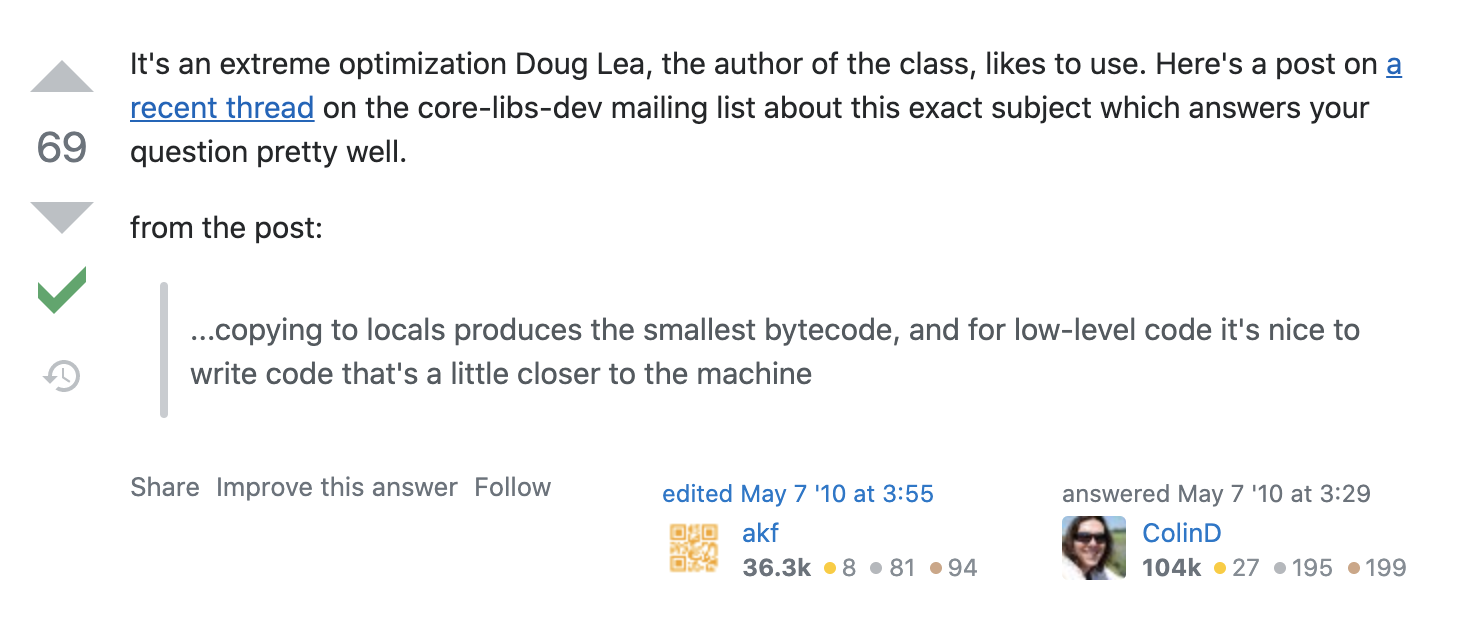
And open the thread, we can see it says it's an "extreme optimization" and can make the compiler to "produces the smallest bytecode".
WOW, That's amazing! I never thought that would come!
So now I wander: it that real?
Let's Find Out
According to the content of that thread post, the optimization is act on bytecode even machine code. So I wrote such simplified test code to simulate the circumstance:
1 | package lenshood.demo; |
There's two different methods to demonstrate the two coding style of use local variable or directly use final field.
And let's see the bytecode of the two methods:
1 | ### useLocal() |
Compare the two copy of bytecodes, it's obvious to find that:
- In the
useLocal(), there's one "getfield" and one "astore_1" + two "aload_1" to assign/load local variables from final field "fLock". - In the
useField(), there's two "getfield".
Hence, we found the bytecodes do have difference, but why
1*getfiled + 1*astore + 2*aload is better than
2*getfield ?
Here is some possible hypotheses:
- Local variable can store at registers, but field can only get from memory, which is slower
- Final field has the semantics of
happens-before, and JVM may insert load barriers before get final field
But how to prove them? We better go deeper: pass through bytecode and go to asm!
Get ASM from JIT
Firstly we may need to install a plugin for HotSpot VM to do disassembling.
hsdis is contained in the jdk source code, we can find
it from openjdk at GitHub.
To jdk-15, the hsdis is located in:
src/utils/hsdis
Install hsdis to
MacOS (for JDK-15)
binutilsis needed:- Download
binutilsfrom: https://www.gnu.org/software/binutils/ tar -xvf binutils-xxx.tar.bz2
- Download
- Get
hsdissource, then build it- Assume we're in the
hsdisdir, putbinutilswe just downloaded in it. make BINUTILS=binutils-xxx ARCH=amd64
- Assume we're in the
- Put plugin into jdk
sudo cp build/macosx-amd64/hsdis-amd64.dylib $JAVA_HOME/lib/server
Get ASM
javac FinalTest.javajava -Xbatch -XX:-TieredCompilation -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly
Then we can get ASM code output to shell, select the section related to our methods:
1 | ############ useLocal() ############ |
In the ASM of useLocal(), we can simply find it first
get the final field fLock and put it to r11
register as a local variable (0x0000000117530070), after
that, when find the ReentrantLock instant fron dynamic
table ( 0x000000011753008d ), the code directly use r11 to
get the address.
Down to 0x0000000117530110 we know it's the
i++ operation, and then at the next address
0x0000000117530114 -- when do unlock() -- the
sync field (inner field in ReentrantLock) are
just addressing from rbx, which contained calculated result
from r11 (0x000000011753008d).
1 | ############ useFeild() ############ |
The useField() is even simplier, at
0x000000011752f5ef and 0x000000011752f68f, it
just read fLock twice from memory.
So the Performance indeed better
Go back to our two hypotheses: 1. Register: yes, it use register to
hold local variable and avoid twice load from memory(cache) 2. Load
barrier: there's no explicit barriers we can find, however, due to the
strong
memory model of x86(TSO),
mov already implied the LoadLoad barrier semantics.
Conclusion
After our study, now we can explain why assign a final field to local variable can get better performance, we can also know that why it's an "extreme optimization".
Hence, put this optimization to everywhere maybe not a good idea, but the spirit of pursue the ultimate performance it's really admirable.