【翻译】性能改善代码编辑的研究
本文是对论文 LEARNING PERFORMANCE-IMPROVING CODE EDITS 的翻译
摘要
随着摩尔定律的衰落,优化程序性能成为软件研究的一大焦点。然而,由于难以理解代码的语义,诸如 API 和算法更改之类的高级优化仍然难以实现。同时,预训练的大型语言模型(LLMs)在解决广泛的编程任务方面表现出强大的能力。为此,我们引入了一个使 LLMs 适应高级程序优化的框架。首先,我们策划了一个由人类程序员对超过 77k 组 C++ 竞赛性编程的提交进行性能改进的数据集,并附有广泛的单元测试。一个主要的挑战是在商品硬件上测量性能的显著可变性,这可能导致虚假的“改进”。为了隔离并可靠地评估程序优化的影响,我们设计了一个基于 gem5 全系统模拟器的环境,这种模拟器是学术界和工业界的事实标准。接下来,我们提出了广泛的代码优化适应策略;对于提示词,包括基于检索的多范例提示(retrieval-based few-shot prompting)和思维链(chain-of-thought),对于微调,包括基于自博弈(self-play)的性能条件生成和合成数据增强。这些技术的组合在 CodeLlama-13B 上实现了 5.65 倍的平均加速,在 GPT-3.5 上实现了 6.86 倍的平均加速,超过了人类的最佳表现(4.06 倍)。我们发现我们提出的性能条件生成在提高性能以及增加优化程序的比例方面特别有效。(我们将在验收合格后发布代码和数据。附件是 PIE 样品,作为补充材料。)
1 介绍
尽管业界已经在优化编译器和其他性能工程工具方面取得了令人印象深刻的进展(Aho et al.,2007),但程序员仍然是高级别的性能考量(如选择算法和 API)的主要负责人。最近的工作已经证明了深度学习在自动化性能优化方面的前景(Garg et al.,2022; Mankowitzetal.,2023 )。然而,由于缺乏开放的数据集和可靠的性能测量技术,这些技术要么适用面狭窄,要么难以构建,这阻碍了该方向的研究。最近,预训练的大型语言模型(LLMs)在广泛的编程任务中展示出令人印象深刻的表现(Chen et al., 2021b; Fried et al., 2022; Xu et al., 2022; Nijkamp et al., 2022)。然而,大型、预训练的 LLMs 对程序优化的有效性仍然是一个开放的研究问题。我们研究这些 LLMs 是否可以用于性能优化。为此,我们引入了一种新的性能优化基准,该基准解决了可复现性能测量的关键挑战,并对基于它的各种适应技术进行了广泛的评估。
首先,我们构建了一个性能改进编辑(Performance-Improving Edits PIE)数据集。我们收集为解决竞赛性编程问题而编写的 C++ 程序,在这些程序中,我们跟踪单个程序员的提交(因为它们随着时间的推移而演变),并过滤出与性能改进相对应的编辑序列。
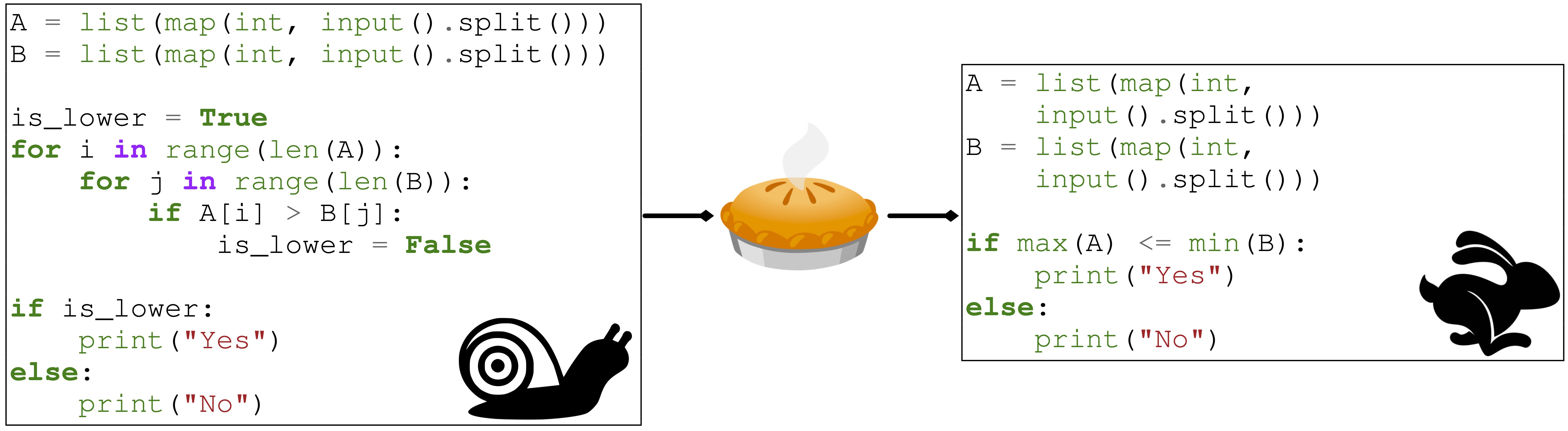
图1:解决 “计算从 1 到 N 的数字之和” 问题的程序示例。左边的程序在 O(N) 下运行,而右边的程序在常数时间下运行。PIE 的目标是使 LLMs 能够执行这些类型的程序优化。
接下来,一个主要的挑战是,由于服务器工作负载和配置问题,在真实硬件上测量性能的显著可变性。事实上,我们发现在真实硬件上进行基准测试可能会导致巨大的、虚幻的性能 “改进”,这仅仅是由于随机性机会导致。为了应对这一挑战,我们使用 gem5 CPU 模拟器(Binkert et al., 2011)来评估性能,gem5 是学术界和工业界的黄金标准 CPU 模拟器,并对最先进的通用处理器进行建模。这种评估策略完全是确定性的,既保证了可靠性,又保证了可复现性。
基于此基准,我们评估了用于适配预训练的代码 LLMs 以进行性能优化的各种技术。首先,我们考虑了基线提示方法,包括思维链(Wei et al., 2022b)(chain-of-thought CoT)等技术。我们发现 LLMs 在代码优化这一具有挑战性的任务上是受限的。如果没有利用 PIE 的数据驱动方法,我们最强的基线 CoT 只能保证 1.61 倍的平均加速,而人类参考的速度为 4.06 倍。接下来我们考虑一种基于检索的提示方法,其中检索用于选择与当前最相似的示例(Liu et al., 2021; Poesia et al., 2021)。最后,我们考虑了几种微调策略:这些策略包括使用通过自博弈( Haluptzok et al., 2022)生成的合成数据,其中合成训练样例由 LLM 生成,而不需要直接的人类样例,以及性能条件生成,其中我们根据生成程序的性能条件生成。
我们发现使用 PIE 的数据驱动方法,如基于检索的多范式提示和微调,在 LLMs 中非常有效地实现了强大的优化能力。当允许一个模型取 8 个样本并对准确性和执行时间进行过滤时,我们的 CODELLAMA 13B 微调性能条件版本可以在我们的测试集上实现 5.65 倍的平均加速,而通过自博弈增强合成数据的 GPT-3.5 的微调版本可以实现 6.86 倍的平均加速,而我们发现的最快的人类解决方案可以实现 4.06 倍的平均加速。综上所述,我们的贡献是:
- 我们引入了一个新的代码数据集,包含超过 77K 组的 C++ 程序,命名为 PIE,并从 gem5 模拟器收集了执行时间注解。PIE 可以对 LLMs 进行可重复的评估,以进行程序优化,并为训练提供可靠的性能注解。
- 通过我们的基准测试,我们评估了不同的提示和微调方法,以适配预训练的 LLMs 来优化程序。我们的结果表明,在没有 PIE 这样的数据集的情况下,预训练的代码 LLMs 在优化代码的能力上是有限的。
- 我们开发了三种有效的策略,使 LLMs 适应代码优化:基于检索的提示、性能调节和自博弈。总体而言,我们的最佳模型,GPT-3.5 增强了从自博弈中获得的合成数据,实现了 6.86 倍的平均加速,并对 87.68% 的测试集实现了至少 10% 的优化。
相关的工作。 除了上述方法之外 ,机器学习还被应用于通过重构代码来提高性能(Mens & Tourwé, 2004; Agnihotri & Chug, 2020),识别编译器转换(Bacon et al., 1994; Talaashrafi, 2022) ,执行参数搜索(Hamadi, 2013; Huang et al., 2019; Kaufman et al., 2021),自动向量化代码(Nuzman et al., 2006; Mendis et al., 2019),优化 GPU 代码(Liou et al., 2020; Cummins et al., 2021),并自动选择算法(Kotthoff, 2016; Kerschke et al., 2019),和顶部的空间(Leiserson et al., 2020; Sherry & Thompson, 2021)。De ep-PERF(Garg et al., 2022)使用基于 Transformer 的模型进行微调,为 C# 应用程序生成性能改进补丁。此外,Chen et al. (2022)使用离散变分自编码器,每个潜在表示映射到不同类别的代码编辑,并规范化代码表示以自动提出性能改进建议,Shypula et al. (2021)从零开始在优化数据上训练 seq2seq 模型,以便在编译后对汇编程序进行超优化,Shi et al. (2019)从零开始使用 RL 训练树- LTSM 以 RL 超优化 halide IR,MAGPIE (Blot & Petke, 2022)使用遗传算法来完成包括优化在内的任务。AlphaCode (Li et al., 2022)利用语言模型在自然语言中生成竞赛性编程问题的解决方案,但它并不试图提高现有解决方案的性能。相比之下,我们聚焦于适配预训练的 LLMs 来进行性能优化。(Chen et al., 2021b; Nijkamp et al., 2022; Tunstall et al., 2022; Xu et al., 2022; Fried et al., 2022)
2 性能改进编辑(PIE)数据集
我们构建了一个适配代码 LLMs 用于性能优化的数据集,重点是优化程序执行时间。我们的数据集是基于人类程序员在 CodeNet(Puri et al., 2021)的一系列竞赛性编程任务中进行的性能改进编辑(PIE)构建的。我们专门聚焦 C++ 程序,因为它是一种与 gem5 模拟器兼容的面向性能的语言。给定一个问题,程序员通常会编写一个初始解决方案,然后迭代地改进它。设 \(Y^u=[y^u_1,y^u_2,...]\) 是用户 \(u\) 为问题 \(x\) 编写的按时间顺序排序的一系列程序。我们从 \(Y^u\) 中删除了不被自动化系统接受的程序,消除了不正确的程序(失败一个或多个单元测试)或花费超过允许运行时间的程序,从而得到程序 \(Y^*=[y^*_1,y^*_2,...,y^*_n]\) 的变化轨迹。
对于每个轨迹 \(Y^*\),我们构造数个 pairs:\(P = (y^1,y^2),(y^1,y^3),(y^2,y^3)...\),并且只保留 \(\frac{(time(y_i)−time(y_{>i}))}{time(y_i)}>10\%\) 的pair,其中\(time(y)\)是 程 序 \(y\) 的测量延迟(即相对时间改进大于 10%)。CodeNet 数据集包括 CPU 时间,但我们发现信息不一致(参见附录 A.9) 。因此,我们使用 gem5 重新标记执行时间,如下所述;为了创建这些带注解的运行时,我们在 gem5 环境中执行了超过 4280 万次模拟。
我们将 \(P\) pair 的结果数据集分成训练/验证/测试集,确保任何特定的竞赛性编程问题只出现在其中一个集中。我们从 1474 个问题中获得了 77967 个 pair 训练集,从 77 个问题中获得了 2544 个 pair 的验证集,从 41 个问题中获得了 982 个 pair 的测试集。对于测试集中的每个 pair,我们还记录了该问题最快的人类提交执行时间;在第 4 节中,我们将这个运行时间作为一个比较点。
测试用例。我们的目标是在保证正确性的同时提高性能。我们通过单元测试来评估正确性;如果单个测试失败,我们就拒绝程序。CodeNet 平均每个问题包含 4 个测试用例。为了提高覆盖率,我们包括了来自 AlphaCode(Li et al.,2022)的额外测试用例,这些测试用例是用一个微调的 LLM 生成的。一小部分测试用例将导致在 gem5 中产生超过 2 分钟的显著超时;在排除它们之后,我们得到训练集中每个问题有 82.5 个中位数测试用例,验证集中每个问题 75 个测试用例,测试集中每个问题 104 个测试用例。更多详细信息请参见附录 A.5。
使用 gem5 进行性能测量。对程序性能进行基准测试是出了名的困难。例如,代码插桩引入了开销,并且许多因素都会导致执行过程中存在很大的差异性,包括服务器负载和操作系统引入的特性。如果不仔细执行基准测试,很容易错误地过度报告程序优化结果。在足够的样本和方差下,对完全相同的程序进行基准测试很容易让我们报告显著的优化结果。
为了说明这些挑战,请考虑 HYPERFINE Peter (2023),这是一个 Rust 库,旨在精确地对二进制文件进行基准测试。我们对 500 个程序“pair”进行了基准测试,其中“慢”和“快”程序是同一份。理想情况下,我们应该有\(\frac{source time}{target time}=1\)(即,两个程序具有相同的性能)。然而,我们观察到平均加速为 1.12 倍,标准差为 0.3 6,前 5% 的 pair 加速为 1.91 倍。这些结果强调了性能测量方面的重大挑战。
为了应对这一挑战,我们使用 gem5(Binkert et al., 2011)最先进处理器的全系统详细微架构模拟器来测量程序性能。在 gem5 中执行确定性程序可提供完全确定性的性能结果,从而可靠地隔离性能改进编辑和再现性的影响。我们使用 gem5 中 Intel Skylake 架构的 veratim 配置(https://github.com/darchr/gem5-skylake-config)。 这种方法的一个优点是,我们的框架可以应用于其他平台,如 ARM 或 RISC-V ,而无需访问这些平台的硬件。
3 适配代码 LLMs 以进行程序优化
3.1 多范例提示
指令提示(Instruction-prompting)。我们使用提示词来指导 LLM 提高给定程序的性能,这种方法通常被称为指令提示(Mishra et al., 2021; Gupta et al., 2022; Longpre et al., 2023);关于提示词的详细信息见附录 A.11 中的图 12。
多范例提示(Few-shot prompting) 。 接下来,我们使用多范例提示(Brown et al., 2020)。特别的,我们创建了一个格式为"\(slow_1 → fast_1 || slow_2 → fast_2 ||...\)"的提示词。在推理期间,将一个慢速测试集程序附加到此提示符并提供给模型。我们通过从训练集中随机抽取两对(快、慢)来创建提示。提示示例如附录 A.11 中的图 13 所示。
思维链(Chain-of-thought)。受思维链(COT)提示(Wei et al., 2022b)的启发,我们还设计了提示词要求 LLM 在实际生成优化程序之前考虑如何优化程序。该策略与多范例提示结合使用。提示示例如附录 A.11 中的图 14 所示。
动态的基于检索的多范例提示。 最近的工作表明,基于检索的机制可以改善需要事实或程序知识的各种任务的语言模型(Liu et al., 2021; Poesia et al., 2021; Rubin et al., 2022; Madaan et al., 2022; Shrivastava et al., 2023)。程序优化是一项不平凡的任务,需要基于性能的算法、数据结构和编程知识;因此,检索高度相关的例子可能会提高 LLMs 的优化能力。例如,动态规划中针对背包问题优化的解决方案可以为硬币更换问题的策略提供信息。通过基于检索的动态提示,我们的目标是将任务与类似的结构或挑战相匹配,从而允许模型更好地利用 PIE 中的模式。我们使用为 C++ 训练的 CodeBertScore 模型(Zhou et al., 2023b)将待优化的程序和 PIE 中的程序嵌入到一起。我们使用 FAISS(Johnson et al., 2019)从训练集中检索 \(K\) 个最接近的程序;并构造一个“\(slow_1 → fast_1 || ...\)”的风格提示。提示示例如附录 A.11 中的图 15 所示。
3.2 微调
我们还考虑使用我们的 PIE 数据集进行微调以改进预训练的代码 LLMs 。除了对整个数据集进行标准微调外,我们还描述了我们使用的其他策略。
数据集不平衡。虽然我们在 PIE 训练数据集中有成千上万的 slow-fast pair,但这些提交的目标只是 1474 个问题,这可能会限制学习模型推广到新程序的能力。此外,提交并不是均匀分布在各个问题上的。为了解决这种不平衡,我们额外引入了一个由 4085 对“高质量”slow-fast pair 组成的子集——特别是,我们采用了加速最高的例子,每个问题不允许超过 4 次提交,平均每个问题 2.77 次提交。考虑到通过 OpenAI API 训练模型的高成本,我们也使用该数据集作为 GPT-3.5 微调实验的基础。
性能条件生成。程序通常可以以多种方式编写,具有不同的性能概况。因此,当使用 PIE 这样的大型数据集训练模型来预测性能改进编辑时,它是在大大小小的改进上进行训练的,而没有任何关于哪些改进比其他改进更令人满意的信息。受最近的提示策略(Zhang et al., 2023)和 offline-rl(Chen et al., 2021a)的启发,我们在训练过程中引入了性能标签,将每个“快速”程序与一个标签关联起来,该标签指示了数据集中所有解决方案的最佳可实现性能。具体来说,标签表明该程序在按 \(\{1,2,...,10\}\) 划分的层阶上距离峰值性能有多近。我们通过将给定任务的数据集中前 10% 的优化解决方案分类为“10/10”来实例化我们的标签,接下来的 10% 分类为“9/10”,以此类推。这些标签使模型能够辨别特定问题属性与其对应的高性能解决方案之间的关系(图 2,左) 。在推理过程中,我们用测试输入和最大分数标签“10/10”提示模型,指导其生成最优解(图 2,右)。

图2:使用 PIE 进行目标条件(Goal-Conditioned)优化的训练(左)和推理(右)提示。
合成数据。考虑到获取人类编写程序的高成本,我们还通过多阶段过程用合成示例来增强我们的数据集。首先,我们用 PIE 数据集的示例提示 OpenAI 的 GPT-3.5 ,指示它生成在给定相同输入的情况下产生不同输出的新程序。在过滤掉产生与 PIE 中相同输出的程序并跟踪生成的程序中的语义重复之后,我们获得了 3314 个唯一的合成程序和数千个重复程序。接下来,我们使用在原始 PIE 数据集上进行微调的 GPT-3.5 模型,为每个合成的“慢”程序生成一个优化版本。最后,我们保留了优化程序至少快 5 倍的 pair,并将语义重复限制在 3 个,从而得到 1485 个优化的合成示例。这种方法与神经程序合成中的自博弈(self-play)和自指导(self-instruct)方法保持一致(Haluptzok et al., 2022; Rozière et al., 2023)。我们在附录 A.6 中提供了关于生成过程的更多详细信息。
4 实验
模型。我们通过 API 对 CODELLAMA 模型(Rozière et al., 2023)和 OpenAI 的模型进行了评估和适配。我们还使用了通过 HuggingFace(Wolf et al., 2020)获得的预训练检查点(Rozière et al., 2023):CODELLAMA { 7B,13B,34B } 。对于 CODELLAMA 系列模型,我们使用未经过指令调优的基本模型集,因为该论文的作者注意到指令调优会降低代码生成的性能。我们在附录 A.8 中提供了训练细节。我们通过提示预训练模型并使用微调 API 对 gpt-3.5-turbo-0613 进行实验。我们通过提示预训练模型来评估 gpt-4-0613;到目前为止,还不能通过 API 对 GPT4 进行微调。
指标。为了评估性能,我们对功能正确的程序进行以下测量:
百分比优化 [%OPT]:测试集中(在 1000 个未见过的样本中)通过某种方法改进的程序的比例。一个程序必须至少提高 10% 的速度和正确率才能做出贡献。
加速 [SPEEDUP]:运行时间的绝对改善。如果 \(o\) 和 \(n\) 是“旧的”和“新的”运行时间,那么 \(SPEEDUP(o,n) = (\frac{o}{n})\) 。必须是正确运行的程序才能参与计算加速。
百分比正确率 [%Correct]:测试集中至少在功能上与原始程序等同的程序的比例(包括作为次要结果)。
如第 2 节所述,如果一个程序通过了我们数据集中的每个测试用例,我们就认为它功能正确。虽然正确性不是我们的主要关注点,但我们包括它来帮助解释我们的结果。此外,我们将 SPEEDUP 报告为所有测试集示例的平均加速。对于不正确或比原始程序慢的几代,我们对该示例使用 1.0 的加速,因为在最坏的情况下,原始程序的加速为 1.0 。我们使用 gem5 环境和第 2 节中提到的所有测试用例对性能进行基准测试。我们使用 GCC 版本 9.3.0 和 C++ 17 以及 -O3 优化标志编译所有 C++ 程序;因此,任何报告的改进都将是那些优化编译器之上的改进。
解码策略。已知代码生成受益于对每个输入采样多个候选输出并选择最佳输出(Li et al., 2022);在我们的例子中,“最佳”是通过所有测试用例的最快程序。我们使用 BEST@k 用 k 个样本和 0.7 的温度来表示这个策略。我们在表 1 中概述了我们的结果,在表 2 中展示了我们的基线结果,在表 3 中展示了基于检索的少量提示结果。
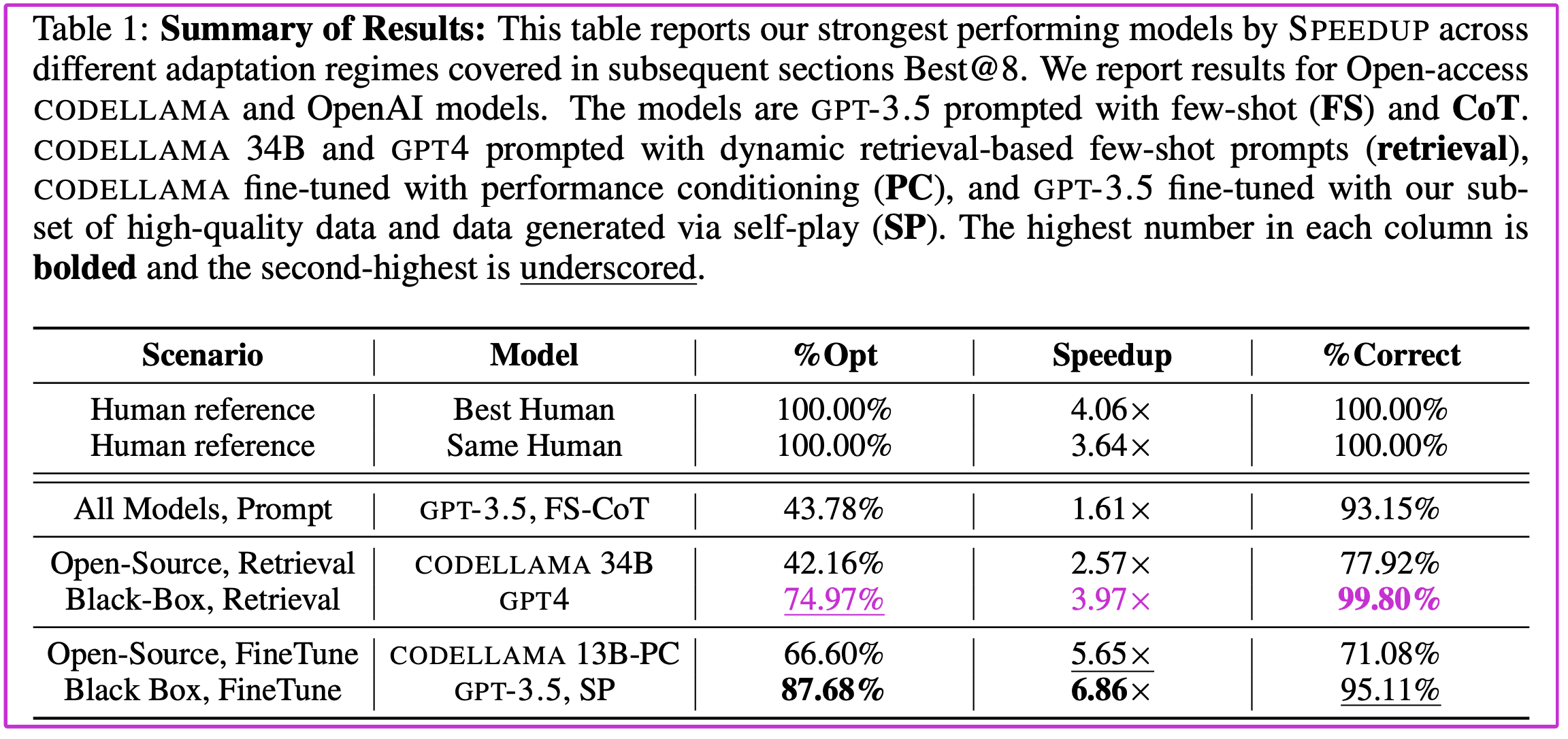
表1:结果摘要:该表通过 SPEEDUP 报告了我们在不同适应机制中表现最好的模型,将在后续章节 Best@8 中介绍。我们报告了开源的 CODELLAMA 和 OpenAI 模型的结果。模型均为基于 GPT-3.5 的多范例(FS)和思维链(CoT) 提示。CODELLAMA 34B 和GPT4 采用基于动态检索的多范例提示(retrieval),CODELLAMA 采用性能条件(PC)进行微调,GPT-3.5 采用我们的高质量数据子集和通过自博弈(SP)生成的数据进行微调。每列中最高的数字被加粗,第二高的数字被加下划线。
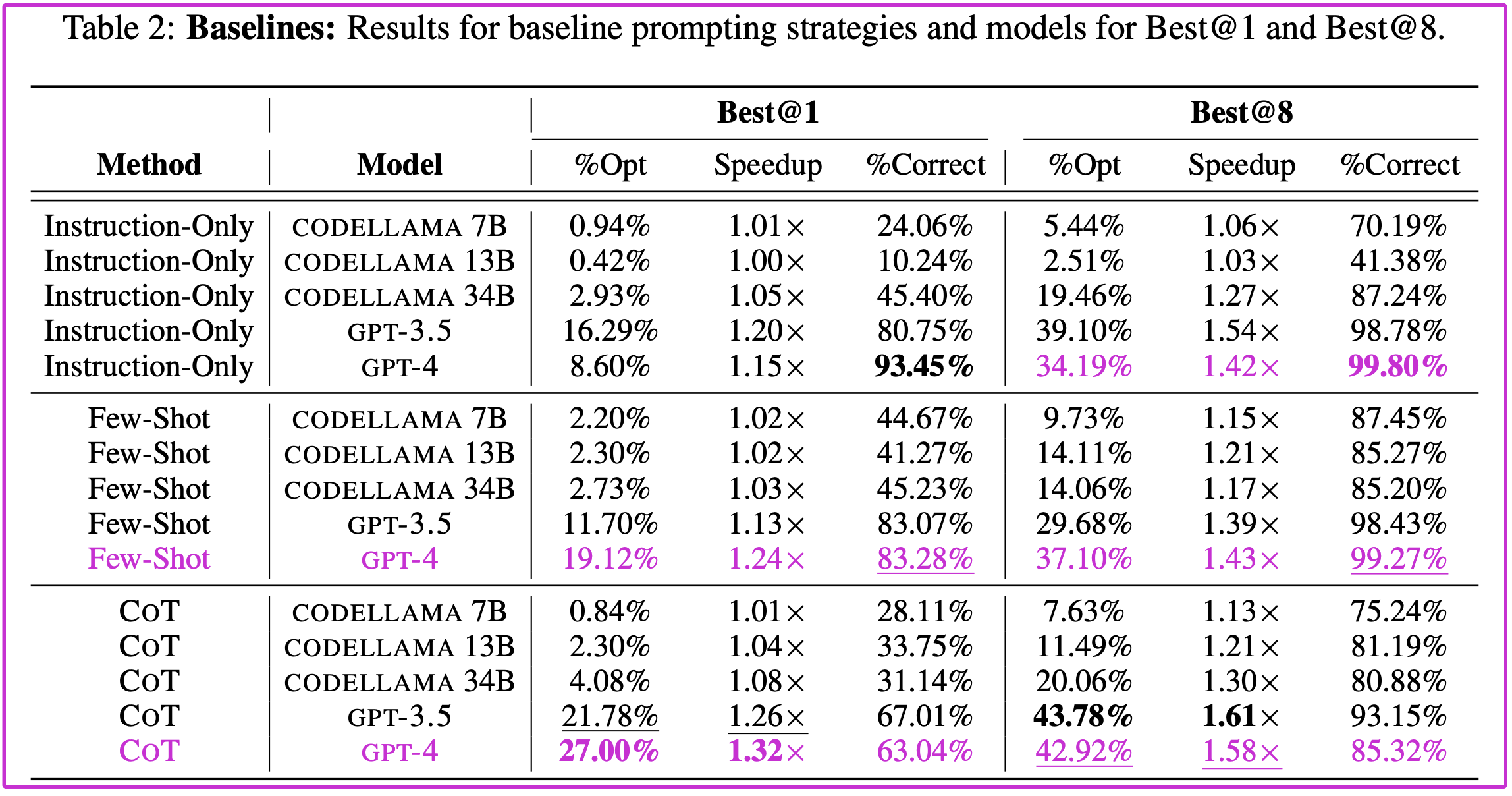
表2:基线:Best@1 和 Best@8 的基线提示策略和模型的结果。
4.1 多范例提示结果
基线多范例提示。表 2(顶部)显示了标准的多范例提示技术的结果(第 3.1 节,提示显示在附录 A.11 中)。我们发现,与简单的指令提示相比,通用的多范例提示通常产生相似的结果。例如,当单独只有提示指令时,GPT-3.5 和 CODELLAMA 34B 都表现出优越的 %OPT 和 SPEEDUP 指标。这一观察结果与 Zhao et al.(2021)的研究结果一致,该研究强调,少量的示例有时会使模型产生偏差,并导致对任务的错误理解。在我们的研究背景下,一致使用相同的固定提示可能会限制模型只应用提示中存在的优化技术,从而导致次优性能。最后,与 Wei et al.(2022a)将 CoT 提示确定为一种紧急能力的研究结果一致,我们观察到该方法在指令调整和固定提示设置上的改进,但值得注意的是,仅适用于较大的 CODELLAMA(13B 和 34B) 和 GPT-3.5 模型。对于 CoT 提示;我们注意到 GPT-4 在 Best@1 情况下优于 GPT-3.5 ,而在 Best@8 情况下低于 GPT-3.5 ;尽管使用相同的采样超参数,这可能表明 GPT4 缺乏输出多样性。
基于检索的多范例提示。表 3(下) 显示了使用我们的基于检索的动态多范例提示策略的结果,最佳设置为 \(K=2\) 检索提示。\(K∈{1 ,2 ,4}\)的扩展结果详见附录 A.7 。结果表明,动态多范例提示优于所有基线变体,表明 PIE 有效地使 LLMs 适应于多范例设置下的程序优化。然而,我们注意到,加速的增加可能会带来一些正确性的代价。
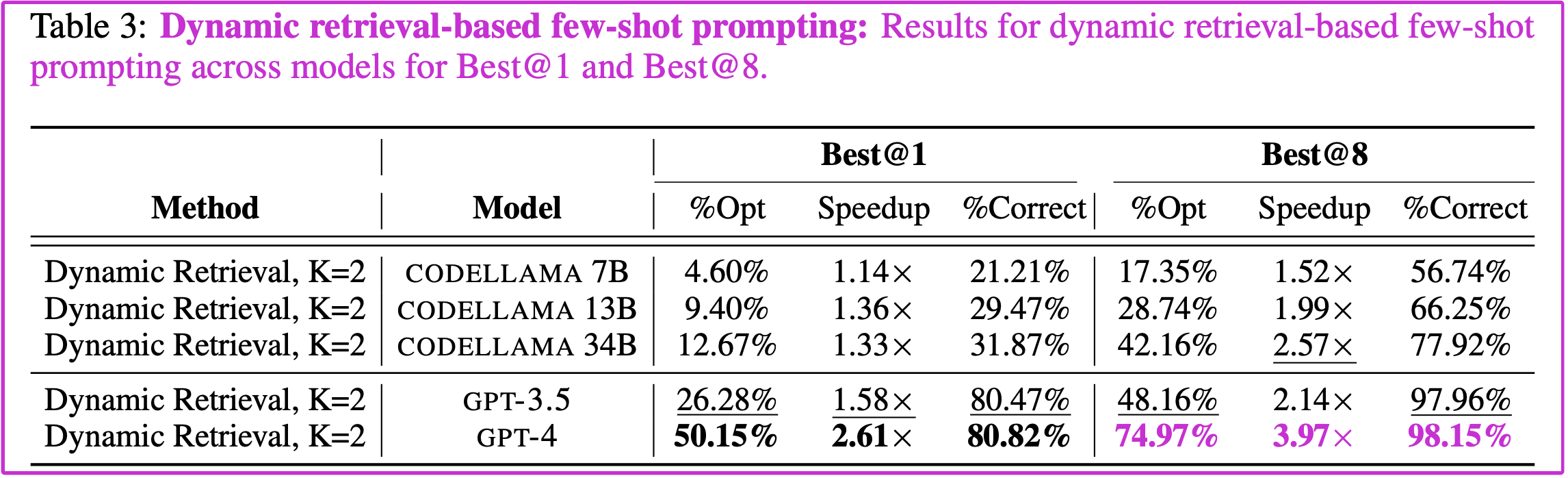
表3:基于动态检索的几次提示:Best@1 和Best@8 模型之间基于动态检索的几次提示的结果。
4.2 微调的结果
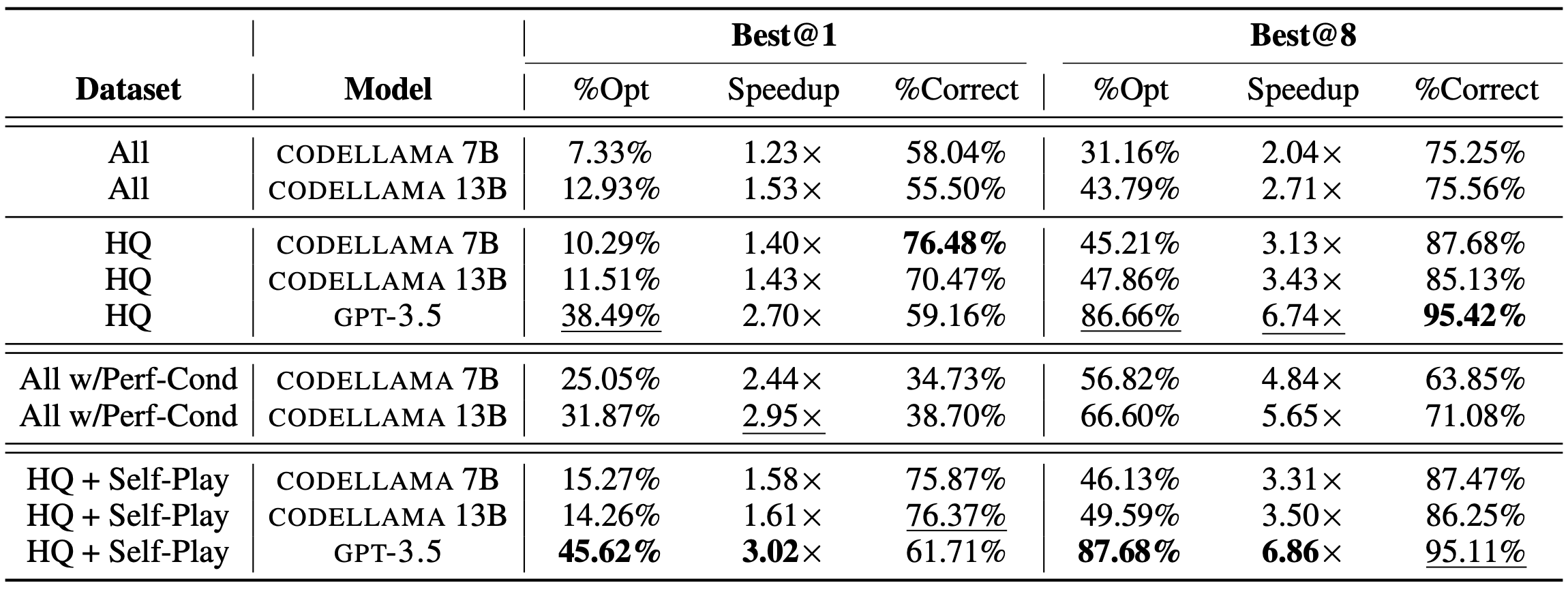
表4:微调:各种模型和数据集配置的结果。
使用 PIE 进行微调大大改进了所有模型。 我们在 PIE 数据集上微调了 CODELLAMA 和 GPT-3.5 模型。由于通过 OpenAI API 进行微调和采样模型的成本,我们只能在 3.2 节中较小的高质量数据集(HQ)上训练 GPT-3.5。表 4 的顶部显示了对所有模型进行传统微调的结果。在更小的、高质量的数据集上进行微调时,我们看到了明显更强的结果。这些结果反映了我们的观察,即为了适应 LLMs,一小部分高质量的示例可以产生强大的性能(Zhou et al., 2023a; Chen et al., 2023)。
性能条件训练优于微调 。 表 4 显示了性能条件(PERF-COND)生成的结果(第 3.2 节)。两种经过微调的 CODELLAMA 模型(7B 和 13B)在 %OPT 和 SPEEDUP 方面都有显著改善。这些增益突出了性能改进信息(图 2)如何使模型能够区分最优和次最优解决方案,从而实现更有效的优化。
来自自博弈(self-play)的合成数据略微提高了泛化能力。 接下来,我们使用 PIE 数据集和合成示例对 CODELLAMA 和 GPT-3.5 进行了微调。我们在表 4 的底部显示了结果。对于 CODELLAMA 和 GPT-3.5,与不使用合成数据相比,额外的数据可以提高 %OPT 和 SPEEDUP,特别是 BEST@1 。我们认为,一小组合成示例有助于推广微调模型,正如较高的 %OPT 所证明的那样。我们注意到,随着样本数量的增加,差异会趋于饱和(详见附录 A.3)。(对于 GPT-3.5,为了确保增长来自数据类型而不是数据数量,我们通过对 PIE 中最多有 8 个重复的前 5793 个示例(而不是包括合成程序的 5570 pair)进行微调来减少影响,我们看到 BEST@1 的 %OPT 降低到 36.66%,SPEEDUP 降低到 2.67, BEST@8 的 %OPT 降低到 83.63%,SPEEDUP 降低到 6.03。)
4.3 讨论和关键要点
CODELLAMA vs. GPT-3.5。 我们的研究结果表明,CODELLAMA 等公开可用的模型可以与 GPT-3.5 竞争。在提示方面 ,CODELLAMA 34B 动态检索(在 BEST@8 时 %OPT=42.16, SPEEDUP=2.57 )的性能与 GPT-3.5 动态检索(在 BEST@8 时 %OPT = 48.16,SPEEDUP=2.14)的性能大致相当。经过微调,性能条件生成的 CODELLAMA 13B(在 BEST@8 下 %OPT=66.60%,SPEEDUP=5.65)接近合成数据生成的 GPT-3.5(在 BEST@8 下 %OPT=87.68%,SPEEDUP=6.86)的性能;事实上,我们可以预期,使用相同的策略对 CODELLAMA 34B 进行微调将进一步弥合这一差距。这些结果表明,通过正确的适配策略,开放模型可以与封闭模型竞争。
提示 vs 微调。我们的结果表明,虽然提示可以是一种有效的方法来适配模型(带检索),但对于相同大小的模型,微调明显优于提示。
基于检索的多范例学习的有效性。我们的研究结果表明,与所有其他提示方法相比,动态检索提供了巨大的收益;例如,对于 BEST@8, 它将 CODELLAMA 34B 的性能从 %OPT=20.07,SPEEDUP=1.61 提高到 %OPT=42.16,SPEEDUP=2.57。
性能条件生成的有效性。 我们发现,性能条件生成对于实现良好的性能非常有效;特别是,它将 CODELLAMA 13B 的性能从 %OPT=47.86 ,SPEEDUP=3.43 提高到 %OPT=66.60,SPEEDUP=5.65(BEST@8)。
LoRA无效。我们还试验了低秩适配器(LoRA)(Hu et al., 2021),但它们的性能明显低于端到端;见附录A.10 的结果。
4.4 生成的代码编辑分析
接下来,我们将研究 LLMs 所做的能够提高性能的编辑类型,重点关注性能最佳的模型,即使用合成数据进行微调的 GPT-3.5 。我们手动分析了 120 个 \((source, optimized)\) pair 程序的随机抽样集,以了解导致性能提升的算法和结构变化。我们发现转换可以大致分为四种:算法变更、输入/输出操作(IO) 、数据结构修改和杂项调整。算法变更(复杂的修改,如将递归方法更改为动态规划,以及意想不到的修改,如省略二叉索引树以使用更简单的结构)是最常见的,占更改的 34.15%;输入/输出操作(例如,将 'cin/cout' 更改为 'scanf/printf',有效地读取字符串)占 ~26.02%;数据结构(例如,从向量切换到数组)占 ~21.14% ,杂项(例如,代码清理和不断优化)占 ~18.70%。详见附录 A.1、附录 A.2 为我们的模型所做的优化示例。
5 结论
我们的工作是释放 LLMs 在利用计算栈“顶部”机会方面的潜力的第一步。特别是,我们提高了算法效率,并且在给定正确性预测的情况下,实现了超越优化编译器的自动代码优化。我们的研究结果为提高后摩尔定律时代的计算效率铺平了一条激动人心的道路。
Reference
Mansi Agnihotri and Anuradha Chug. A Systematic Literature Survey of Software Metrics, Code Smellsand Refactoring Techniques. Journal of Information Processing Systems, 2020.
Alfred V Aho, Ravi Sethi, and Jeffrey D Ullman. Compilers: Principles, Techniques, and Tools, volume 2.Addison-wesley Reading, 2007.
David F Bacon, Susan L Graham, and Oliver J Sharp. Compiler Transformations for High-PerformanceComputing. CSUR, 1994.
Nathan Binkert, Bradford Beckmann, Gabriel Black, Steven K. Reinhardt, Ali Saidi, Arkaprava Basu, Joel Hestness, Derek R. Hower, Tushar Krishna, Somayeh Sardashti, Rathijit Sen, Korey Sewell, Muhammad Shoaib, Nilay Vaish, Mark D. Hill, and David A. Wood. The gem5 Simulator. SIGARCH Comput. Archit. News, 2011.
Aymeric Blot and Justyna Petke. MAGPIE: Machine Automated General Performance Improvement via Evolution of Software. arXiv preprint arXiv:2208.02811, 2022.
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language Models are Few-shot Learn- ers. NeurIPS, 2020.
Binghong Chen, Daniel Tarlow, Kevin Swersky, Martin Maas, Pablo Heiber, Ashish Naik, Milad Hashemi, and Parthasarathy Ranganathan. Learning to Improve Code Efficiency. arXiv preprint arXiv:2208.05297, 2022.
Lichang Chen, Shiyang Li, Jun Yan, Hai Wang, Kalpa Gunaratna, Vikas Yadav, Zheng Tang, Vijay Srini- vasan, Tianyi Zhou, Heng Huang, et al. AlpaGasus: Training A Better Alpaca with Fewer Data. arXiv preprint arXiv:2307.08701, 2023.
Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Misha Laskin, Pieter Abbeel, Aravind Srinivas, and Igor Mordatch. Decision Transformer: Reinforcement Learning via Sequence Modeling. NeurIPS, 2021a.
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ry- der, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, Dave Cummings, Matthias Plappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert-Voss, William Hebgen Guss, Alex Nichol, Alex Paino, Nikolas Tezak, Jie Tang, Igor Babuschkin, Suchir Balaji, Shantanu Jain, William Saunders, Christopher Hesse, Andrew N. Carr, Jan Leike, Josh Achiam, Vedant Misra, Evan Morikawa, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie Mayer, Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, and Woj- ciech Zaremba. Evaluating Large Language Models Trained on Code. ArXiv preprint, 2021b.
Chris Cummins, Zacharias V Fisches, Tal Ben-Nun, Torsten Hoefler, Michael FP O’Boyle, and Hugh Leather. ProGraML: A Graph-based Program Representation for Data Flow Analysis and Compiler Op- timizations. In ICLR, 2021.
Daniel Fried, Armen Aghajanyan, Jessy Lin, Sida Wang, Eric Wallace, Freda Shi, Ruiqi Zhong, Wen-tau Yih, Luke Zettlemoyer, and Mike Lewis. Incoder: A Generative Model for Code Infilling and Synthesis. arXiv preprint arXiv:2204.05999, 2022.
Spandan Garg, Roshanak Zilouchian Moghaddam, Colin B. Clement, Neel Sundaresan, and Chen Wu. DeepPERF: A Deep Learning-Based Approach For Improving Software Performance. arXiv preprint arXiv:2206.13619, 2022.
Prakhar Gupta, Cathy Jiao, Yi-Ting Yeh, Shikib Mehri, Maxine Eskenazi, and Jeffrey P Bigham. Instruct- Dial: Improving Zero and Few-shot Generalization in Dialogue through Instruction Tuning. In EMNLP, 2022.
Patrick Haluptzok, Matthew Bowers, and Adam Tauman Kalai. Language Models can Teach Themselves to Program Better. arXiv preprint arXiv:2207.14502, 2022.
Youssef Hamadi. Combinatorial Search: From Algorithms to Systems. Springer, 2013.
Junxian He, Chunting Zhou, Xuezhe Ma, Taylor Berg-Kirkpatrick, and Graham Neubig. Towards a UnifiedView of Parameter-Efficient Transfer Learning. arXiv preprint arXiv:2110.04366, 2021.
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-Rank Adaptation of Large Language Models. arXiv preprint arXiv:2106.09685, 2021.
Changwu Huang, Yuanxiang Li, and Xin Yao. A Survey of Automatic Parameter Tuning Methods for Metaheuristics. IEEE transactions on evolutionary computation, 2019.
Jeff Johnson, Matthijs Douze, and Hervé Jégou. Billion-Scale Similarity Search with GPUs. IEEE Transac- tions on Big Data, 2019.
Sam Kaufman, Phitchaya Phothilimthana, Yanqi Zhou, Charith Mendis, Sudip Roy, Amit Sabne, and Mike Burrows. A Learned Performance Model for Tensor Processing Units. MLSys, 2021.
Pascal Kerschke, Holger H Hoos, Frank Neumann, and Heike Trautmann. Automated Algorithm Selection: Survey and Perspectives. Evolutionary computation, 2019.
Lars Kotthoff. Algorithm Selection for Combinatorial Search Problems: A Survey. Data mining and con- straint programming: Foundations of a cross-disciplinary approach, 2016.
Charles E Leiserson, Neil C Thompson, Joel S Emer, Bradley C Kuszmaul, Butler W Lampson, Daniel Sanchez, and Tao B Schardl. There’s Plenty of Room at the Top: What Will Drive Computer Performance after Moore’s Law? Science, 2020.
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Ec- cles, James Keeling, Felix Gimeno, Agustin Dal Lago, Thomas Hubert, Peter Choy, Cyprien de Mas- son d’Autume, Igor Babuschkin, Xinyun Chen, Po-Sen Huang, Johannes Welbl, Sven Gowal, Alexey Cherepanov, James Molloy, Daniel J. Mankowitz, Esme Sutherland Robson, Pushmeet Kohli, Nando de Freitas, Koray Kavukcuoglu, and Oriol Vinyals. Competition-level Code Generation with AlphaCode. Science, 2022.
Jhe-Yu Liou, Xiaodong Wang, Stephanie Forrest, and Carole-Jean Wu. GEVO: GPU Code Optimization using Evolutionary Computation. TACO, 2020.
Jiachang Liu, Dinghan Shen, Yizhe Zhang, Bill Dolan, Lawrence Carin, and Weizhu Chen. What Makes Good In-Context Examples for GPT-3? arXiv preprint arXiv:2101.06804, 2021.
Shayne Longpre, Le Hou, Tu Vu, Albert Webson, Hyung Won Chung, Yi Tay, Denny Zhou, Quoc V Le, Barret Zoph, Jason Wei, et al. The Flan Collection: Designing Data and Methods for Effective Instruction Tuning. arXiv preprint arXiv:2301.13688, 2023.
Ilya Loshchilov and Frank Hutter. Decoupled Weight Decay Regularization. arXiv preprint arXiv:1711.05101, 2017.
Aman Madaan, Niket Tandon, Peter Clark, and Yiming Yang. MemPrompt: Memory-assisted Prompt Edit- ing with User Feedback. In EMNLP, 2022.
Daniel J Mankowitz, Andrea Michi, Anton Zhernov, Marco Gelmi, Marco Selvi, Cosmin Paduraru, Edouard Leurent, Shariq Iqbal, Jean-Baptiste Lespiau, Alex Ahern, et al. Faster Sorting Algorithms Discovered using Deep Reinforcement Learning. Nature, 2023.
Charith Mendis, Cambridge Yang, Yewen Pu, Dr Amarasinghe, Michael Carbin, et al. Compiler Auto- Vectorization with Imitation Learning. NeurIPS, 2019.
Tom Mens and Tom Tourwé. A Survey of Software Refactoring. IEEE Transactions on software engineering, 2004.
Swaroop Mishra, Daniel Khashabi, Chitta Baral, Yejin Choi, and Hannaneh Hajishirzi. Reframing Instruc- tional Prompts to GPTk’s Language. arXiv preprint arXiv:2109.07830, 2021.
Artur Niederfahrenhorst, Kourosh Hakhamaneshi, and Rehaan Ahmad. Fine-Tuning LLMs: LoRA or Full- Parameter? An In-Depth Analysis with Llama 2, 2023. Blog post.
Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong. CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis. arXiv preprint arXiv:2203.13474, 2022.
Dorit Nuzman, Ira Rosen, and Ayal Zaks. Auto-vectorization of Interleaved Data for SIMD. ACM SIGPLAN Notices, 2006.
David Peter. hyperfine, 2023.
Gabriel Poesia, Alex Polozov, Vu Le, Ashish Tiwari, Gustavo Soares, Christopher Meek, and Sumit Gul-wani. Synchromesh: Reliable Code Generation from Pre-trained Language Models. In ICLR, 2021.
Ruchir Puri, David Kung, Geert Janssen, Wei Zhang, Giacomo Domeniconi, Vladmir Zolotov, Julian Dolby, Jie Chen, Mihir Choudhury, Lindsey Decker, Veronika Thost, Luca Buratti, Saurabh Pujar, Shyam Ramji, Ulrich Finkler, Susan Malaika, and Frederick Reiss. CodeNet: A Large-Scale AI for Code Dataset for Learning a Diversity of Coding Tasks. arXiv preprint arXiv:2105.12655, 2021.
Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, et al. Code Llama: Open Foundation Models for Code. arXiv preprint arXiv:2308.12950, 2023.
Ohad Rubin, Jonathan Herzig, and Jonathan Berant. Learning To Retrieve Prompts for In-Context Learning. In ACL, 2022.
Yash Sherry and Neil C. Thompson. How Fast Do Algorithms Improve? [Point of View]. Proceedings of the IEEE, 2021.
Hui Shi, Yang Zhang, Xinyun Chen, Yuandong Tian, and Jishen Zhao. Deep Symbolic Superoptimization without Human Knowledge. In ICLR, 2019.
Disha Shrivastava, Hugo Larochelle, and Daniel Tarlow. Repository-Level Prompt Generation for Large Language Models of Code. In ICML, 2023.
Alex Shypula, Pengcheng Yin, Jeremy Lacomis, Claire Le Goues, Edward Schwartz, and Graham Neubig. Learning to Superoptimize Real-world Programs. arXiv preprint arXiv:2109.13498, 2021.
Delaram Talaashrafi. Advances in the Automatic Detection of Optimization Opportunities in Computer Programs. PhD thesis, Western University, 2022.
Lewis Tunstall, Leandro Von Werra, and Thomas Wolf. Natural Language Processing with Transformers. "O’Reilly Media, Inc.", 2022.
Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, Ed H. Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus. Emergent Abilities of Large Language Models. arXiv preprint arXiv:2206.07682, 2022a.
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. NeurIPS, 2022b.
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander Rush. Transformers: State-of-the-Art Natural Language Processing. In EMNLP: System Demonstrations, Online, 2020.
Frank F Xu, Uri Alon, Graham Neubig, and Vincent Josua Hellendoorn. A Systematic Evaluation of Large Language Models of Code. In MAPS, 2022.
Tianjun Zhang, Fangchen Liu, Justin Wong, Pieter Abbeel, and Joseph E Gonzalez. The Wisdom of Hind- sight Makes Language Models Better Instruction Followers. arXiv preprint arXiv:2302.05206, 2023.
Zihao Zhao, Eric Wallace, Shi Feng, Dan Klein, and Sameer Singh. Calibrate Before Use: Improving Few-shot Performance of Language Models. In ICML, 2021.
Chunting Zhou, Pengfei Liu, Puxin Xu, Srini Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili Yu, et al. LIMA: Less Is More for Alignment. arXiv preprint arXiv:2305.11206, 2023a.
Shuyan Zhou, Uri Alon, Sumit Agarwal, and Graham Neubig. CodeBERTScore: Evaluating Code Genera- tion with Pretrained Models of Code. arXiv preprint arXiv:2302.05527, 2023b.
附录
A.1 生成代码编辑的附加分析
算法转换(34.15%)。 最主要的转变是算法类别,约占变更的 34.15%。这一类别的编辑表现出复杂的代码重组。一个高频的转变是从递归方法到动态规划方法的转变,这可以显著提高特定问题类型的运行时间。其他的例子包括用更直接的结构代替二叉索引树,去除冗余的条件检查、位操作,在某些情况下,使用数论和代数中的恒等式用公式代替复杂的计算。
输入/输出操作 (26.02%)。 输入/ 输出操作类别,约占变更的 26.02%,主要集中在从 C++ 标准 I/O 方法('cin/cout')过渡到更快的 C 标准方法('scanf/printf')。其他的例子包括逐字符读取字符串 vs 一次性读取,这种转换对于处理大量数据集的问题特别有益,其中 I/O 操作可能是瓶颈。
数据结构修改(21.14%)。 数据结构类别的变化,约占变更的 21.14%,显示了模型在为任务选择最佳数据结构方面的熟练程度。一个反复出现的修改是从向量到传统数组的转变,这加快了访问时间和并减少了开销。此外,这些变化还包括删除指针以支持直接访问,并在适当的时候使用哈希映射。
杂项优化(18.70%)。 杂项类别,包含变更的约 18.70%,捕获了无数的优化。这些范围从代码清理,例如省略不必要的初始化,到用预定义的常量替换计算密集型函数等。
虽然我们的分析展示了各种优化,但有必要解决某些可能被认为是虚假的加速源。具体来说,在我们研究的 120 个案例中,有 10 个案例的加速源于减少用于分配数组的常量。这些加速可能并不总是反映真正的算法改进,并且表明测试用例可能不会完全覆盖所有用例,这是代码合成中的一个开放问题(Li et al., 2022)。因此,虽然它们对整体加速指标有所贡献,但应谨慎解释。尽管如此,我们的分析表明,绝大多数加速都不会受到这个问题的影响,这支持了我们强有力的实证结果。
A.2 优化案例
我们展示了几个例子来展示我们的模型所做的优化的本质。在这些例子中,我们强调了去除浪费的嵌套循环(图4),消除排序的需要(图3),避免不必要的预计算(图5),使用简单的模块化算术属性进行优化(图6),以及重组循环以提高性能(图7)。

图3:用于确定一组输入 pair 的最大值和最小值之间范围的两个程序的比较。PIE 生成的更快的代码(右)直接在一次传递中计算范围的最大开始和最小结束(\(O(n)\)),消除了排序的需要(\(O(nlogn)\))。

图4:以输入 \(x\) 为中心打印 \(2k−1\) 个连续数字的两种代码实现的比较,更快的代码(右)通过直接计算范围而不需要嵌套循环来优化过程,从而产生更高效和简洁的解决方案。较慢代码(左)中红色突出显示的部分表示在优化版本中消除了浪费的嵌套循环。这个循环不必要地在大范围的数字上迭代,只对这些迭代中的一小部分执行有意义的操作。

图5:计算 \(10^9+7\) 的阶乘模的两个代码实现的比较。较慢的代码(左)对 \(10^5\) 以内的所有数字预计算阶乘,并将其存储在数组中。更快的代码(右)只计算给定输入的阶乘,从而产生更节省内存和更快的解决方案。在较慢的代码中,红色突出显示的部分表示在优化版本中消除的预计算步骤。

图6:一个模块化算术问题的优化。较慢的代码天真地检查了 i 和 j 的所有可能组合,导致复杂度为 \(O(10^6)\)。较快的代码利用了模运算的特性,将复杂度降低到 \(O(B)\) 。通过直接计算 \([0,B−1]\)范围内的每个 i 的模运算,它有效地确定是否满足条件\((A \times i) mod B = C\)。请注意,右边的例子更快,但如果包含 break 语句,生成的代码可能会更快。

图7:较慢的代码(左)与其优化后的版本(右)的对比。优化后的代码通过重组循环,避免了循环内部额外的条件检查。
A.3 额外迭代的 GPT3.5 微调模型的收敛
4.2 节的数据显示,在 HQ 数据上进行微调的 GPT-3.5 与 HQ + Self-Play 之间的差距似乎随着迭代数的增加而缩小。使用 HQ 数据进行训练有助于增加模型的覆盖率,使其能够仅用单个贪婪样本优化大量程序。但是,随着抽取的样本越来越多,HQ 和 HQ + Self-play 的性能逐渐收敛到一个相近的水平。我们在图 8 和图 9 中包含了随着样本数量逐渐增加而取得的性能提升图。
此外,在 Self-Play 训练后,正确性略有下降;但加速和正确率从 6.74 → 6.86 和 86.66 → 87.68 有所提升。这揭示了一种准确率-召回率风格的权衡:在合成数据上训练的模型学会了尝试新的优化策略,但这是以犯更多错误为代价的。我们将把这个分析添加到修订版中。
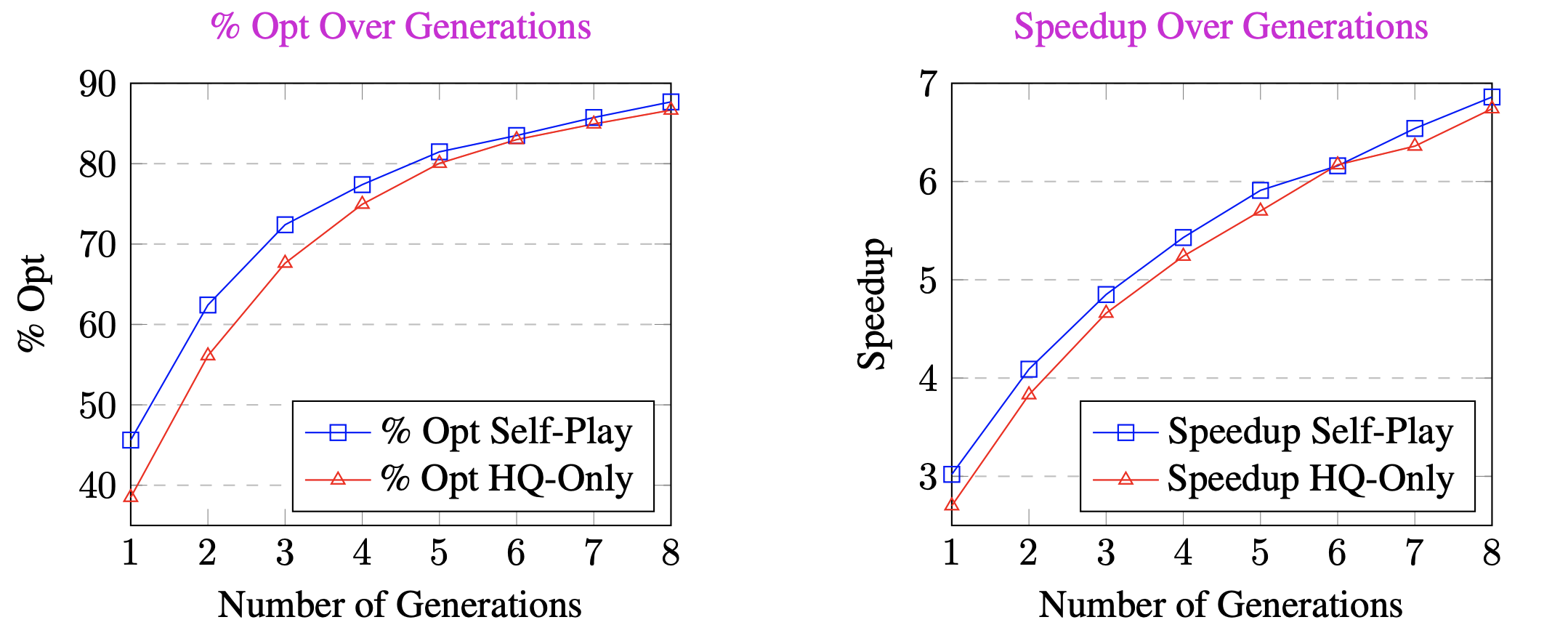
图8(左):经过 HQ Data Only 微调的 GPT-3.5 与 HQ+Self-Play 的迭代间 %Opt 性能比较
图9(右):经过 HQ Data Only 微调的 GPT-3.5 与 HQ+Self-Play 的迭代 Speedup 比较。

表5:使用合成数据进行微调的 GPT-3.5 误差分析。
A.4 误差分析
我们对经过 Self-Play 微调的 GPT-3.5 进行了误差分析。我们分析了它无法优化的生成程序以及每次失败的原因。表 5 显示,很大一部分 ~60% 的失败发生是因为提议的更改破坏了单元测试。在大约 30% 的情况下,模型产生了一个正确的结果 ,但是生成的程序要么更慢(10%),要么没有达到我们的加速阈值(10%)。最后,在大约 10% 的情况下,生成的程序有语法错误。此外,对于测试用例,我们发现,当模型得到错误的程序时,它似乎往往会生成无法通过大多数测试用例的严重错误。
此外,我们还进行了额外的分析,以调查 PIE 未能优化的程序的属性。结果显示,问题描述长度与平均准确率(-0.15)以及源程序长度与平均准确率(-0.26)之间存在轻微的负相关,这表明较长的输入会略微降低准确率。此外,平均加速与问题描述长度(-0.16)和源程序长度(-0.11)都有轻微的负相关,这表明与正确性相比,长度对加速的影响很小。总的来说,这一分析揭示了语言模型在面对更大的源程序和具有挑战性的问题时很难生成正确的程序,但它们优化程序的能力受到的影响最小。这激发了未来的工作方向,即程序修复技术可以与 PIE 相结合,以获得更好的结果。
为什么性能条件会降低生成正确代码的能力?我们认为,仅对模型进行条件调节以生成具有 10/10 优化率的程序可能会限制任何给定输入的可用优化数量。为了研究这一点,我们实验了在 10/10 条件下使用 7b 性能条件模型的前 6 代,而不是在 10/10、9/10 和 8/10 条件下组合前 2 代(即比较一种策略的总 6 代与跨不同策略的总 6 代)。当我们这样做时,我们看到正确率从 59.95% 增加到 64.36%。这些结果支持了性能标签可能会限制生成的正确程序集的解释。
A.5 PIE 数据集详细信息

表6:单一问题 id 的数量。
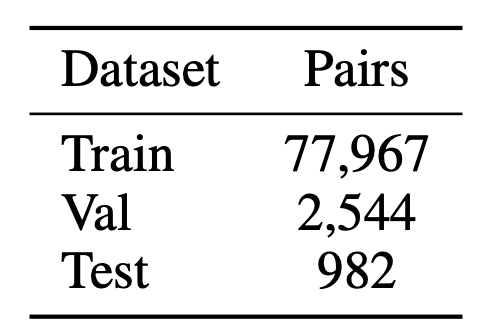
表7:pair 的数量。
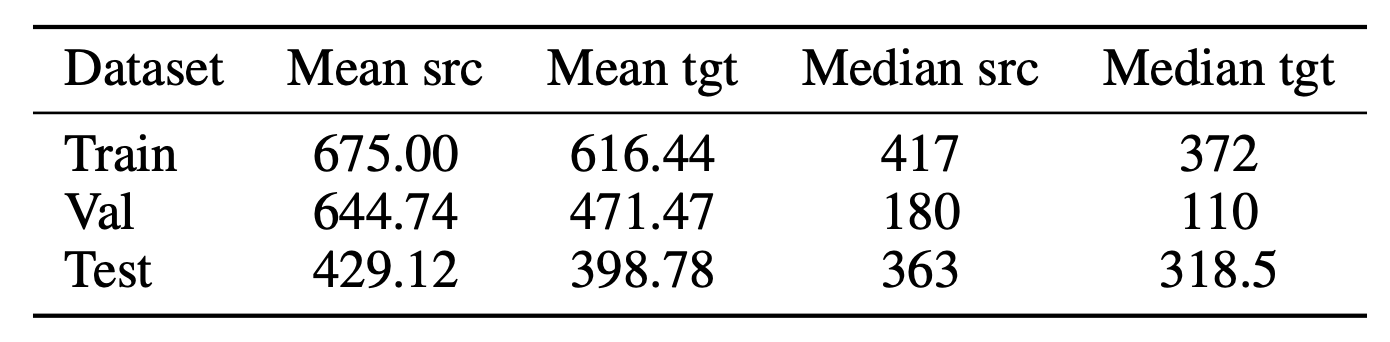
表8:GPT-2 Tokenizer 长度。
A.6 自博弈数据生成细节
我们使用图 10 中的模板在自博弈场景中提示 GPT-3.5 。对于提示词,我们采样编程问题的自然语言描述以及可接受的解决方案来填充模板。对于生成,我们使用温度为 1.0 ,并对于每个提示使用 p=0.9 的 top-p 采样,我们尝试取 n=5 个样本。在对 6 种生成参数配置进行扫描后,我们选择了这些样本,每种配置都试图生成 200 个程序。我们发现这种配置是每个新样本最具成本效益的配置,具有相对有希望的新颖性。

图10:用于提示 GPT-3.5 生成用于自博弈的合成数据的提示模板。
我们发现,在尝试通过提示策略生成 10,000 个新程序后,有 6,553 个不在 PIE 的训练/验证/测试集中。我们跟踪了生成的等效程序,在这 6553 代中,我们发现了 3314 个等效集。总的来说,这需要执行超过 140 万个二维输入pair。在拥有 64GB 内存的 24 核英特尔 13900k 处理器上并行化,这只花了不到 72 小时就完成了。
A.7 消除基于检索的多范例提示配置
对于我们基于检索的提示实验,我们尝试了多种配置来获取检索到的提示的数量,其中 \(K = {1,2,4}\) 最近检索到的提示的 K。
A.8 训练细节
我们使用带 FSDP 的 HuggingFace Transformer 库对 7B 和 13B 变体进行了微调,以跨 8× 48GB GPU(NVIDIA RTX A6000/NVIDIA L40)分发训练过程。对于我们的高质量数据集,由大约 4,000 个示例组成,这些模型经过微调,直到实现收敛,这可以在 12 小时内使用 8 个 GPU 完成。对于与全数据微调和性能条件微调相关的任务,我们只训练 1 个 epoch ,这需要 24 到 36 个小时,具体取决于所使用的 GPU 型号。所有实验都是使用 AdamW 优化器进行的(Loshchilov & Hutter, 2017)。对于 CODELLAMA 的 7B 和 13B 变体,我们对所有实验使用了 32 个 batch 大小和 \(1e^{−5}\) 的学习率。
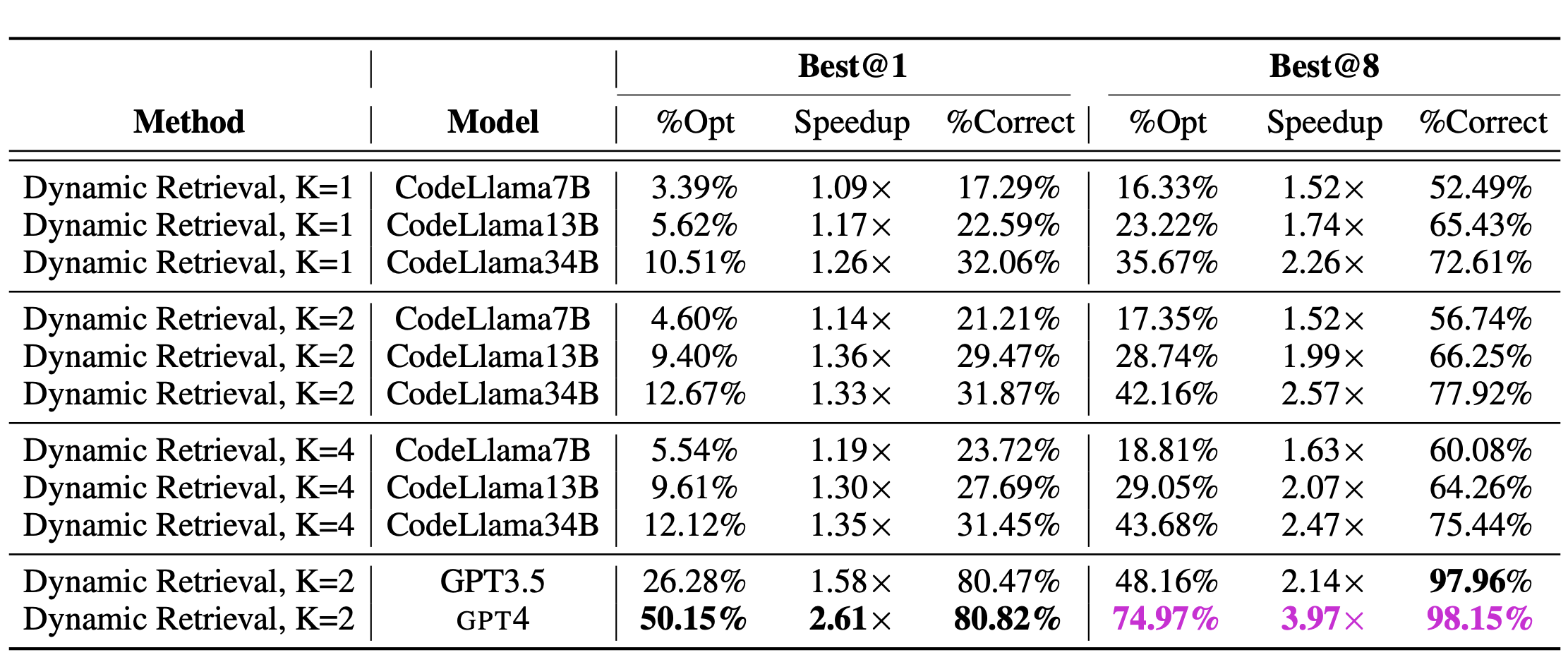
表9:基于检索的少样本提示消融用于检索的不同K个示例和各种模型。
A.9 CODENET 中具有不同测量运行时的重复代码示例
图 11 包含了一个我们发现在 Project Codenet Dataset 中重复的代码示例,在数据集的 CPUTime 报告中存在差异。对于编号为 p03160 的问题,在提交 s766827701 和 s964782197 之间,尽管程序和环境相同,但报告的加速速度为 2.44 倍。我们注意到存在多个提交,因为它是模板代码。为简洁起见,我们删除了宏、导入和注释。
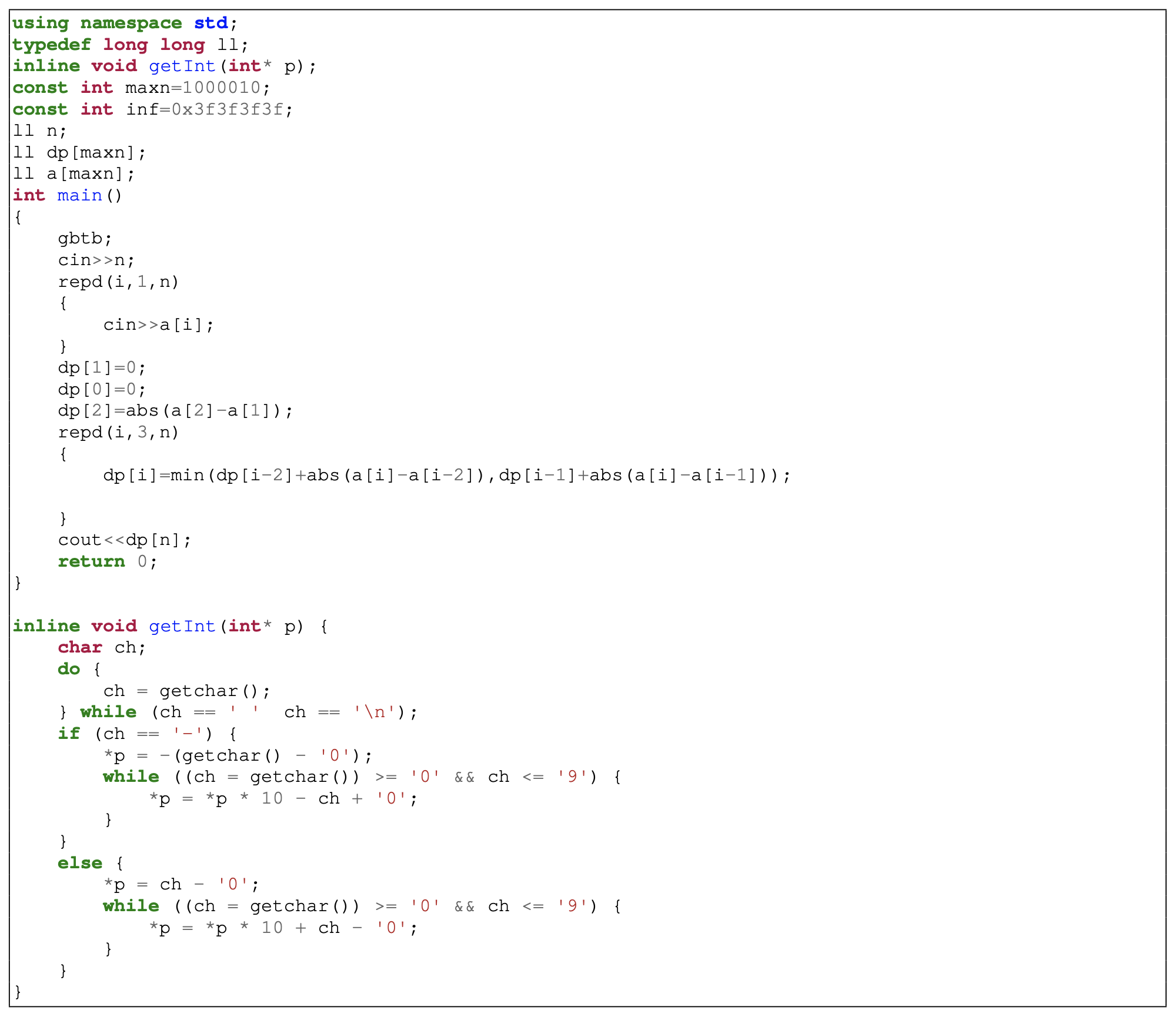
图11:一个 C++ 程序的例子,我们找到了多个提交,因为它是模板代码。在这些提交中,尽管代码和竞赛性编程环境是相同的,但我们发现报告的 CPU 运行时存在差异。
A.10 LoRA 结果
我们在表 10 中显示了使用低等级适配器进行微调的结果。我们假设这种差距可能是因为性能优化示例在训练数据中没有自然发生。
最近的研究表明,参数高效方法的有效性取决于训练数据。例如,He et al. (2021)发现 “在低/中等资源场景下,PEFT 技术的收敛速度比完全调优慢”,Niederfahrenhorst et al. (2023)发现 LoRA 对于数学推理等具有挑战性的任务效果最差。总之,这些研究表明,PEFT 的表现可能严重依赖于任务。我们的假设是基于这样一个事实,即 LoRA 只改变模型参数的一小部分,当基本模型对任务有一定的熟练程度时(由于预训练),LoRA 可能最有帮助,并且可以帮助进一步调整任务的模型。考虑到 LLMs 在没有检索或完全微调的情况下通常对程序优化任务表现不佳,我们假设问题的挑战性和潜在的缺乏预先训练的熟练程度对 LoRA 构成了挑战。

表10:LoRA 实验:低秩适配器微调 CODELLAMA 的结果。LoRA rank 为 32,LoRA alpha 为 16。
A.11 提示

图12:适应 LLMs 的指令提示。为模型提供了直接指令,以提高给定程序的性能。
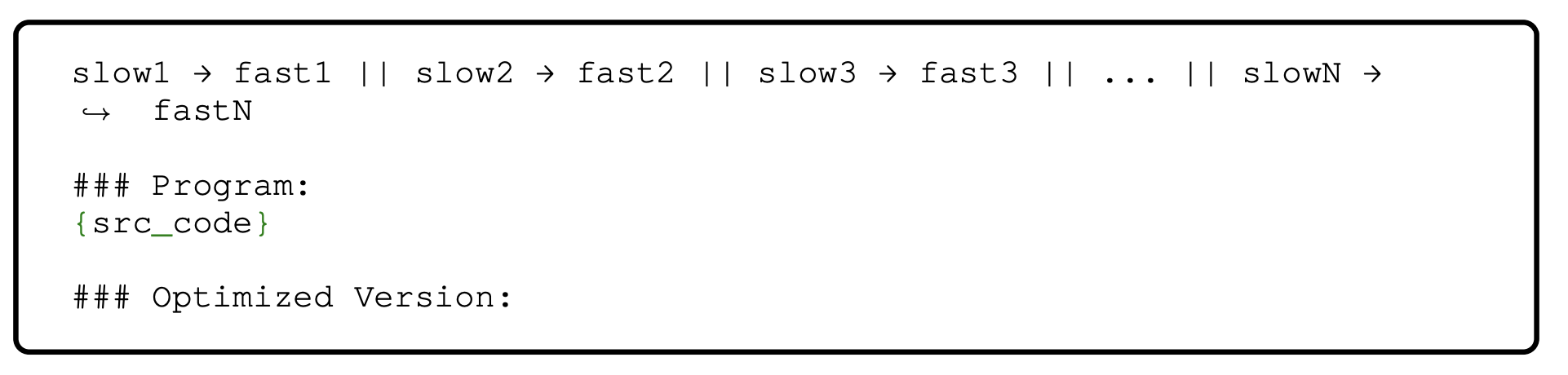
图13:情境学习的多范例提示。采用“慢→快”的格式进行适应。附加测试程序进行推理。

图14:思维链提示。模型的中间响应和最终程序用蓝色突出显示,表明它们是由 LLM 产生的。

图15:基于检索的多范例提示。通过动态检索类似的程序结构或挑战,该模型被引导到更好地利用 PIE 中的模式。

图16:使用 PIE 进行无条件优化的训练和推理提示。

图17:基于检索的提示示例。为了优化图 17(c) 中的程序,我们的动态提示方法从训练集中检索最接近的源程序(图17(a)),其中使用 CodeBertScore (Zhou et al., 2023b)测量相似性。使用训练集中的慢程序和相应的快程序(图17 (b))作为提示符。