Go Runtime 设计:存储资源管理

本文介绍了 Golang Runtime 中关于内存管理的设计。
内存管理,主要可以分为两部分:内存分配和内存回收。
在 Go 语言中,所有需要内存的地方,除了编译期可以确定的常量、变量值以外,其他的包括 goroutine 私有栈,堆以及一些 runtime 的结构,都需要在运行期间动态进行分配。相对应的,当内存不再使用的时候,也需要动态的回收。
不过 Go 语言的内存分配完全不需要用户操心,Runtime 会帮助用户处理好与内存管理相关的一切。
本文会先讨论 Go Runtime 使用的动态内存分配器;之后介绍所有需要动态分配内存的地方如栈、堆等等,具体是如何使用内存分配器分配内存的;关于内存的动态回收,将放在最后一部分讲解。
1. 动态内存分配器
1.1 为什么需要动态内存分配器?
在讨论动态内存分配之前,我们可以先回顾一下操作系统的内存管理,并解释为什么不能简单的使用系统调用来管理进程内存。
虚拟内存抽象
为了能让不同的进程能优雅的共享同一套存储硬件,多任务操作系统普遍采用了地址空间 + 虚拟内存的办法,对物理内存进行了抽象。

这种抽象的本质是把物理内存视为磁盘的缓存,而把磁盘视为主存。
虚拟内存为多进程的并发执行带来了如下的好处:
- 通过地址映射(mapping)技术,可以支持多进程独占地址空间的同时还能共享同一套硬件
- 每个进程都拥有自己的页表,用于记录进程虚拟地址与物理内存地址的映射关系
- 进程可以自由的在整个地址空间中申请并使用内存,而不必担心与其他进程产生冲突
- 通过交换(swaping)技术,虚拟内存能够让进程可操作的地址空间远大于实际的物理内存
- 访问页表中不存在的映射触发缺页中断,操作系统从磁盘(主存)中加载数据到物理内存(缓存)
- 如果物理内存已满,则会通过页面置换算法将某些进程的某些页面淘汰到磁盘,而空出内存空间
内存布局
为了方便对进程使用虚拟内存,操作系统还对整个进程的地址空间进行了分段,Linux 下进程的内存布局如下(图源:CSAPP Figure 9.26):
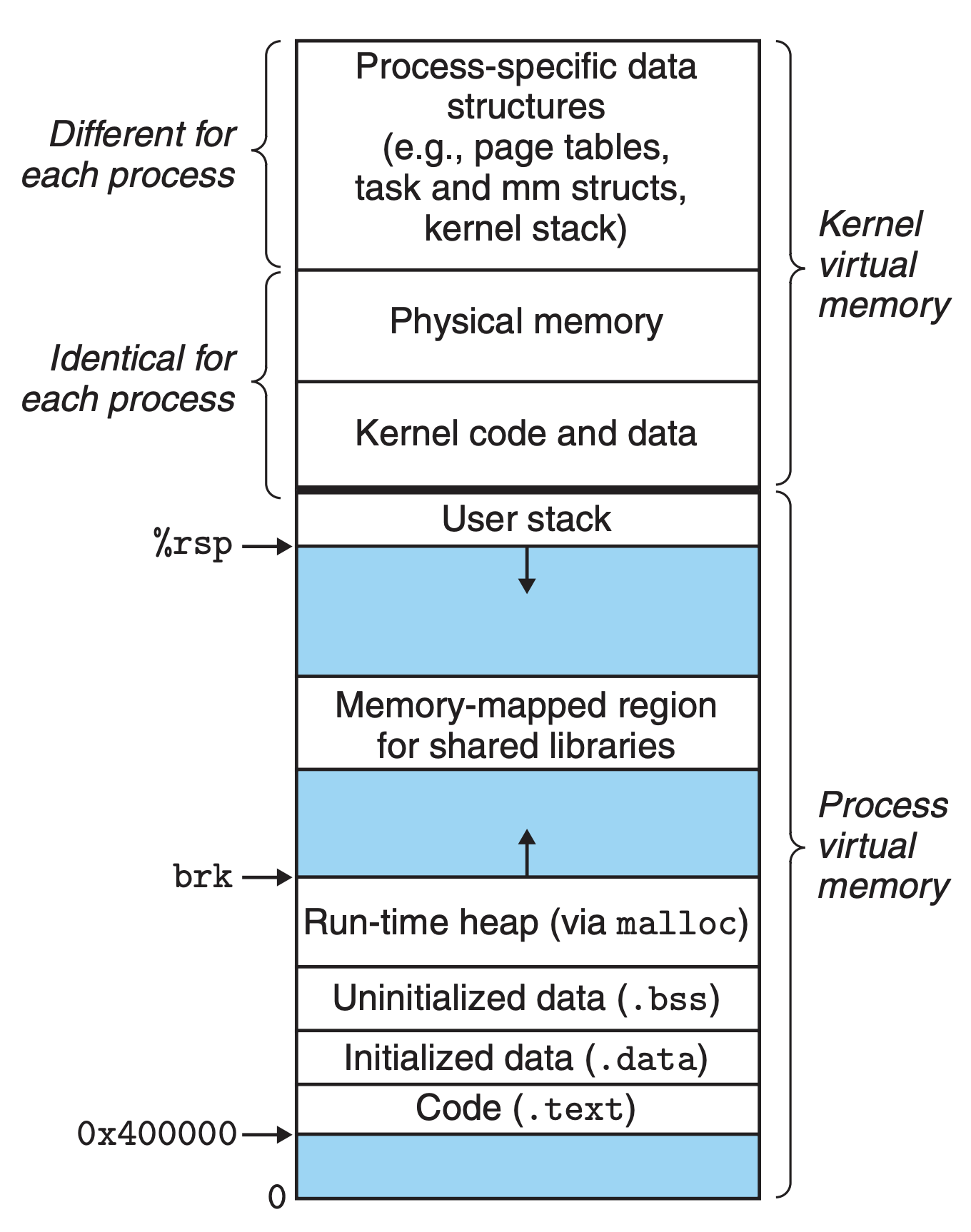
Linux 进程的整个虚拟地址空间,从 0x400000 开始,到栈区高地址结束,更高的地址空间留给内核。
进程内存段从低地址开始分别被划分为:
- 代码段
.text - 已初始化数据段
.data - 未初始化数据段
.bss - 运行时堆
heap - 共享库内存映射区
mmap - 运行时栈
stack
如上图所示,对于运行中的进程,如果对内存有需要时,可以有三种方式:
- 向低地址扩张栈指针,等同于分配栈空间
- 通过 brk 系统调用,向高地址扩张,分配堆空间
- 通过 mmap 系统调用,在内存映射区分配空间
当然了,通过上述过程所分配的内存空间,在实际访问的那一刻之前,都没有实际分配,只有在访问时才会触发缺页中断。
既然操作系统已经提供了这么多种内存分配的系统调用,我们为什么还要使用用户层代码来动态的管理内存呢?
动态内存管理
首先需要明确的是,我们所谓的动态内存管理,通常都是用来管理堆内存。而动态内存管理需要解决的本质问题是在运行时对内存需求的不确定性。
相反对于栈内存的分配和回收,通常在编译期就能明确栈空间所需的大小,因此就可以简单的通过操作 SP 指针来管理栈内存。
那么用 brk 或 mmap 就不能实现动态的分配和回收堆内存吗?
理论上讲,是完全可以的,毕竟 brk 和 mmap 本身就是进程申请向 os 申请内存时必须要涉及到的系统调用。
但问题主要在于:
很多时候,进程需要的是频繁的分配/释放小块空间,而不是少量的分配/释放大块空间。但由于执行系统调用所耗费的时间高于执行库函数,这就导致分配/释放小块空间的过程中,系统调用的耗时对总耗时产生了可观的影响。
那么,如果当需要分配小块空间时,一次性多分配一些,这样在下一次又需要分配小块空间时,就可以不用再通过系统调用。反之,当想要释放小块空间时,暂时不释放给系统,而是攒到一定程度后再合并释放,也能减少系统调用次数。
为了演示上述问题,我们来看如下测试,
执行一百万次给定 size 内存空间的申请、初始化、释放过程,耗时对比(越短说明越快):
| Alloc Size | malloc/ms | brk/ms | mmap/ms |
|---|---|---|---|
| 128 Bytes | 393 | 4738 | 5235 |
| 1 KiB | 2902 | 8791 | 8004 |
| 4 KiB | 11348 | 17375 | 16321 |
| 16 KiB | 44793 | 56489 | 56832 |
结果表明,不论是哪种 size,brk 和 mmap 耗时差别不大,而 malloc 都比这些系统调用要快。更进一步的,当分配 128 bytes 空间时,malloc 的性能表现时系统调用的约 10 倍,随着分配空间的不断加大,malloc 的性能优势逐步从 3 倍降低到 1.5 倍最后到 1.2 倍。
所以,通过动态内存管理,将零散的内存分配/释放请求合并起来,减少了频繁的系统调用,提升了性能。
1.2 不同的内存分配器算法
1.2.1 设计要求、目标、障碍
上一节我们看到了动态内存分配器相比于系统调用的优势。那么,如果要设计一个内存分配器,我们对它有什么要求?设计目标又是什么?
在《CSAPP》§9.9.3 中对动态内存分配器的设计要求和设计目标做了阐述:
设计要求
- 处理任意请求序列:分配器不能假设分配和释放的顺序,用户可以任意的进行分配或释放
- 立即响应请求:不能为了提高性能而对分配请求进行缓存或重排(分配请求所返回的内存地址必须是立即可用的,相反释放请求不需要立即完成)
- 只使用堆:为了可扩展,分配器自己用到的所有非标量数据结构都要放在堆上
- 块对齐:分配的块必须对齐
- 不修改已分配的块:一旦块被分配出去,就不允许分配器对其进行任何的修改或移动(防止用户访问到非法区域),相反空闲块可以被修改或移动
设计目标
- 最大化吞吐率:即单位时间内处理的请求量最大化。这要求我们尽可能的缩减分配/释放请求的耗时。简单的方式是让分配请求耗时与空闲块数量成线性反比,而释放请求耗时为常数。
- 最大化内存利用率:内存资源是有限的,最大化利用率意味着最小的浪费。峰值利用率代表在 n 个分配/释放请求过程中,在某一刻分配出去的最大有效载荷之和,与堆空间容量的占比。占比越高说明对空间的利用率越高。
显然,最大化吞吐率和最大化内存利用率之间会相互牵制,我们无法设计出一个既满足最大化吞吐率又满足最大化利用率的分配器,而分配器的设计挑战就在于寻找平衡。
设计障碍
动态内存管理,在改善性能的同时,也会引入新的问题,如下的两种问题,会严重的影响内存分配器实际的性能表现:
碎片:
应用程序对分配内存大小的要求,不是整齐划一的,经常会出现请求的容量忽大忽小,这就可能导致碎片的产生。

如上图所示,在总共 20 KiB 的可用空间里,红色的部分代表已分配,其他的是空闲,那么假设,
需要分配 8 KiB:
需要寻找连续的 8 KiB 空闲区,那么假如从头开始搜索,就需要搜索到第 6 块处才能找到合适的空间。
由于前面的小碎片空间,无法满足需求,因此会增加查找成本,降低性能。
需要分配 16KiB:
从头开始搜索,一直到最后都无法找到 16KiB 的连续空闲区。但实际上剩余的空闲空间,正好是 16KiB。
随着碎片的不断产生,如果处理不当,分配请求可能会越来越慢。引用这篇文章中举的例子:
”某款 TV 盒子的测试,是连续 24 小时间,每 10 秒钟换一次台。由于内存碎片的严重影响,刚开始在换台后 1 秒钟视频就能播放,而24 小时候,这一过程需要花费 7 秒。“
竞争:
动态内存管理程序必须考虑多线程竞争请求的问题。保证线程安全,最简单的办法当然是加锁,然而加锁是有不小的开销的。当分配器能很顺利的找到空闲区时,加锁解锁的开销可能会产生可观的耗时占比。
要处理竞争问题,一个可行的办法就是尽量避免竞争。
实际当中可以通过线程缓存等方式来确保只有单线程发起请求,然而,某些情况下(比如内存在一个线程申请,在另一个线程释放)就会产生额外开销。同时,线程缓存本身也会降低内存利用率。
1.2.2 dlmalloc
dlmalloc 是 Doug Lea 设计的内存分配器,在早期被广泛使用,后来由于多线程方面的问题不再被使用,但其设计思想值得学习。
Dlmalloc 采用的是类似 best-fit 的内存查找算法。
其采用 Chunk 来作为内存分配的单元,Chunk 本身作为隐式链表,保存有前后 Chunk 的大小、是否使用等信息。此外又通过两个显式空闲链表 small_bin 和 tree_bin 来分别存放小的(小于 256 bytes)和大的空闲 Chunk,方便快速查找。

上图展示了 Chunk 链。
在左侧的图中,Chunk 0、1、2 都正在被使用,使用中的 Chunk 在头部保存了自己的 payload 大小,以及自己和前面的 Chunk 是否被使用。而对于被释放的 Chunk,会在 Chunk 底部添加 header 的拷贝,作为 footer,有了 footer,空闲 Chunk 就可以快速合并。另外在空闲 Chunk 的原 payload 处还写入了两个指针用来串联显式空闲链表。
分配:
dlmalloc 并不是在一开始就会分配很大的一块空间,而是从 top chunk(最初的特殊 Chunk)开始,随内存分配请求逐步分割成更小的 Chunk,而当被分割的 Chunk 使用完毕被释放后,就会将其放入合适的空闲链表 bin 中管理。
释放:
通过待释放的指针,找到 header 标记为释放,之后要检查前后的 Chunk 是否也为空闲,如果是则需要进行合并,合并后再放入 bin 中的对应位置。
除了 Chunk 外,dlmalloc 还引入了 segment 的概念,其中 top chunk 存放在 Top segment,而对于一些较大的内存请求,会直接通过 mmap 进行分配,并通过一个独立的 segment 来跟踪(因为每一次 mmap 分配的地址可能会不连续)。

更进一步的,为了聚合 segments、top chunk、以及 bin,又引入了 mspace 的概念,通过 mspace 结构来持有这些元素。用户可以通过创建多个 mspace,来分割出多个互相无关的内存区。
dlmalloc 默认线程不安全,而只有当定义了 USE_LOCKS
标志后,才会在多线程调用时加锁。但 dlmalloc
的加锁方式比较简单,所有请求操作都会争抢 malloc_state
中的同一把锁,导致明显的锁开销。
1.2.3 ptmalloc
回顾前文讲到的设计障碍,dlmalloc 通过分割、合并 Chunk,结合复用不同大小的 Chunk 来缓解碎片的产生,通过显式空闲链表来加速 best-fit 的速度。而 ptmalloc 的作者 Wolfram Gloger 则是利用 dlmalloc 的基础,将其核心思想继承并在多线程竞争方面进行了优化和改善。
目前最新的 ptmalloc 是 ptmalloc3 (但最新的 glic 2.36 中仍然采用的是 ptmalloc2)。

ptmalloc 正是利用了 mspace 的概念尽量给每一个线程提供一个固定的内存区,避免加锁。
如上图所示,当 ptmalloc 初始化后,只存在一个 main arena 即主内存区,任何线程请求 malloc 时都会先检查 main arena,如果 main arena 上锁,说明有其他线程正在使用,当前线程会创建一个新的 arena,在新的 arena 里申请内存,之后将该 arena 加入以 main arena 为头结点的环形链表。
同时,由该线程创建的 arena 会保存在线程本地变量,下一次同一个线程再次申请内存时就可以直接从该 arena 中进行申请。
而如果此时有第三个线程申请内存时,它仍旧会从 main arena 开始搜索,只要找到未上锁的 arena,就使用它,并将其绑定到自己的本地变量中。
ptmalloc 通过这种方式能显著的降低线程竞争,但也存在一些问题,如:
- arena 之间可能存在严重的分配不均衡
- 仍然存在一定的加锁开销
1.2.4 tcmalloc
tcmalloc 的全称是 thread caching malloc,从名称中就能知道,tcmalloc 会采用线程缓存来减少分配中的竞争和锁开销。tcmalloc 由 Google 开发,golang 的内存分配器也大致上与 tcmalloc 的实现一致。

如上图所示,tcmalloc 包含三层组件:
最靠近用户请求的 front-end 层,作为缓存,为应用程序提供高速的内存分配和释放
- 提供了两种缓存方式:线程缓存或 cpu core 缓存,线程 cache 会随着线程数量的增加而增加,导致大量线程缓存。cpu core 缓存则会将缓存与每个 cpu 逻辑核心绑定
- 缓存空间不足时,会从 middle-end 处获取
- 缓存的对象数量会随着申请和释放动态调整
中间层 middle-end 主要为了给 front-end 提供内存源
- transfer cache:front-end 申请或归还内存,都会先走 transfer cache,transfer cache 用数组来保存空闲空间地址,以加快对象的移动速度。对于在一个 core 申请,在另一个 core 释放的场景,transfer cache 效率较高
- central free list:以 span 的概念来维护内存,一个 span 可以持有 1~n 个 page(tcmalloc 定义的 page),分配内存时根据对象大小选择合适的 span,如果空间不足则向 back-end 申请
最下层 back-end 负责与 os 交互获取 os 内存
back-end 采用 pagemap 来查找对象地址属于哪一个 span
pagemap 是一个 radix 树,可以映射整个地址空间,见下图

对于内存分配,tcmalloc 将分配请求分为两类:
- 小对象:先从 front-end 尝试分配,将小对象映射到60~80 种大小类(size-class)中,每一级大小类之间差 8KiB(类似 dlmalloc 的划分),按细分的大小类分配可以降低内存浪费。通常一个 span 只会存放一种 size-class 的对象,便于管理和寻址。
- 大对象:跨过 front-end 和 middle-end,直接从 back-end 分配
1.2.5 jemalloc
jemalloc 是由 Jason Evans 设计,因此叫 jemalloc。包含在 FreeBSD 的标准库中,也在 Firefox 和 Facebook 的服务器上使用。
jemalloc 的设计中借鉴了许多其他分配器的实践,同时也有自己的特色:
- 按照 size-class 来分配小对象,同时采取类似 first-fit 的匹配方式来提升吞吐量
- 仔细的选取 size-class,如果 size-class 之间跨度太大,会增加内部碎片量,而如果 size-class 选取的太过致密,则会增加外部碎片的量
- 限制 metadata 的内存占用量不超过总量的 2%
- 尽量缩小活跃页面集合(active page set),这样可以降低操作系统将页面换出的概率
- 通过 thread cache 减少锁竞争
- 通过大幅简化布局算法来提升性能和可预测性,不断努力将 jemalloc 打造为通用的分配器,这样用户就能避免需要根据应用程序的特点来选择特定的分配器
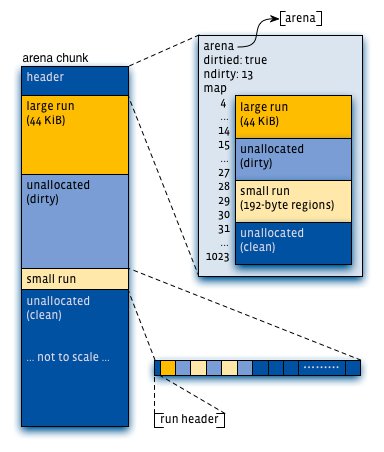
与 ptmalloc 类似,每一个线程都会以 round-robin 的形式绑定 arena。arena 之间相互独立,每一个 arena 又被细分为一个个的chunk,chunk 通过维护自己的 header 来追踪更细粒度的 page runs。
除了 header,chunk 里剩下的部分就是一组又一组 page runs,小对象被组织为 small page runs,small page runs 还有自己的 run header,而每个大对象占据一个 page run,并由 chunk header 进行管理。
对每一个 chunk 中的 small page run,dirty page run,以及 clean page run,arena 都使用红黑树来进行管理。
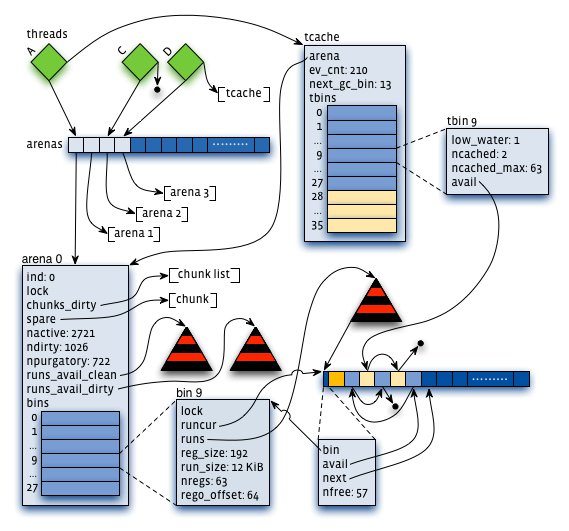
为了进一步的降低锁竞争,对每一个线程还设计了 tcache,类似于 tcmalloc。小对象在 tcache 中分配可以减少 10-100 倍的同步开销,但也会加剧碎片化,为了解决碎片化问题,tcache 会通过 gc 逐步将更老的对象 flush 到 arena 中。
1.3 Go 内存分配器设计
在上文中我们简单的了解了内存分配器的设计目标是期望寻找吞吐率和资源利用率的平衡,而在设计过程中,碎片和线程竞争是可能会严重影响分配器吞吐率和资源利用率的两大问题。
我们发现,不论哪种分配器,都存在如下的共性:
- 区别对待大对象和小对象
- 小对象更容易造成碎片问题,因此针对小对象,采取大小类(size-class)的方式进一步细分,便于复用
- 大对象直接分配或释放,并单独管理
- 采用线程缓存和线程绑定区域来降低竞争开销
- 留一小部分空间作为线程缓存,完全不需要加锁
- 将固定的区域与线程绑定,减少访问该区域的线程数量,降低竞争
golang 的内存分配器,原理上大致是遵循了 tcmalloc 的设计,在使用上与 go 语言本身做了集成。
1.3.1 总体架构
从逻辑角度看,go 的内存分配器分为三层,cache、central、heap。
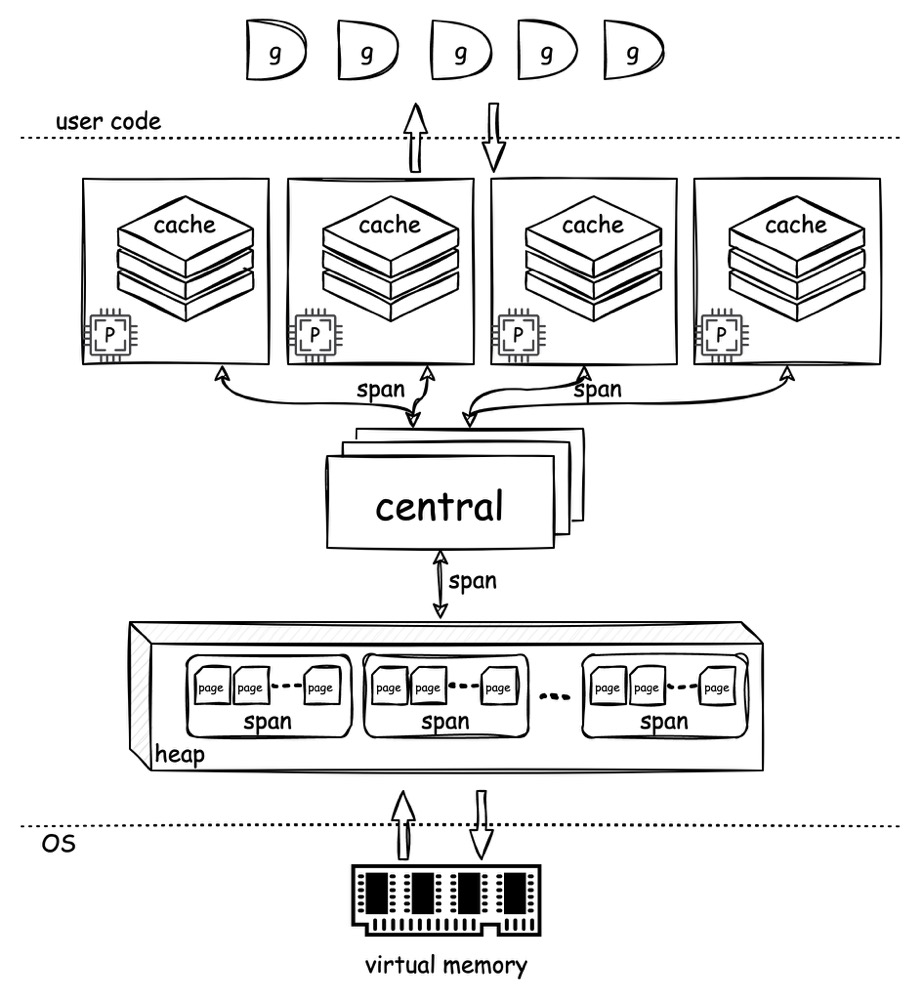
就如同前面 tcmalloc 章节中讲到的,cache、central 和 heap 分别对应了 front-end、middle-end 和 back-end。
每一个 p 都会持有一个 cache,而在 p 上运行的 g 其内存分配动作会首先考虑从 cache 中获取。假如 cache 空间不足,就会下探到 central 分配,所有 p 共享一组 central,因此对 central 的操作需要加锁。假如当 central 也空间不足时,就会向 heap 寻求空间,而 heap 实际上会从 os 处真正的获取内存。
在 cache、central 与 heap 的交互中,对内存空间的申请和分配,都是以 span 为单位的。span 是一个抽象的概念,每一个 span 包含了 n 个 page(1 page = 8 KiB)作为其空间,并要求只存储一种 size-class 的对象。
1.3.2 size-class
golang 中,以 16 byte 和 32768 byte 为界,将对象划分为微对象(tiny),小对象(small),大对象(large)。
对于微对象和大对象都有特殊的处理办法,而夹在中间的小对象,是以 size-class 大小类为基准来分配的。
一共划分了 67 个 size-class(为了保持一致性,size-class == 0 代表任意大小),每一个 size-class 的信息如下(完整表格):
| class | bytes/obj | bytes/span | objects | tail waste | max waste | min align |
|---|---|---|---|---|---|---|
| 1 | 8 | 8192 | 1024 | 0 | 87.50% | 8 |
| 2 | 16 | 8192 | 512 | 0 | 43.75% | 16 |
| 3 | 24 | 8192 | 341 | 8 | 29.24% | 8 |
| 4 | 32 | 8192 | 256 | 0 | 21.88% | 32 |
| 5 | 48 | 8192 | 170 | 32 | 31.52% | 16 |
| 6 | 64 | 8192 | 128 | 0 | 23.44% | 64 |
| 7 | 80 | 8192 | 102 | 32 | 19.07% | 16 |
| 8 | 96 | 8192 | 85 | 32 | 15.95% | 32 |
| 9 | 112 | 8192 | 73 | 16 | 13.56% | 16 |
| 10 | 128 | 8192 | 64 | 0 | 11.72% | 128 |
| 11 | 144 | 8192 | 56 | 128 | 11.82% | 16 |
| 12 | 160 | 8192 | 51 | 32 | 9.73% | 32 |
| 13 | 176 | 8192 | 46 | 96 | 9.59% | 16 |
| 14 | 192 | 8192 | 42 | 128 | 9.25% | 64 |
| 15 | 208 | 8192 | 39 | 80 | 8.12% | 16 |
| .. | .. | .. | .. | .. | .. | .. |
| 66 | 28672 | 57344 | 2 | 0 | 4.91% | 4096 |
| 67 | 32768 | 32768 | 1 | 0 | 12.50% | 8192 |
上述表格展示了 67 种 size-class 在 span 中可分配不同数量的对象,以及可能产生内部碎片的最小数量和最大浪费率。
最小数量的内部碎片(tail waste)是由对象大小和页容量决定的,以
size-class = 11 为例,内存按页分配,因此每个 span 至少分配一页即 8
KiB,size-class = 11 所指代的最大对象大小是 144 byte,如果全部以 144
byte 分配,则内部碎片数量为(按 int
类型计算):8192 mod 144 = 128。
最大浪费率,是指当前 size-class
所允许的任意对象,其组合导致最大可能产生的剩余容量的浪费率。span
为了快速定位对象,每一个对象无论实际大小是多少,都会按照最大大小来分配。因此,仍以
size-class = 11 为例,其最小对象要求至少 129 byte(再小就会进入
size-class = 10 的范围),但仍旧会分配 144 byte 的空间(最多分配 56
个对象)。最终,最大空间浪费率为:(8192 - 129*56) / 8192 * 100 ≈ 11.82%。
1.3.3 span
span 作为内存分配的基本单元,其内部结构设计的很巧妙。由于 span 本身和 size-class 绑定,因此本节仍旧以 size-class = 11 的 span 为例。
span 的主要构成如下图所示:
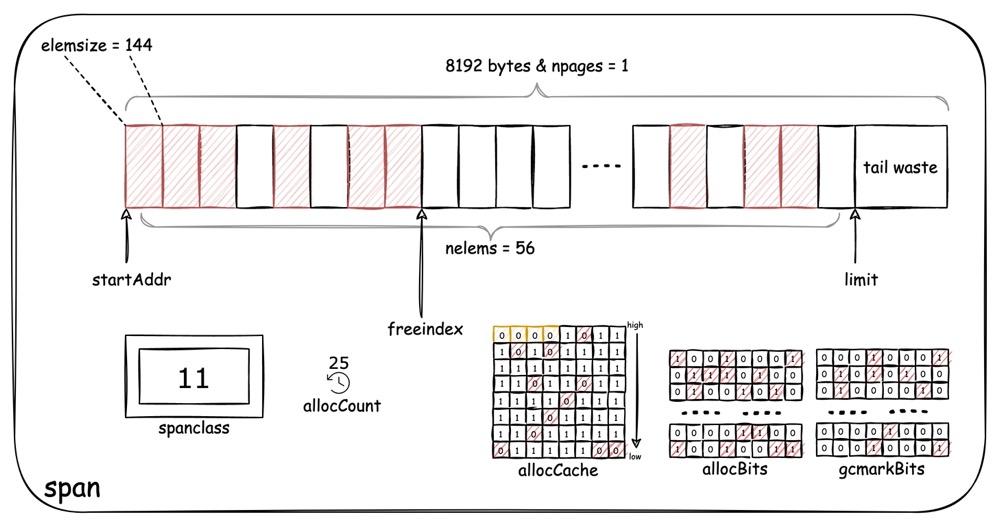
spanclass 作为 span
最基本的属性,决定了以下其他属性的值。
通过 spanclass 对应到上一节的表格,我们能看到 span
里面包含了许多熟悉的属性:
npages:每一个 span 可能会包含 n 个 page,对于 size-class = 11 的 span,只包含 1 个 page,即npages= 1elemsize:size-class = 11 的 span 其划分的每一个存放对象的 slot 空间大小为 144 bytesnelems:同样,144 bytes 的 slot 空间,对应了最多能存放 56 个对象
span 代表了一段内存空间,因此 startAddr 表示 span
空间的起始地址;而 limit 则是终止地址,可以发现
limit 指向的是 tail waste 的首地址,即地址一旦到达
limit,就不可能指向任何合法的对象了。
allocCount 顾名思义是代表当前的 span
中已经分配了多少个对象。
allocBits 和 gcmarkBits 是反映当前 span
中已分配对象和空闲 slot 的位图映射,其中 gcmarkBits
是作为最新一次 gc 标记后的结果,每次 gc 标记完成后会更新
allocBits (详细内容可见后文垃圾回收部分),初始的
allocBits 和 gcmarkBits 都是全
0,图中标红色的区域代表已经被分配。
在 span 中分配对象
对于初始化的 span,地址空间已经分配好,每个对象的 size
也已确定,因此当 span
接收到空间分配请求时,会直接从startAddr 处向后推进一个 slot
即 144 bytes
的空间,作为当前请求方的独占对象空间,并返回startAddr
作为空间首地址。
So far so good.
但接收下一次请求时呢?很显然我们需要一种记录簿,来标记哪些 slot
已被占用,哪些 slot 是空闲的,这就是 allocBits
存在的原因。
有了 allocBits
,我们就可以很方便的通过遍历该位图表寻找空闲 slot。
但问题在于,内存分配/释放的请求是非常频繁的动作,任何细微的性能延迟都会因为大量的请求次数而被急剧放大。换句话说,遍历查表太慢了。
加速分配
为了能快速、准确的定位到空闲 slot,在 span 中采用
allocCache 和 freeindex
巧妙的简化了这一过程。
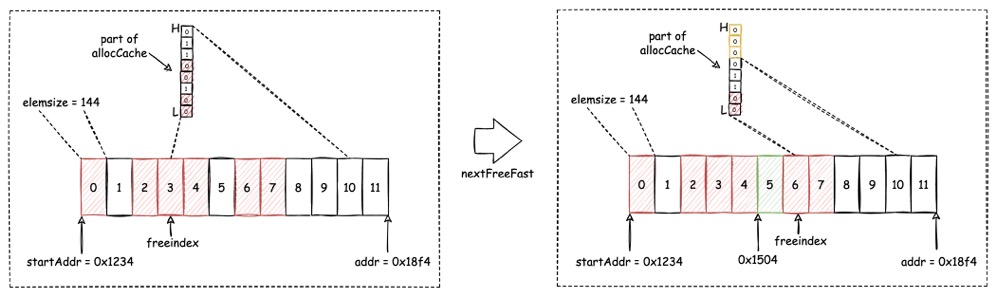
如左图所示,freeindex 代表最近一次分配的 slot 位置 +
1,即最近一次分配了2,freeindex 指向 3,下一次分配会从 3
处开始尝试。
allocCache 是一个 64 bits 固定大小的 bitmap,它反映了从
freeindex 为起始的后续最多 64 个 slot 的空闲情况,1 代表空闲,0
代表已占用。图中展示的是allocCache 的一小部分,它指代了从 3
开始到 10 结束的 8 个 slot 的空闲情况,红色代表已占用。
整个寻找空闲 slot 的过程如下:
- 选择
freeindex作为 slot 查找的起始位置,即从 3 开始。 - 从低地址开始查找
allocCache,寻找第一个不为 0 的 bit 就是第一个空闲 slot 的 offset(这里采用了 deBruijn 序列来快速定位最低位的 1),显然这里的 offset = 2。 - 通过计算
freeindex+ offset 就可得到空闲 slot 的实际位置 n,即 n = 3+2 = 5。而空闲 slot 的物理地址,可通过startAddr+ n*elemsize计算,即 0x1234 + 5*144 = 0x1504。 - 之后更新
freeindex为上一步分配的 slot 位置 n 再 +1,即freeindex= 6,可见右图。 allocCache右移 offset + 1 位,下一次将从 offset + 1 处开始寻找(图中橙色的 bit 就是右移后的补零,这些零无任何业务意义),亦可见右图。
存在两种情况需要做额外处理:
allocCache全 0:这说明当前的allocCache中已经没有任何空闲 slot 了freeindex未达到nelems的前提下(span 未满),freeindex== 64:这说明freeindex向前移动的 offset == 64,由于allocCache每次都会右移 offset 位,这代表当前的allocCache已经寻找完了
对于上述两种情况,都需要做一件事:从当前freeindex
位置开始,向后读取 64 bit 的allocBits
,作为新的allocCache 。
更新了 allocCache 后,就又可以重复前面寻找空闲 slot
的步骤了。
释放重置
go runtime
中,对象的释放是通过垃圾回收(GC)机制实现的(详见后文),那么在每次 GC
之后,span 中会释放掉许多 slot,释放后最新的对象占用情况会更新到
allocBits 中。
在空间释放后,span 多出了许多空闲 slot,这时必须重置
freeindex 和 allocCache,以避免在寻找空闲 slot
时产生错误的结果。
- 重置
freeindex即直接将其置零 - 重置
allocCache则是从allocBits的起始位置处向后读取 64 bit 信息存入allocCache
1.3.4 front-end: cache
在 go runtime 中,每一个 p 都持有一个名为 mcache
的结构,这就是 cache。由于同一时间在 p 上只能执行一个
g,所以对mcache的操作不需要加锁。
mcache 的结构如下:
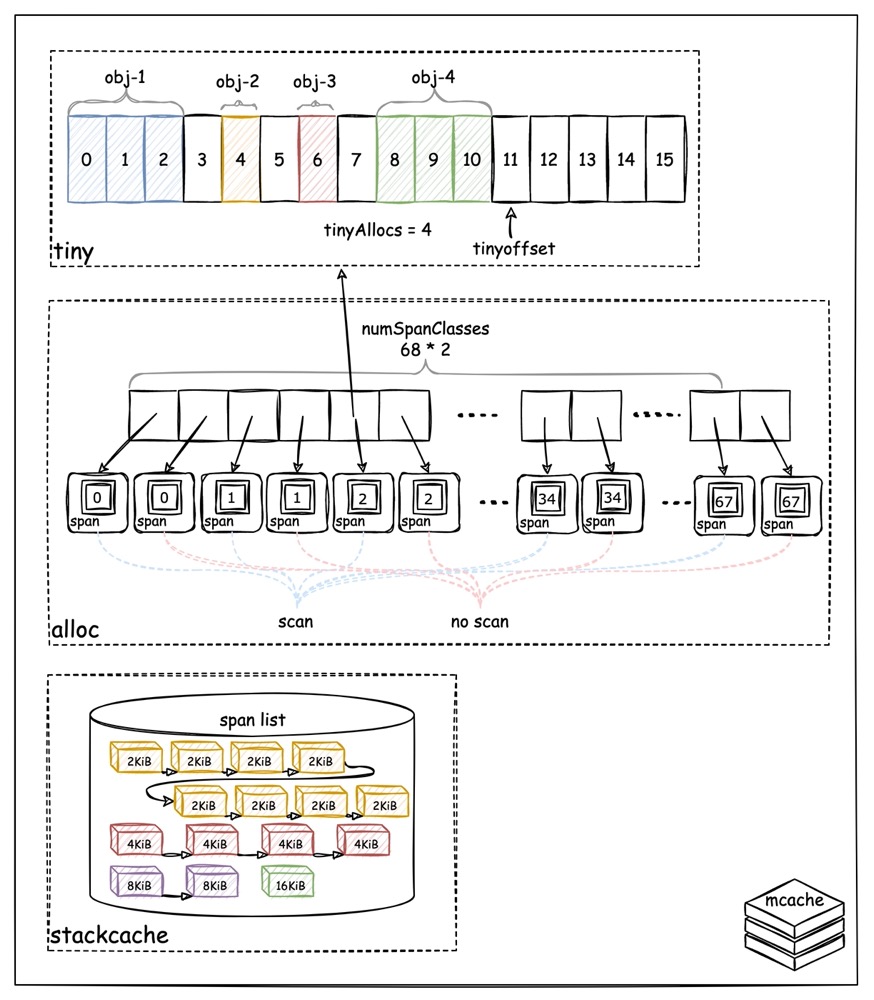
mcache
中核心的三部分分别是:tiny、alloc、stackcache。
alloc
alloc 实际上是一个 span
数组,数组中的每一个元素都存放了一个特定 size-class 的 span
的地址。我们会发现整个数组一共有 68*2=136 个元素(136 这个数字称为 numSpanClasses),其中,每一个
size-class 对应了两个 span,从上文的表格我们知道 size-class 一共有 67
个,这里多出来的一个是 size-class=0 即特殊的
size-class(不限容量)。
为什么每一个 size-class 对应了两个 span 呢?主要与 GC 扫描有关。
这里的两个 span,分别用于存放scan 和noscan
的对象,noscan
的对象代表对象本身或对象中不包含任何指针,因此在做 GC
扫描的时候可以直接标记,而不需要递归的查找指针所指的对象。将scan
和 noscan 的 span 区分开,能够简化 GC 扫描的过程。
当应用程序需要分配小对象时,通常会从alloc中分配,整个流程如下:
- 根据对象的大小和是否
noscan,定位到alloc中具体的某一个元素 - 取出该元素指向的 span,通过前文 span 分配对象的方式给对象分配空间
- 如果当前 span 已满,则从 middle-end 的 central 中获取一个新的 span,并把原来已满的 span 归还给 central,之后重复第二步
看似 alloc 要包含 136 个
span,实际上初始化后,每一个alloc元素指向的都是同一个 dummy
span,对该 dummy span 的分配操作会触发从 central 获取新 span
的逻辑。
因此,只有实际用到的 span 才会实际的分配获取,不浪费空间。
tiny
我们已经知道,小于 16 bytes 的对象视为微对象,由于对齐、分页等原因,微对象更容易产生碎片。
为了尽量减少微对象所占用的空间,以及减少碎片,对微对象的分配会尝试放在mcache
的tiny结构中。
tiny实际上直接引用了alloc中
size-class=2,noscan的 span,这也就要求任何在
tiny中分配的对象都不能包含指针。
每一个 tiny 都以 16 bytes 为一个单元,16 bytes
分配满后,从 span 中获取下一个 16 bytes 单元。
tinyoffset指向了最近一次对象分配后的位置,tinyAllocs则代表当前已经分配了多少个微对象。
微对象按照其大小,以对 7 取模,对 3 取模,对 1 取模分别按 8,4,2
对齐,在 tiny中进行分配,正如图中,3 bytes 大小的 obj-1
分配后,1 byte 大小的 obj-2 需要在 offset=4 处分配。
与 alloc类似,假如 tiny 的 span 已满,就从
central 重新获取一个。
stackcache
stackcache 是专为分配栈内存而设置的。
从上一篇讲 go runtime 计算资源的文章中我们已经知道,goroutine 的初始栈大小是 2KiB,而每一次栈扩张都会将栈空间翻倍(详见后文)。
所以,对于较小的栈空间分配,在stackcache中按照所需空间的尺寸划分成
4
阶(linux 系统,其他系统阶数会有差异),每一阶的内存块分别指定为
2KiB、4KiB、8Kib、16KiB。对于小栈分配(小于
16KiB),根据所需空间大小向上取二次幂,然后从合适的阶中分配内存。
从图中我们会发现,stackcache 的每一阶都是一个 span
链表,实际上这些 span 都来自于一个全局的
stackpool,详细内容可见下文栈分配部分。
1.3.5 middle-end: central
central 的整体结构十分有趣,从宏观上看类似一个多级表,其整体结构如下图所示:

第一级:central
central 是一个全局数组,就像 mcache 中的
alloc 一样,数组的容量也等于 numSpanClasses 即
136,每一个元素存放了一个称为 mcentral 的结构。每一个
mcentral 都会与 size-class 绑定,前面我们了解过
mcache 后就已经能猜到,当 mcache 中某个特定
size-class 的 span,实际上就是从对应的 mcentral
里分配得来的。
第二级:mcentral
mcentral 的结构很简单,只包含三部分:
- spanclass:指代当前
mcentral存放的是哪一种 size-class 的 span - partial:是一个容量为 2 的数组,其元素存放的是第三级的
spanSet。在了解spanSet的详情之前我们可以简单从命名中推断它是 span 的集合。- 之所以叫 partial 的原因,是集合中所有的 span 都不是满的,都存在空间可被分配;
- 用两个元素维护两个
spanSet的原因,与 GC 清理有关:其中一个spanSet中存放的全部都是完成清理的 span,而另一个中存放的是未被清理的 span。每一次,GC 会将未清理的spanSet进行清理,之后该spanSet就变成已清理,而另一个spanSet则变成未清理。
- full:与 partial 的职责和功能完全一致,唯一的区别就是存放的都是已满的 span。
当 mcache 向 mcentral 请求 span 时,会先从
partial-swept (即 partial 已清理的
spanSet,下同)中尝试获取 span,如果获取不到就会从
partial-unSwept 中获取,但由于获取到的 span 还未清理,需要先清理后再供
mcache 使用。
假如还是获取不到,就只能从 full-unSwept 中进行尝试了,同样的,full-unSwept 中的 span 也需要清理之后才能使用。至于 full-swept ,显然又全满,又已被清理过的 span,压榨不出任何空闲空间了。
我们很容易想到,清理需要时间,而清理一个半满的 span 必定会比清理一个全满的 span 要快。
但是,一方面 GC 的后台清扫和mcentral 中申请 span
时的主动清扫可能会冲突导致只有一方能介入,另一方面对 full-unSwept
的清扫也可能什么空间都扫不出来。所以当在 partial-unSwpt 和 full-unSwept
中超过一定尝试次数仍无法找到 span 后,会直接去 back-end 中申请新的
span,以免过多的影响整个分配器的吞吐量。
最后,对于从 mcache 中归还的 span,已经被 GC
线程清扫过的,会视实际情况分别放回到 partial-swept 或 full-swept
中,而未被清扫过的 span,会先进行清扫,之后再进入 partial-swept 或
full-swept 中。(那什么时候 span 才会进入 unSwept 的
spanSet 呢?实际上 span 不会主动进入
unSwept,而是在开启新的一轮 GC 后,原来的 swept 就自动转换成了
unSwept。)
第三级:spanSet
spanSet 就是实际存放 span 的地方了,如图中所示,span
是紧凑的排列在一个称为 spine
的线性表中。进程启动之初,spine 中不包含任何
span,分配请求会直接从 back-end 处获取,而当 span 被归还时,就会进入
spine。
spine
所管理的空间以批量的形式进行扩张,每一批空间称为一个spanSetBlock。每一个spanSetBlock可存放
512
个 span(的地址指针),因此可知在 64-bit 平台下,一个
spanSetBlock 所需的内存空间是 512*(8 byte) = 4KiB,而一个
span 最少可持有 8KiB 的内存空间(可见前面的 size-class
表),所以可知,一个 spanSetBlock 以 4KiB
的空间成本,可管理 512*(8 KiB) = 4MiB 的实际空间。
spineLen 属性记录了当前spine 拥有多少个
spanSetBlock,初始情况下 spine 可以存放 256
个 spanSetBlock (的地址指针),这在 64-bit平台下需要
256*(8 byte) = 1KiB 的空间,假如还需要分配更多的
spanSetBlock,那么会重新分配一个新的容量翻倍的spine并且把原来
spine 中存放的 spanSetBlock 地址移动到新的
spine 里。
通常情况下,spine
都不需要自身扩容,我们可以简单的计算一下:一个
spanSetBlock可管理 4MiB 的空间,那么 256 个
spanSetBlock就可管理共 256*(4 MiB) = 1GiB
的内存空间,对内存需求量不太大的应用程序,这足够了。
最后,spine作为一个线性表,其 head 和 tail
是被放置在称为 index 的一个 uint64 中,高 32bit 放 head,低
32bit 放 tail。这里的 head、tail 都是指向实际
spanSetBlock中的 span 偏移量。对 index
的操作全部通过无锁的原子操作来完成。
1.3.6 back-end: heap
heap 内存划分
heap 作为 back-end 与 OS 交互,向下申请 OS 内存,向上为 middle-end 提供 span,虽然其整体结构相对复杂一些,但设计的也层次分明,井井有条。
由于 heap 需要管理整个 go 进程的内存地址空间,因此引入了几个概念,层层递进的描述地址空间中的内存。
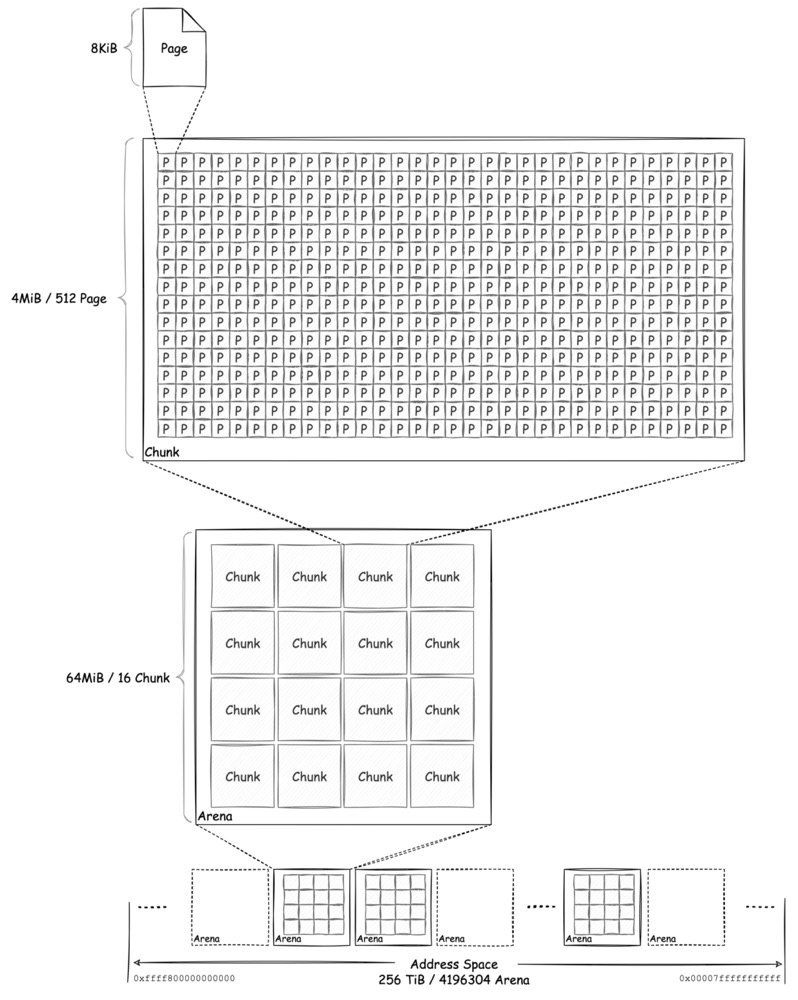
如上图所示,从最下面开始,整个地址空间,被划分成了 Arena,Chunk,Page。注意这些概念都是逻辑上的划分,实际对内存的操作仍旧是通过内存地址。
以 amd64 架构下的 linux 为例,整个地址空间是从
0xffff800000000000 ~ 0x00007fffffffffff 的共 256 TiB
空间,go 的整个地址空间与之保持一致,但实际上参考内核文档可知,进程的地址空间是
0x0000000000000000 ~ 0x00007fffffffffff 的 128 TiB
空间。
要管理在如此庞大的地址空间中分配的内存,必须要从大拆小。
Arena 是一块可包含 64 MiB 的逻辑区域,整个地址空间总共可划分为 4196304 个 Arena,而 heap 每一次向 OS 申请内存也都是以 Arena 为单位的。
64 MiB 的空间对细碎的应用程序内存分配而言还是太大了,将一个 Arena 拆分成 16 份,每一份 4 MiB,称为一个 Chunk。这样 heap 管理自己从 OS 申请来的 Arena 时就可以通过 Chunk 为单位,这样更精细。
最后,我们从前面已经了解到,应用所需的内存在 front-end 和 middle-end 中以 span 结构来管理,而每一个 span 中会包含 n 个 Page。每一个 Chunk 中可包含 512 个 8KiB 的 Page,在 back-end 向 middle-end 提供 span 时,分配的 Page 就是从 Chunk 中而来的。
管理 Chunk
前面我们已经知道了 heap 中对内存的划分方式,引入像 Arena,Chunk 这样的逻辑概念,是为了帮助我们更高效的管理内存。那么我们立即就会想到一个问题:heap 如何管理 Arena?如何管理 Chunk?
对于 Chunk,heap 将之作为向 middle-end 分配 span
的来源,其主要的管理是通过称为 pageAlloc
的页分配器来实现的。
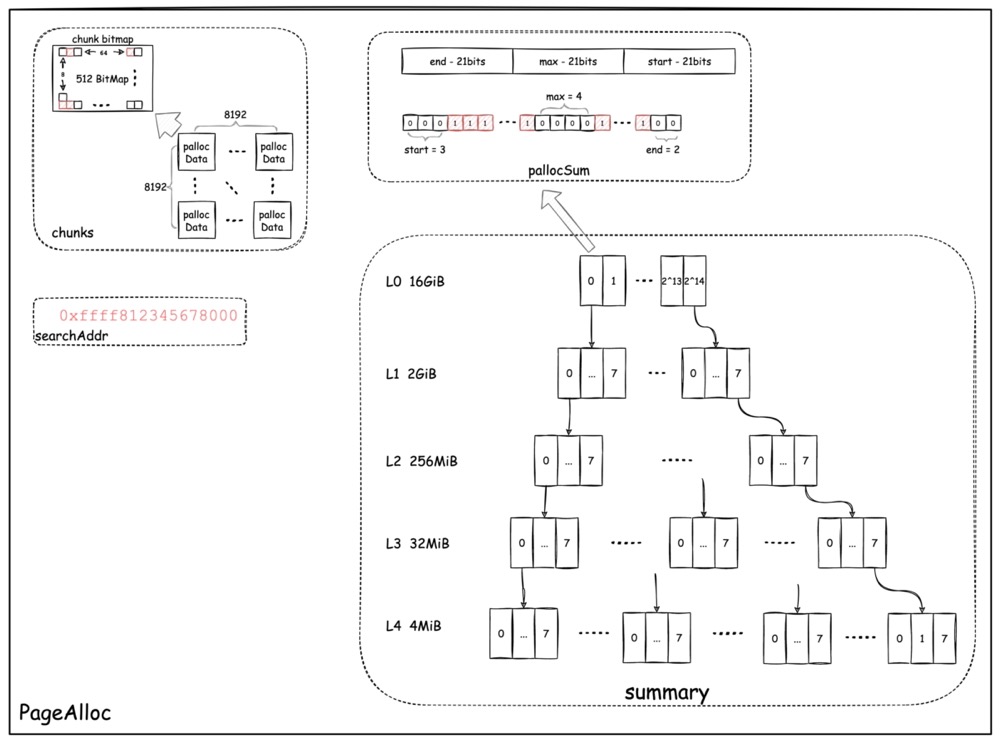
上图所示的就是 pageAlloc 的主要组成部分了。
pageAlloc 的主要工作就是尽可能快的为 middle-end
提供大小为 n*page 的内存空间,用来组装 span。这里涉及到两个问题:
- 如何快速找到 n*page 的连续的空闲空间?
- 空间不足时该怎么办?
首先来看第一个问题:
在前面 span 的介绍中我们已经见到了,span 利用 bitmap 来记录其每一个 slot 的占用/空闲情况。bitmap 的优势就在于可以通过消耗很少量的空间来指示出很大范围空间的使用情况。
在 pageAlloc 中也不例外,每一个 Chunk,其内部的 512 个
Page 是否被分配出去的具体情况,也是采用 bitmap 来表达的(0 表示该 page
空闲,1 表示该 page 被占用)。
如图左上角的 chunks,实际上是一个 8192*8192
的稀疏矩阵(二维数组),数组中每一个元素称为pallocData,每个
pallocData 都通过一个 [8]uint64 代表一个 Chunk
中的 512 个 Page。 简单的计算就可知,每一个 Chunk 4 MiB,8192*8192*4 MiB
= 256 TiB,因此 chunks 表示的是整个地址空间中所有 Chunk 的
bitmap。
假如采用一维数组来表示,那么使用了 8192*8192 个 64 bytes 大小的
[8]uint64 的 chunks 本身就会占用 4 GiB
的空间(实际上每个 pallocData 还包含了一个 64 bytes
大小的页清除 bitmap,空间占用翻倍到 8
GiB),这完全不可接受。但实际上整个地址空间中我们真正用到的部分很少,所以整个
8 GiB 空间中,绝大多数的 bitmap
都是无意义的。使用二维数组实现的稀疏矩阵,只有当矩阵的某一行中有任意多个
Chunk 被使用到了,才会一次性分配一行的空间(1 MiB),结合 go
内存分配尽量保持聚集的特性,实际使用的 chunks
就不会很大。
有了 bitmap 我们就能通过遍历它来找到想要的连续空闲空间了。但每次都从头开始遍历 n 个 bitmap,效率会比较差。
首先,pageAlloc 引入了一个值 searchAddr
,代表每次搜索的起始地址,这个值会在每一次分配后被更新为分配地址后的第一个空闲地址位置。有了
searchAddr,在查找时就不用从头开始遍历chunks,而是直接通过
searchAddr 找到该地址所在的 Chunk bitmap 再查找。
但不幸的事常用,每次分配的内存大小都不同,如果
searchAddr 所在的 Chunk 里面不足以满足连续的 n*page
内存需求,就只能再次从头开始查找了。为了让从头查找变得更快一些,pageAlloc
又引入了名为 summary 的 radix tree,加快查找。
上图右侧展示的树,就是summary。这一课 radix
tree,共五层,每一层都通过不同个数的 entry
来表示整个地址空间,越向下层,entry 所表示的地址范围越小,而 entry
的总数越多。
最上层总共只有 2^14 个 entry,每一个 entry 将表示 16 GiB 地址范围,正好覆盖了总共 256 TiB 空间。在接下来的 4 层中,每个 entry 都向下对应到 8 个 entry,所以从第二层开始每层的每个 entry 分别表示 2 GiB、256 MiB、32 MiB、4 MiB 的地址范围。
那么,entry 到底表示了地址范围内的什么东西呢?每一个 entry
都是一个被重定义名为 pallocSum 类型的 uint64 数值。
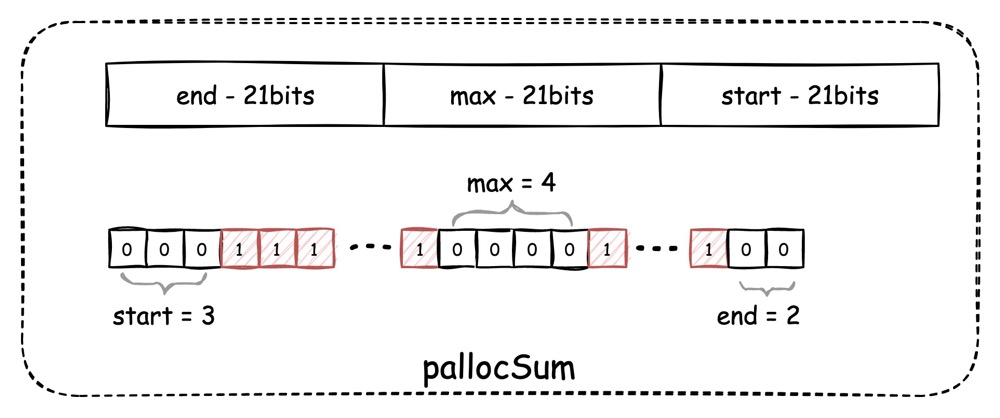
如图所示,每一个pallocSum 实际上是由 3
部分组成,从低位开始分别是:start、max、end,每一部分都占用 21bit。
图中下半部分是一个 bitmap 的示例,可见,start 和 end 分别代表 bitmap 中开头和结尾处 0 的个数(0 代表空闲),而 max 则代表当前 bitmap 中最长的连续 0 的个数,代表最长空闲段有多少个 page。
通过 max,我们就能描述出一段地址空间中,最长可以分配多少连续页,而通过 start 和 end,我们就能描述出两个地址空间交界处,最长可以分配多少连续页。这样当我们搜索时就可以快速的判断当前地址空间下有没有符合要求的连续页。
以首层每 entry 16 GiB 的地址空间来计算,16 GiB 可换算成 2097152 个页,1 << 21 正好等于 2097152,所以 21bit 宽度就足以表达 16 GiB 空间中的最大 page index。
因此,对summary
的搜索,实际上就是一个不断缩小范围的过程,只要能找到符合要求的连续页的确切
index,就能换算出地址。用radix tree
来加速查找的本质是将查找成本摊销在每一次更新中,因此为了维护这棵树,每一次内存分配过后,都要更新树中受影响的entry。
第二个问题就相对简单:
当 pageAlloc 在查找空间时发现目前纳入管理的 Chunk
中已经难以分配出所需要的空间了,那么它就会尝试向 heap 再申请至少一个
Chunk 来满足需要(如果是大对象分配,可能需要多个 Chunk)。
heap 会通过 OS 抽象层(为了兼容各种不同的 OS 而抽象出的几个通用的内存分配/释放操作)来尝试分配一个 Chunk 的空间。而实际上在 linux 的 OS 抽象层实现中,分配内存的单位会被扩大为 Arena,所以一次性就分配了至少 1 个 Arena 的空间。
管理 Arena
在分配 Arena 的时候,go 不是直接任由 OS 分配一个随机地址,而是会在进程启动时,就划分好所有 Arena 的地址范围(64bit 和 32bit 下略有差异,这里主要描述 64bit 的设计)。

上图展示的是 mheap 的主要结构,其中有一个链表
arenaHints 就是用来记录已划分好的地址段。
对于 amd64 架构,Arena 的起始地址定为 0xc000000000。每次分配
Arena 时,会先尝试从 arenaHints 的头结点所示位置处尝试向 OS
申请,如果 OS 报告该地址处申请失败,则跳到下一个节点所处位置处尝试。
从图中我们能看到每一个arenaHint 的初始地址空间差额是
0x10000000000,即 1 TiB。通过
arenaHint,就可以确保大部分内存都会按地址连续的进行分配。
除此之外,在 mheap 中还用 allArenas
切片来记录所有已经分配过的 Arena index,以及 curArena
来记录当前 Arena 已分配的地址范围。
左上角的 arenas 是和前面 pageAlloc 中的
chunks 类似的 bitmap 矩阵,只不过在 64bit
架构下只有一维。这里每一个heapArena都记录了一个 bitmap,该
bitmap 不是用来指示内存占用情况的(chunks
里面已经记录过了),而是用于 GC,后文会详述。
同样的,arenas 也是稀疏的,从它所记录的是
heapArena 的指针就可知,未分配的 arena 处,地址为
nil,否则才是真实的 heapArena 所在地址。
OS 内存管理抽象层
Go 为了能方便的适配不同的 OS,构造了 OS 内存管理抽象层的概念,不论哪种 OS,go 向他们申请的内存都会处于如下任意的一种状态:
- None:未保留也未映射,所有内存区的默认状态
- Reserved:逻辑上已经被 go runtime 持有了,但任何应用对其访问都会报错,这部分内存也不会占用任何 rss
- Prepared:对 Reserved 内存做准备性工作,以便于快速切换到 Ready,任何应用对其的访问可能报错也可能返回零
- Ready:可以安全的访问
对于这四个状态,提供了几个需要根据具体 OS 来实现的抽象函数,调用这些抽象函数,可以在上述四个状态间转换:
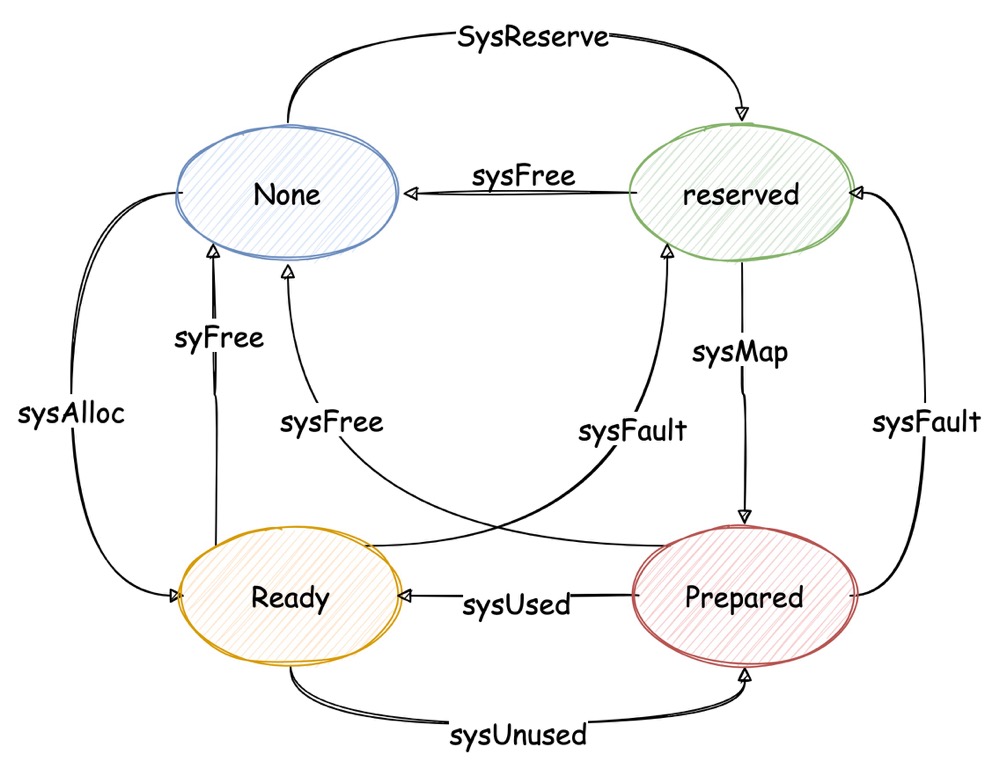
对于 Linux:
sysAlloc:直接调用mmap,且不指定 address hint,prot= READ | WRITE,flag = ANON | PRIVATE,因此可见确实执行了sysAlloc后可以直接使用sysReserve:调用mmap,指定 address hint,但prot= NONE,因此这部分内存不可访问。此外flag = ANON | PRIVATE | FIXED,fixed 参数要求 OS 必须返回给定的地址,否则报错。所以结合前文,在arenaHint处申请内存,就是通过调用sysReserved,而如果出错,可以选择下一个arenaHintsysMap:调用mmap,指定 address hint,prot= READ | WRITE,flag = ANON | PRIVATE | FIXED。按流程,调用sysMap之前已经已经调用过sysReserve,所以如果这时 OS 再报错就一定是致命错误,进程会被终止sysUsed:在 Linux 下,并不存在 commit 这样的申请动作,所以该函数没有太多意义,但 Windows 下很重要。Linux 下只是通过madvise在给定地址空间内开启透明大页sysFree:简单调用munmap
PageCache
我们现在已经知道,当 middle-end 无法在限定次数内从 partial-Swept、partial-UnSwept 以及 full-unSwept 中获取到空闲的 span 时,就会直接到 back-end 这里申请 span。
我们能确认的一点是,直接在 back-end 分配 span 是很昂贵的:
mheap和pageAlloc中的状态都是全局共有的,因此任何操作都要加锁- 通常 span 中包含的 n*page 都比较小(至少远小于
Chunk),大费周章的下探到 back-end 层申请几个 page
的内存,申请过后还要修改 Chunk bitmap,和
summary
因此,借鉴了mcache 的办法,go 在每一个 P
内又放置了一个称为 PageCache
的结构,这样,先前的内存分配器架构就可以更新为如下:
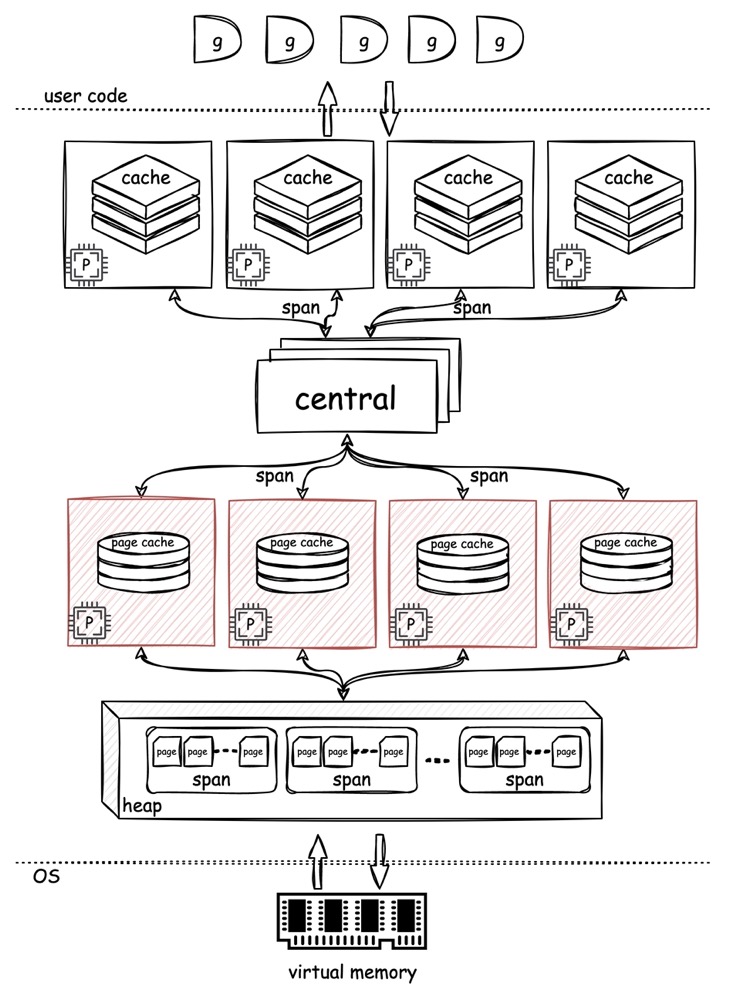
- 和
mcache一样,访问PageCache不用加锁 - 每次填充
PageCache时会直接通过pageAlloc分配连续的(注意不是连续空闲的) 64 个 Page 放入PageCache,避免了频繁的小量分配
在从 pageAlloc 中向 PageCache
填充时,会直接寻找到有任意一个 page 空闲的 Chunk,对这个空闲 page
所处位置按向下 64 页对齐后得到一个完整 64
页的起始地址,作为PageCache 的起始地址。之后会将这 64
页所对应的 Chunk bitmap 一起交给 PageCache 用于查找空闲页和
GC。
2. Go 的内存划分
前面介绍了 Go 动态内存分配器的内存分配原理,这一节我们从应用的角度介绍 Go 对内存的划分以及使用情况。
2.1 进程内存
不论 Go 在 Runtime 中如何组织 goroutine 的内存布局,从操作系统的视角来看,加载一个 Go 可执行文件,与加载其他可执行文件没什么区别,最终都会以进程的形式运行在操作系统上。
因此在具体分析 Go 自己的内存布局和管理之前,我们先来回顾一下 Linux 的内存布局(图源:CSAPP Figure 9.26):
Linux 进程的实际虚拟地址空间,从 0x400000 开始(代码段起始位置,更前的地址未做映射),到栈区高地址结束,更高的地址空间留给内核。
进程内存段从低地址开始分别被划分为:
- 代码段
.text - 已初始化数据段
.data - 未初始化数据段
.bss - 运行时堆
heap - 共享库内存映射区
mmap - 运行时栈
stack
上述各分段的意义不再赘述,我们任意找到一个运行中的进程,通过访问
/proc/{pid}/maps 来看一看实际的内存布局:
1 | [root@xxx ~]# pmap -X 1410 |
前面是一个简单的 sleep 进程的内存布局,主要作为一个基准,用于和 Go 进程作比较。
现在来看一看一个 Go 进程的内存布局:
1 | [root@xxx ~]# pmap -X 11564 |
从上面两个不同进程的内存布局中,我们能发现几个有趣的地方:
- sleep 有
[heap],go 进程没有[heap]?- 对于
Mapping = [heap],只有当程序使用brk()分配堆内存后才会显示,以mmap()的形式分配的内存不显示为[heap] - sleep 属于 glibc 库,glibc 默认的 ptmalloc 初始化时会通过
brk()分配 132KiB 的堆空间 - 前文已经提到了,go runtime 使用的内存分配器,是完全采用
mmap()来分配内存的,没有调用过brk(),也就不显示[heap] - 仍然依据前文可知,
ArenaHint的起始地址就是c000000000
- 对于
- 为什么
[stack]的默认容量是 132KiB?- Linux 在执行 exec 时,初始化栈空间的逻辑中为栈顶分配了
PAGE_SIZE的空间,amd64 架构下 linux page size 默认是 4KiB - 在之后的
setup_arg_pages()中,对栈进行扩展,扩展容量是硬编码的 128KiB,4 + 128 = 132KiB,上面两个进程对栈的使用都没有超过 132KiB,所以[stack]都是 132KiB - 后文会提到,goroutine 的栈内存,也都是从内存分配器分配得来的,即都从
mmap()而来,只有主进程所在的 g0 栈直接使用系统栈,但 g0 限制了栈空间最大 8KiB,不会超出 132KiB
- Linux 在执行 exec 时,初始化栈空间的逻辑中为栈顶分配了
2.2 栈内存
在本系列上一篇中,我们已经知道,goroutine 持有自己的运行栈。
栈在创建 g 的时候需要一并分配出来,在销毁 g 的时候也需要一并清除掉。那么 go runtime 是从哪里为 g 分配栈内存的呢?
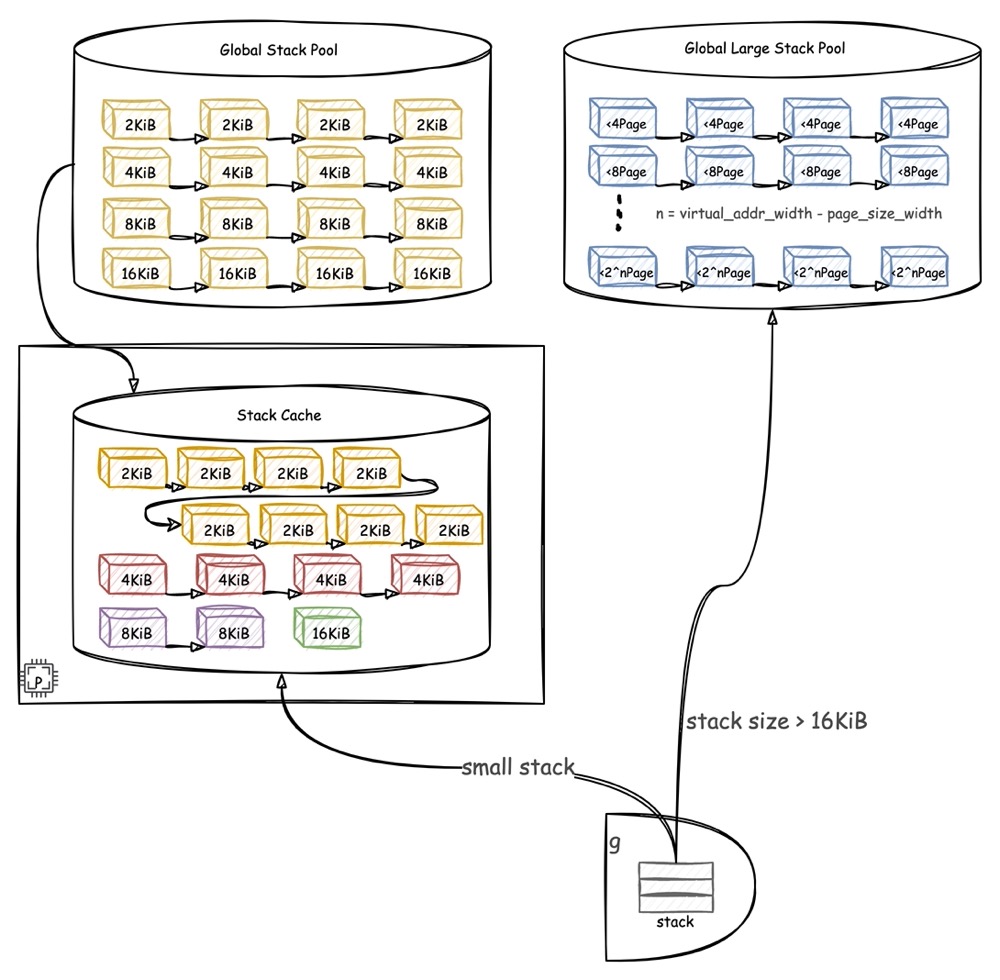
上图展示了 g 的栈分配结构,在分配栈内存时,首先需要根据栈空间的大小来决定是从哪里分配。
- 对于较小的栈,直接从当前 P 持有的
mcache中的stack cache分配 - 假如需要分配的栈空间比较大,就会选择直接从全局的
large stack pool中进行分配
1.3.4 节已经讲过,stack cache 中的空间按照尺寸被划分成 4
阶(linux 系统,其他系统阶数会有差异),每一阶的内存块分别指定为
2KiB、4KiB、8Kib、16KiB。对于小栈分配,根据所需空间大小向上取二次幂,然后从合适的阶中分配内存。
stack cache
由于小栈空间占比小,分配的频次也比较频繁(创建 g
默认栈2KiB,之后逐步扩容),因此从 stack cache
中分配栈,不需要加锁,速度快。
stack cache 中每一阶的总容量最大不超过
32KiB,超出后会释放一半,剩
16KiB。而当分配时发现某一阶缓存为空,则会从全局的stack pool
中分配总量为 16KiB 的空间放入缓存。
stack pool
定义了全局的小栈空间池。按照四个阶存储四条链表,用来保存固定大小的可用内存块。
当 stack pool 中可用空间耗尽后,会一次性从
mheap 中(直接从 back-end
分配,完全没有经历其他两层分配的过程)申请一个包含了 32KiB 内存的
mspan,并按阶切分成小块,插入链表,作为
stack pool 的新空间。
large stack pool
从前面可知,小栈空间单个最大空间块是 16KiB,所以如果需要超过 16KiB
的栈,就需要从 large stack pool 中申请。
与小栈类似,存放大栈的large stack pool
也会分阶对内存块进行管理,只不过不再是按照 2 KiB 的幂次划分,而是按照 2
* Page 的幂次逐次递增。Go page size == 8KiB,由于内存需求至少要 16 KiB
才会进入大栈分配,因此最少会分配 2 * Page。之后随着容量的增大,在 linux
下最高可以分配满 48bit 用户地址空间,即 2^35 个 Page。
对于大栈空间,当large stack pool
对应阶链表中不存在所需内存块时,也会直接从mheap 分配 nPage
的空间,待栈释放时,将该空间加入
large stack pool中备用。
goroutine 栈扩缩
在前一篇文章中,我们已经知道大部分 go 函数在调用前会先通过
morestack
函数检查是否发生栈空间不足,这一部分我们来具体看一看在发生栈空间不足之后,go
是如何对栈进行扩容的。
可以设想在某个 goroutine 被创建后,为其初始化了一个最小的(2KiB)默认栈。随着函数的不断调用,保存的参数、返回值以及局部变量越来越多,导致在某一次函数调用时发现索引的栈地址超出了
stackguard 的值,这表明当前栈已满。
解决栈满的问题,有如下几种办法:
- 基于当前栈空间首地址,继续向后尝试分配更多的连续空间
- 离散的分配一段新空间,与当前栈串联起来,可称为分段栈(split stack)
- 开辟一块新的更大的空间,把当前栈的全部内容复制进去,可称为连续栈(contiguous stack)
由于内存分配的随机性,随着需要连续空间的逐步增大,第一种办法局限性太强。
老版本的 go,采用的是分段栈设计,而在连续栈的设计文档中,解释了分段栈实现当中存在的几点问题:
- hot split 问题:对于一个即将占满的栈,微小的栈分配(比如函数调用)就会导致栈扩张,分配新段,而当函数返回时,栈被回收,又需要收缩。如果是在循环里调用函数,这种开销会被显著放大。
- 不论是申请还是释放空间,只要跨越了扩张/收缩门限,就会触发段的申请/释放,只要触发申请/释放,就会产生额外的工作
采用连续栈的设计,就可以避免上述两个问题。

连续栈在实现上,除了复制扩容的动作外,还需要考虑的就是指针地址的问题:栈挪动到了新的内存上,所有绝对地址都会发生改变。
由于 go 的逃逸分析机制,可以保证:任何指向栈上数据的指针,都只可能顺着调用树向下传递(调用栈更深处的指针指向更浅处的数据)。不满足该要求的任何数据都不会被分配在栈上。基于此,就很容易能追踪到栈上的指针,并在栈复制后调整它们的地址值。
2.3 堆内存
堆内存的分配,完全按照分配器所划分的层次,从 front-end 开始尝试分配,并根据实际情况逐步下沉,其主要流程如下:
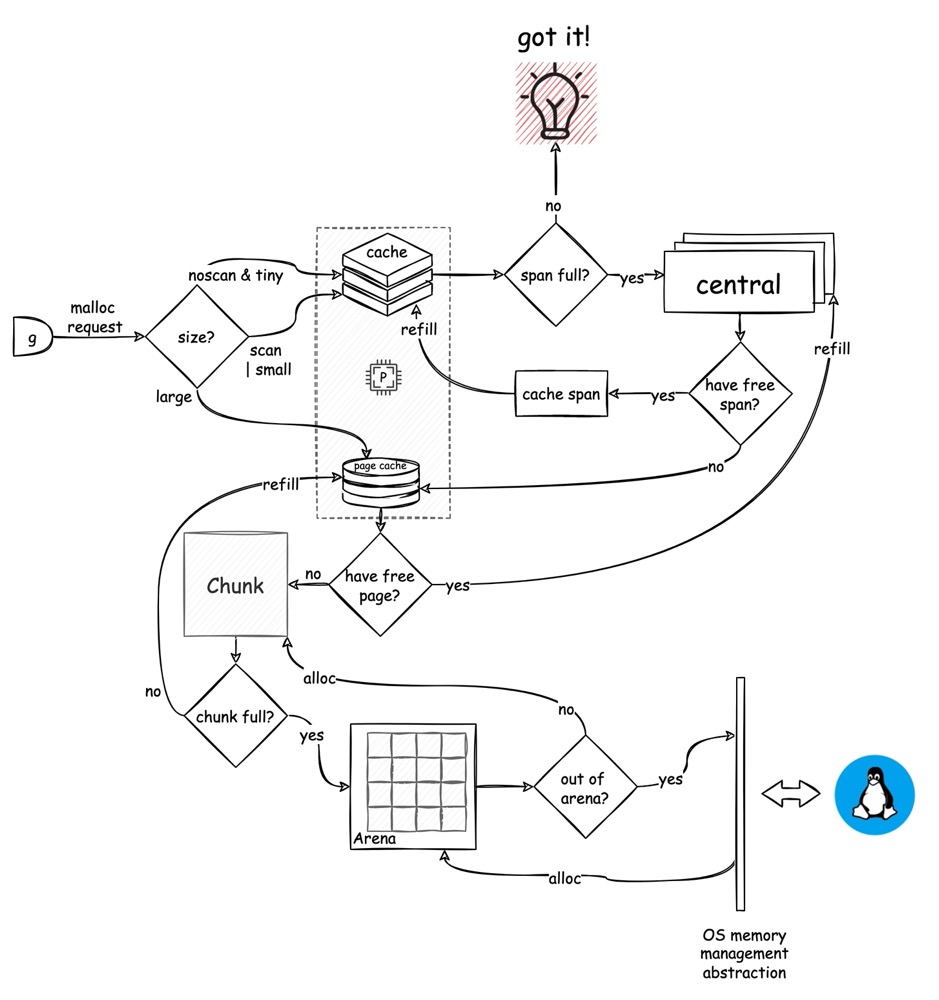
- 根据需要分配的内存大小,小内存从
mcache中分配,大内存直接从 heap 中分配 - 不包含外部指针,且足够小的内存,从
mcache的 tiny 中分配,否则正常从alloc中按 size-class 选取 span - 若
mcache空间不足,则根据 size-class 选择对应的mcentral并向mcache填充对应的 span - 若
mcentral也空间不足,就需要要根据需要的 Page 数量,下沉到 heap 进行分配 - 在 heap 分配时,首先会到 P 中的
PageCache尝试,不用加锁 PageCache空间不足,就需要通过pageAlloc找到某个合适的 Chunk,并对PageCache进行填充- 若
pageAlloc找不到合适的 Chunk,则需要从当前 Arena 中获取新的 Chunk - 如果当前 Arena 也已经全部分配出去,那么就需要通过 OS 内存管理抽象层向操作系统分配合适数量的 Arena
2.4 堆外内存
通过前面的内容我们知道在 goroutine 中,内存可能会被分配到栈或堆中。不过这里讲的都是应用代码中内存的分配位置。
然而,不论是 mcache mcentral 和
mheap ,还是
Arena,Chunk,他们本身也需要内存空间来存放各种状态、中间变量等等(比如
bitmap),这些结构如果也要分配到堆或栈中,就出现鸡生蛋还是蛋生鸡的问题了。
实际上,这一类与 runtime 本身相关的结构,大都是分配在 “堆外内存” 中的。这里的堆,指的就是 go runtime 的堆,而不是进程的堆。
从前面我们已经知道,runtime 的堆是通过 arenaHint
来尽可能的限定堆内存紧凑的分配在一起。下沉到 OS 抽象层,就是通过
sysReserve 和 sysMap 来向 OS
申请给定地址处的内存。
但对于堆外内存,没有地址的约束,因此可以直接通过
sysAlloc 来分配,由 OS 选择分配的位置。
基于 sysAlloc,runtime
又封装了一些辅助结构来应对不同类型的堆外内存需求,下图展示了它们之间的关系:
fixalloc:每一个fixalloc都会分配固定大小的内存,其 size 在初始化时决定- 用于分配具体的某种结构,如
mspan、mcache、arenaHint - 每一种需要在堆外分配的结构都对应了一个
fixalloc - 空间不足时从
presistentAlloc处一次性申请16KiB的空间,称为fixedChunk
- 用于分配具体的某种结构,如
persistentAlloc:用于分配相对固定的、生命周期与整个 go 程序一致的内存,不提供内存释放方法sysAlloc:直接向 OS 申请内存,返回地址由 OS 给定- 可用于分配较大的对外内存,如
chunks中的pallocData,每个需要128KiB空间 - 可用于分配与 OS 相关的内存,如在创建 OS 线程时指定线程栈地址
- 可用于分配较大的对外内存,如
通过上述堆外内存的分配器,runtime 内置的一些结构就能正常的动态分配到内存中,支撑堆和栈的相关功能。
堆和栈可用后,runtime 内置的其他结构也就能直接在其中分配了,例如
g、m、p
结构就直接从堆上分配。