构建可扩展的平台工程软件栈架构

本文介绍了企业在构建平台工程能力时如何通过可扩展的软件栈架构来满足多样的场景与诉求。
平台工程的诉求和演进
平台工程(Platform Engineering)是一种设计构建工具链和工作流的工程实践。企业通过设立小规模的平台工程团队,建设 IDP 内部开发者平台(Internal Developer Platforms)使研发团队在 DevOps 实践上更易于达成 DORA Metrics 所描绘的高效能团队要求。
实际上,很多人在了解到平台工程这一概念后,都会心生疑惑:“平台工程是个新概念吗,听着耳熟啊?”,“这不就是我们公司的 xxx 平台吗?(这里的 xxx 平台可能是 研发管理平台 / DevOps 平台 / 开发者平台 / 一站式运维平台 等等”。
的确,至少在笔者所经历过的雇主、客户中,就接触过不下五个类似的平台,虽然它们的名称代号各不相同,但至少都会提供包括代码仓、CI/CD 流水线、配置中心、资源管理等基础能力,业务研发团队基于此实现了一定程度的交付自动化。
那有了这些基础能力,是否意味着企业的 IDP 就建成了呢?并不是。
平台工程是为了让企业更易于触及高成熟度的 DevOps 实践而诞生的,许多企业没有精力和人才来构建整个 DevOps 体系(工具、流程、文化以及组织变革),就只好先从便宜收效快的地方入手:从运维团队抽调几个人,搭一套开源方案就能凑合用。但这些零散的工具和脚本除了提供一定程度的自动化能力外,并不能真正让研发人员从 DevOps 的工作中解放出来(“扯淡的DevOps,我们开发者根本不想做运维!”)。
我们观察到,有能力通过构建平台实现高 DevOps 成熟度的企业,的确都是大型企业居多,它们为此投入了可观的资源。这类企业通过在内部搭建完善的平台、工具甚至基础设施,推行全公司一致的研发流程和团队管理实践,构建复杂的指标体系来评估研发团队并与绩效挂钩,自上而下的推动 DevOps 能力提升。
然而绝大多数企业都无法承受如此规模的投入,那么平台工程实践只能是大企业的专利吗?
在这篇 What Is Platform Engineering 中提到,只要组织规模达到 20~30 人,就可以开始关注 IDP 了。这一观点引发了我们的思考:投入受限下的平台工程建设,期望得到怎样的收效呢?
小型企业对平台能力的主要考量点在于基本可用 + 成本最低,尽量使用便宜甚至免费的服务是明智的选择。因此小企业更容易接受 SaaS 解决方案,例如 Github Pro、Coding 等。这一阶段平台的主要工作就是通过集成 SaaS 服务来满足业务需求,同时设计抽象层来避免过度绑定。
而当企业达到一定规模且处于高速发展期时,就会更关注软件交付以及平台工程能力扩展的速度。毕竟高速发展的业务需要平台支撑其快速试错和占领市场,也要求平台能更快的扩展新功能以匹配业务的发展。这一阶段平台设计的重点是提高响应能力,完善扩展性。
最后,对于大规模企业,它们更倾向要求合规、稳定和降本增效。为了支撑这些需求,平台在使用上要简明易用,上手门槛低,并且故障率低;在应用调度上需要支持跨云、跨区;而在资源的使用上要求减少浪费,节约成本。这阶段的建设目标更多体现在对用户体验的提升,和对基础设施的掌控力。
据此可见,平台工程能力建设的诉求,在企业的不同规模、不同发展时期下都不同。那么企业在设计内部开发者平台的整体架构时,如何才能满足不同的诉求呢?下文将介绍基于标准分层抽象而构建的模块化软件栈架构设计,其能够释放平台的可扩展性和可演进性。
可扩展的平台工程软件栈架构
软件栈(或称解决方案栈)是通过一组软件子系统来构建完整的平台,在该平台之上可以运行特定的应用程序。这种基于抽象分层的栈模式在软件工程中十分常见。
在构建平台工程能力过程中,将企业需要自研的部分尽可能收敛和内聚,通过设计标准抽象层,并借助开源社区的力量,设计分层、可扩展、组件化的软件栈架构,以充分应对平台建设过程中在成本和功能上多变的场景化诉求。
基于上述思想,设计自上而下的抽象层,在层内组合多种开源组件,即可构建可扩展的平台架构,如下图所示:
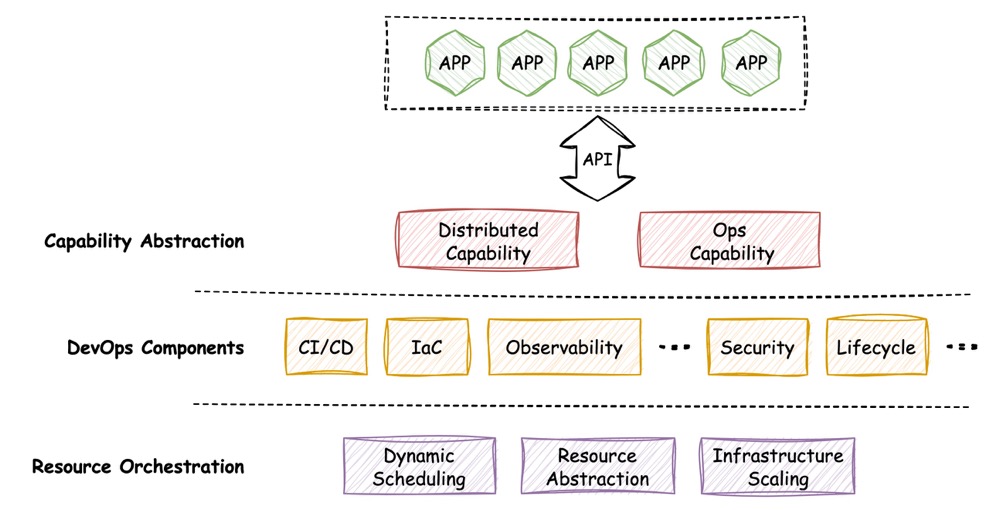
以下将分别介绍每一层的职责和扩展能力。
可扩展的能力抽象层
作为平台架构的最上层,能力抽象层最核心的目标是通过提供合理的抽象与接口,让应用在开发态和运行态都能更关注于业务本身,而将运维能力侧和公共组件侧的需求尽可能代理出去。通过能力抽象层提供的各种抽象能力,应用研发团队只需要对应用所需公共能力和运维的需求进行定义,之后可放心的将配置和实施的工作交给平台,从而节省大量原先需要做的 DevOps 工作和时间。
因此,能力抽象层的设计,在应用运维需求侧,考虑构建标准化可扩展的应用运维模型,而在公共能力的需求侧,考虑构建通用的公共能力抽象。
统一应用模型
通常意义上,应用在 Day2 阶段的持续时间要远大于 Day0 和 Day1,这也就导致了交付和运维的工作是繁杂和冗长的。软件部署早已不是把包丢到服务器上然后启动进程就完事,还包括配置管理、服务拓扑、副本扩缩、流量分发、监控、审计、成本优化等各种要求。
通过定义一套标准的应用交付模型,可以将应用开发团队和平台团队的关注点进行分离,由开发者定义特定应用在交付和运行中的需求,由平台团队来实现这些需求。
OAM(Open Application Model)就是这样的一种模型标准。
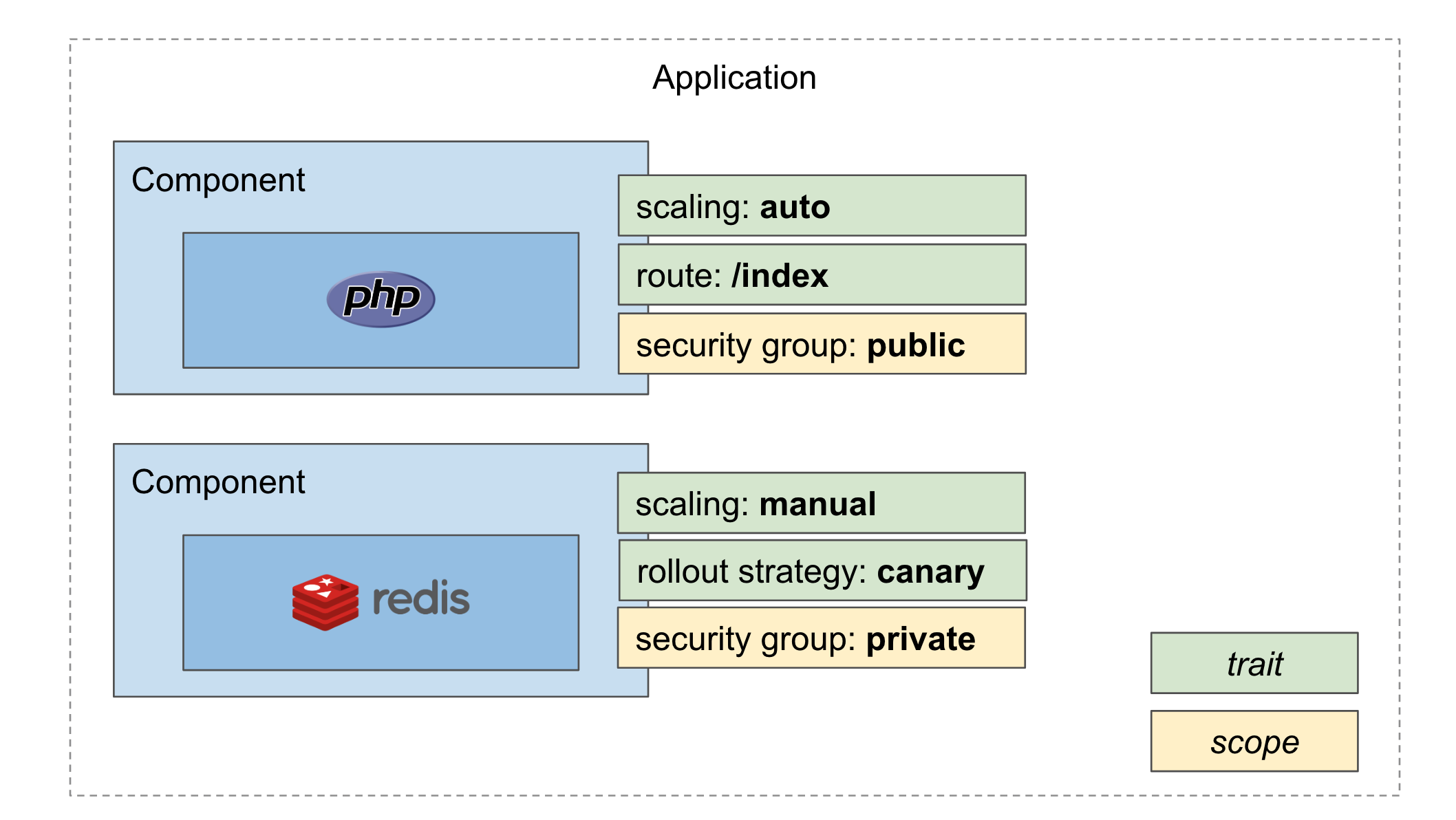
平台团队提供 ComponentDefinition
来描述不同应用的部署模型,如 "通过 K8s Deployment
部署的无状态后端服务","直接推送 CDN 的静态前端页面"
等。应用开发者只需挑选某个 Component
来描述应用,并设置一些属性参数,如镜像名、ENV、端口号等等即可。
同时,平台团队还提供了对 Traits 和 Scopes
的定义,这允许开发者为他们的应用添加运维特征如动态扩缩,灰度发布,负载均衡等,以及分组特征如安全组,AZ等。
因此,开发者只需要将应用模型以类似 yaml
的形式维护在代码仓内,随着 GitOps
流程,应用就会顺滑的交付上线。
通过 OAM 的抽象隔离,对应用团队提出的各种运维诉求,平台团队可以灵活的采用各种手段来实现,实现方案也能灵活的替换和扩展。
KubeVela 实现并扩展了 OAM
分布式能力抽象
在成规模的服务化体系中,应用可能依赖了越来越多的中间件以及三方服务,它们提供了应用实现业务目标所需要的各种分布式能力。然而,传统的 SDK 集成方式让这些分布式能力变成了一个个的孤岛,难以统一治理,导致维护困难、升级困难,降低了整体的研发效率。
平台可以将各种分布式能力进行归类和抽象,为应用提供统一的分布式能力抽象层,因而应用只需要通过抽象层调用标准化能力,由平台团队维护实际的能力实现组件。
多运行时架构就是基于上述思想提出的解决方案:
在多运行时架构的理念中,将各种分布式能力归纳为 4 个部分:生命周期、网络、状态以及绑定。传统场景下,这四大能力是由各类基础设施和中间件来提供的。
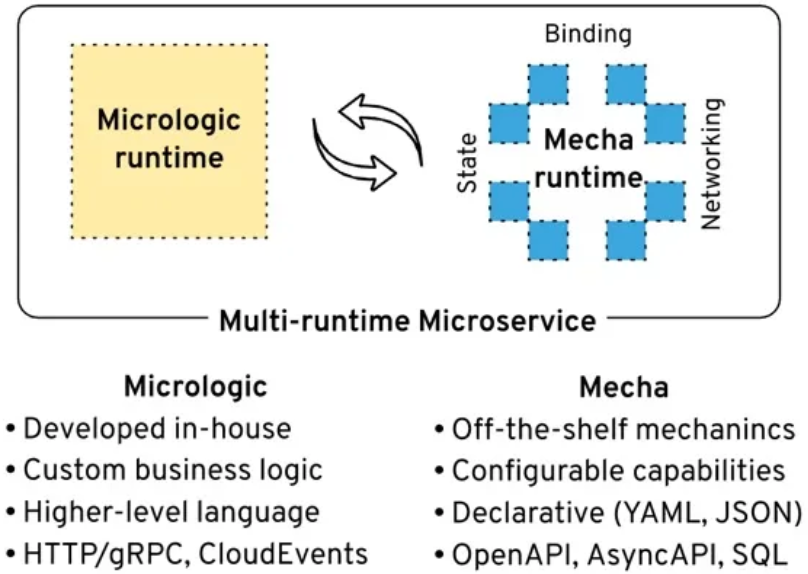
通过Mircologic + Mecha,即微业务与所谓“机甲”相组合的方式,将业务对分布式能力的需求全部交给
Mecha 运行时来代理,而真实提供分布式能力的组件,通过 Mecha
与业务应用隔离。
平台通过为每一个业务应用提供 Mecha 运行时,隔离了需求与实现,因此能够方便的对各种中间件进行维护和扩展。
可扩展的 DevOps 组件层
得益于能力抽象层对应用需求的抽象,在 DevOps 组件层,平台团队可以放心大胆的提供和尝试各类工具和实践。同时,在丰富的 DevOps 组件生态中,也形成了许多标准化协议和流程,让各类组件本身也能灵活扩展。
云原生不仅让应用获得了高度灵活的资源利用和弹性能力,也为基础设施侧组件提供了标准化的运行环境和管理方法,因此 DevOps 组件层提供的组件也默认采用云原生的方案。
CI/CD
DevOps 组件层所提供的最基本能力应该就是 CI/CD Pipeline 了。通过 Pipeline 来拉取 Repo 中的代码,并一步步的执行编译、检查、测试、部署、发布,这可能是企业尝试 DevOps 工具的第一步。
CI/CD Pipeline 的运行,本质上是执行了一个 DAG,各个阶段具体做的事情只是挂载在 DAG 节点上的细节。因此大多数的 CI/CD 工具都实现了 Workflow Engine。
可以基于 DAG 来定义标准的 Pipeline 抽象,在不同的抽象工作节点上执行编译、检查、运行测试、打包等任务,具体的工作节点实现可自定义方案。
上一节提到的实现了 OAM 的 KubeVela,就基于 OAM 模型扩展了 Workflow 的定义,通过 Workflow,可以将 Pipeline 的部分直接集成在 OAM 模型当中,KubeVela 对 CI/CD Pipeline 的抽象称为 Unified Declarative CI/CD。
资源管理 + IaC
业务应用通常会依赖大量 PaaS 中间件服务,通过公共能力抽象,应用开发者不必关心具体中间件的实现和维护。但对于平台团队而言,大多数 PaaS 服务都是非 K8s 环境的,企业可能会维护大量 IaC 脚本来实现对资源的自动化操作,但想要将它们纳入云原生环境下统一管理仍需要可观的人力付出,尤其是在跨云场景下更加复杂。
Crossplane 正是为了解决这一问题而诞生。

Crossplane 通过 Provider 实现对具体 PaaS
资源的操作,在其官方市场中已经有数十家 CSP
开发的 Providers。Crossplane
允许用户自定义资源,并通过标准的控制器模式来完成对资源的管理。因此,通过
Crossplane 可以声明式的管理 PaaS 资源。
实际的资源申请场景中,Crossplane 借鉴了 K8s PV 与
PVC
的概念,资源提供方通过创建资源定义来发布可用的资源,而资源使用方通过构建
Claim 来发出对资源的请求。最后,通过 Crossplane
控制器就能完成这一需求匹配过程。
通过类似 Crossplane 的技术,可以将各种孤立的 PaaS 中间件与企业平台结合起来,并实现代码化、自动化管理。
可观测性
完善的系统可观测能力可以帮助开发者获得对系统运行状态的深入洞察,并从容应对线上问题。可观测能力的成熟度,会直接影响研发效率和服务质量评价。Metrics、Logs 和 Tracing 是最常见的可观测能力,分别采集和分析系统的指标、日志以及链路追踪。通过对这三类数据的整合,开发者能够从统计维度、程序执行维度和用户请求维度对应用进行综合分析。
在 OpenTelemetry 出现以前,上述三种不同类的观测数据各自存在特定的探针、数据格式以及标准,导致系统的设计选择绑定了几种方案而难以替换和扩展,阻碍了新技术的引入。
OpenTelemetry(简称 otel) 作为可观测性系统前后端之间的抽象层,整合了一套标准数据模型,使得数据探针和数据处理系统不再相互依赖。除了各种开源方案对 otel 的支持外,包括 AWS、Azure 和 GCP 在内的许多 CSP 都在其产品内支持了 otel 标准。因此引入 otel 能够极大的增强在可观测性能力上的扩展性。

可扩展的资源编排层
根据 CNCF 对云原生的定义,云原生应用可以在云上自由的弹性扩展。从这一点看,理想的云原生基础设施,应该能为应用提供无限的资源和难以察觉的扩缩速度。虽然理想情况难以实现,但平台有义务提供标准化的生命周期管理与资源编排能力,以便上层用户可以自由的按需使用资源,而不需要考虑资源的管理细节。
K8s 作为云原生的事实标准,显然非常适合作为资源编排层的技术实现。然而,现代化应用的发展趋势,对平台提出了更多变的场景化诉求,如跨区域高可用、租户强隔离、地区法律合规、精确控制成本等。这就要求资源编排层能支持差异化基础设施的灵活扩展,叠加精准的编排调度能力,为上层用户提供匹配其诉求的抽象资源。
事实上,单一基础设施下的 K8s 容器集群难以满足上述诉求,而多集群管理技术是一种可行的解决方案。通过 K8s 多集群管理技术,资源编排层能够提供三大能力:应用灵活调度、标准资源抽象、基础设施动态扩缩。
应用灵活调度
多集群本质上是为了让应用运行在更合适的位置。为了高可用、成本控制、合规性等目的,业务应用可能需要被动态调度到不同的 K8s 集群上。实施调度的关键是调度策略。
通过调度策略,我们期望能解决 “什么样的应用” 需要被调度到 “哪类集群” 的问题。显然,应用有其自身独特的属性集,集群也一样。从属性集的角度看,调度策略问题就可以转化为应用与集群属性集之间的最优匹配问题。
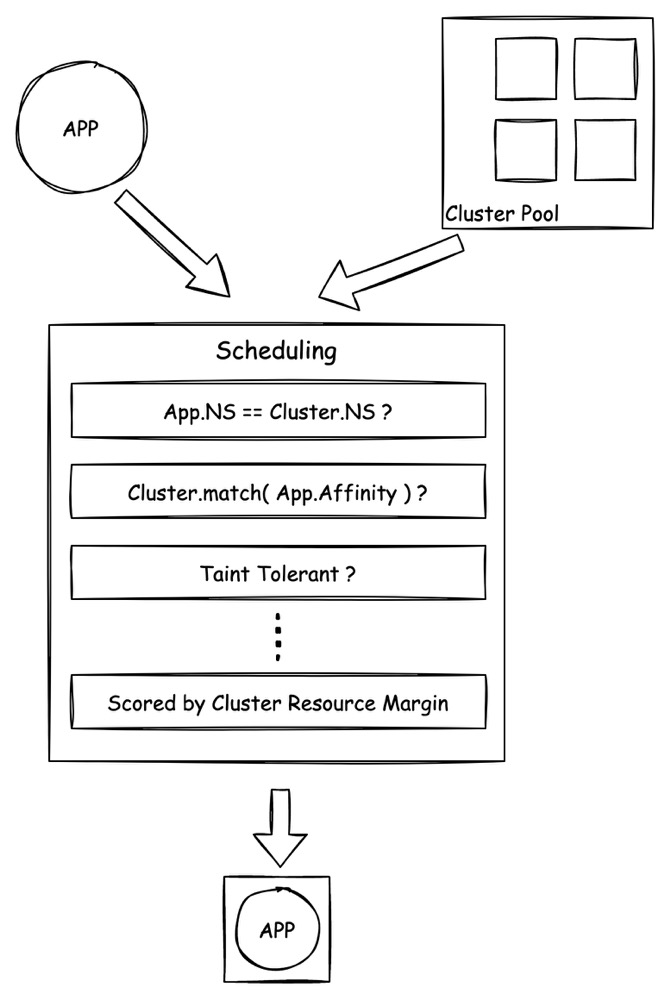
进行调度决策时,待调度应用与待选集群的属性集依次通过过滤型决策器和打分型决策器,最终找到一组分数最高的集群,调度完成。而下达调度决策的前提,是多集群控制面能准确的获悉集群中的各种状态,因此状态数据的收集也至关重要。
Karmada 是一种多集群解决方案,它实现了动态调度
标准资源抽象
K8s 社区一方面鼓励各类定制发型版以保持社区生态的健康发展,另一方面 CNCF 也提出了 K8s一致性认证 用来确保所有发行版在 API 层面与公版兼容,从而一定程度上达成在认证发行版之间灵活切换的能力。然而,但即使是一致性认证的存在,企业在选择扩展 K8s 时也仍然会面临多集群之间版本一致性、版本升级的困难。
针对上述问题,资源抽象层需要向上提供稳定的资源抽象,向下应对多版本和非标准 API。对此有两种解决方案:
在底层对集群版本进行限制和管理,确保任意基础设施上构建的 K8s 都保持同一版本。该方式主要适用于对基础设施拥有足够的选择空间的场景。
Gardener 是 SAP 开源的 K8s 集群生命周期管理方案,在设计概念上,Gardener 能够确保由其管理的 K8s 集群具有完全相同的版本、配置和行为,这简化了应用的多云迁移。Gardener 还提供了一个页面专门介绍其不同版本的标准化K8s 集群与不同云提供商的兼容情况。

提供对非标准资源 API 的标准化收敛,通过在 Proxy 层嵌入各类
Converter插件,将非标准 API 映射为标准抽象。该方式更适合于部分企业可能因特殊需要而只能选择某些 “魔改” 版本(显然无法通过一致性测试)的场景。
基础设施动态扩缩
为了更好的满足资源编排层的扩展需求,通过实现集群动态扩缩,可以获得类似 “集群即资源” 的能力。然而不论是基于云虚拟机自建 K8s,还是直接使用 CSP 定制化的代管集群,在各种基础设施上构建 K8s 都涉及到许多适配性工作。如果由平台团队来实施这些适配,不仅工作量大,扩展性也很弱。在软件工程领域,解决此类问题的最佳方式就是定义标准化接口,并由供应商来实现(例如 Linux 的 VFS)。
如今的确存在这种标准化接口。ClusterAPI(简称
CAPI) 是 K8s “Cluster Lifecycle SIG” 发起的项目,CAPI
尝试通过定义标准基础设施 API 来统一集群生命周期管理,各类 CSP
自行提供实现了标准 API 的 Provider
来支持自动化操作集群资源,由于其官方背景,目前已有数十种
Provider 可供选择(不仅包含 aws 等公有云,还包含了
OpenStack,OCI 等其他方案)。
CAPI 的价值不仅在于对各种 CSP 的全面适配,更重要的是通过它能够实现集群的自动化创建和销毁,也就实现了集群即资源,从而能极大的提升资源编排层的扩展性。

总结
本文首先讨论了企业在建设平台工程能力过程中存在差异化的场景和诉求,基于这一原因,我们期望通过构建可扩展的软件栈架构,使企业能够尽可能的借助开源社区的力量,在成本可控的前提下建设自己的内部平台。
可扩展的前提是足够的抽象,通过划分三个抽象层,我们能够在应用能力诉求、DevOps 组件、资源编排调度这三个维度上分别实现灵活可扩展。叠加云原生生态中的丰富开源方案,组合起来,就构成了完整的软件栈。