/Xv6 Rust 0x04/ - CPU Virtualization

In this chapter, we are going to explore the cpu virtualization, also known as process, in the xv6.
I'm really excited about writing this chapter, because process is one of the fundamental concepts of the operating system. Process is very useful for multiple tasks, and in the design wise, its abstraction is also very elegant.
1. Overview of Virtual CPU
We all know that with the concept if process, we could run multiple programs on one or a few cpu cores, that makes the processes and the cpu cores present as a many-to-many mappings.
But the key point here is, a process will not need to know how many cpu cores and how many memory it can have. Through some sort of abstraction, a process can freely use all cpu and memory resources to run its program, any resource management should have done by the kernel.
So before we take a look at the design of xv6 process, let's think about what elements a process should have, to ensure the cpu virtualization works.
We can simply recap the machine code we introduced in the first two chapters as an analogy, when we built the "xv6-rust-sample", there are few things that need to be taken care of:
- We should understand the address space then link the program to the right places
- There should be a way to load the program and run from the entry point
- Some necessary registers should be initialized, such as stack pointer
- Error handling is also required, like panic
Additionally, standing in the kernel's shoes, more points turn out:
- There are more processes than cpu cores, how to switch different processes on one cpu?
- Where to save process status when it's switched?
- How to manage the process lifecycle, including create, destroy, and error handling?
- How to allocate and restore memory to and from processes
Actually, if a kernel implements all above points, then it has all elements to run multiple processes. So let's take a first look at the design of xv6 process (you can also check the real code at here):
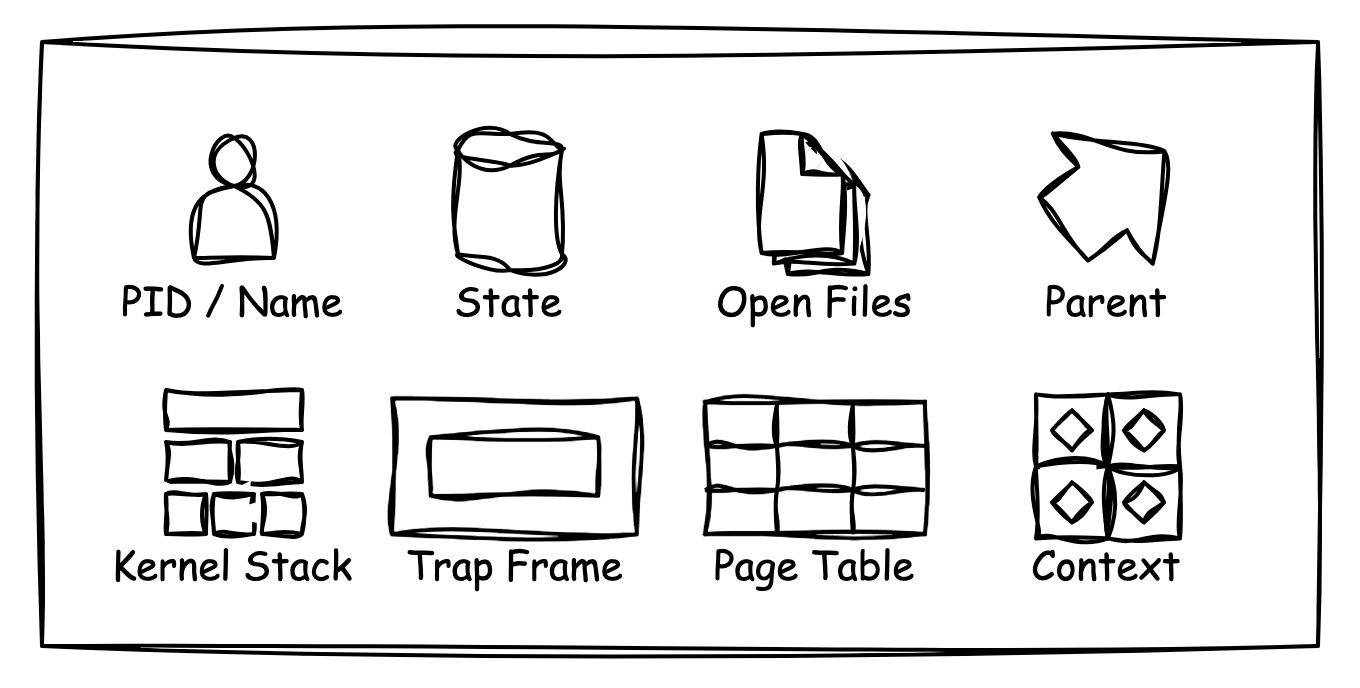
For the elements contained inside the process:
The "PID / Name" identifies a specific process.
The "State" field records the current state of the process, the common state are Running / Runnable / Sleeping, which indicates running on cpu, waiting to be scheduled, waiting to be waken up respectively.
The "Open Files" tracks any files that opened by the process, we haven't talked about file system before, but at least we can realize the basic three files that every process will open are STDIN, STDOUT and STDERR.
The "Parent" to track the process parent, like linux, the xv6 also
creates a new process by fork(), therefore, every process
should have a parent process.
The "Kernel Stack" allows running kernel code on the address space of a process. After all, every process needs to interact with kernel through different types of syscalls, for safety purpose, user process cannot share the same stack with kernel.
The "Trap Frame" stores user space process data, this kind of data will be saved and restored when switching between user space and kernel space. We'll cover this part in the following chapter about interrupt and syscall.
The "Page Table" records the mapping between virtual memory and physical memory. We have described virtual memory in the previous chapter, actually every process should have its own page table.
The "Context" records the basic registers a process is using. When a process needs to be paused and run another process, the current states in the registers should be saved, and once the process can re-run, the registers should be restored.
2. Process Memory
The previous code xv6-rust-sample set it address space
starts from 0x80000000, and put its text section at the
beginning of the address, then set the code entry there. So where should
a process starts from?
We could refer the process creation syscall exec()
to find out (again, we'll cover this in a later chapter):
1 | // exec.rs |
From the above code, we realized the program will be loaded into
ph.vaddr, actually ph means "ProgramHeader",
which is also ELF format, therefore, to find the real entry point, we
have to check the linker
script of user program:
1 | // user/src/ld/user.ld |
Obviously, a user program starts from main, and the
entry address is 0x0. Of cause, we can change that to any
address, because the entry address will be set into the CSR "sepc", and
once the CPU switches to user mode, the user program will start from
there.
Besides, like we mentioned before, every process needs a dedicated stack that allows kernel code running on it. The following code shows the initialization of every kernel stacks:
1 | // proc.rs |
We have already introduced proc_mapstacks() in the
previous chapter, but no details about it. Here, apparently this
function allocates two pages for each process as their kernel stack.
But there are some interesting things here:
- In the original xv6 implementation with C language, one process only has one page of stack, however, in my rust version, many core lib functions were introduced, because one page (4096 bytes) of stack is not enough, lead to risc-v throw an invalid access exception. Hence, the kernel stack is extended to two pages, and that's enough at least now. You may wonder, we have set nearly all address space available for RWX permission (refer to chapter 2, pmpaddr0 / pmpcfg0) how can it be possible to throw an exception of no access permission? Let's move to the second interesting thing.
- The access exception relates to the macro
KSTACK!(). If you see it carefully, you may find this macro actually makes each process has 3 pages of stack space, but we only allocate 2 pages for it, and leave the last page of stack space with no physical memory mapping to it. If any code allocate stack exceeded the 2 pages stack, thespwill point to the third stack page, which is invalid because of no mapped physical memory, then the exception is thrown. This kind of page is called "guard page", it can prevent other process's stack from accidentally overwritten by an overflowed stack operation. (There's a defect here that if the applied stack space exceeded more than one page, then it can break the guard in some cases)
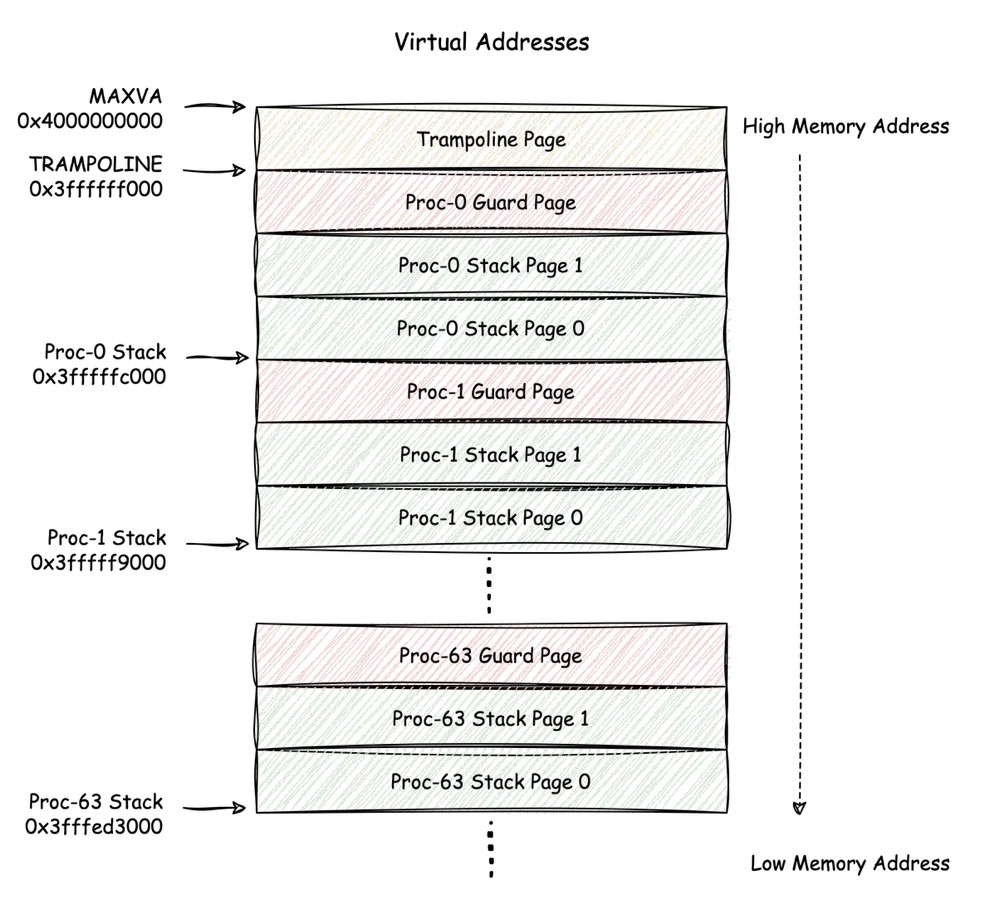
The above image shows the location of the process stacks in kernel
memory layout, it's worth noting that all of these stacks are allocated
while kernel is starting, so they occupy physical memory all the time,
on the contrary, if a user process needs some memory to store data, they
can do that by calling syscall mmap(), which can
dynamically allocate memory space.
3. Concurrency
Once the concept of multiple tasks is introduced, the data contention issue will be definitely along with too. Additionally, although we only assign one cpu core in the QEMU runner, multiple cpu cores is also allowed for xv6 to run. Therefore, there should be some form of mechanisms to take care of the concurrency and parallelization.
The most fundamental thing about concurrency is lock. I suppose you have noticed that there were many code examples in the previous chapters containing locks, but we just ignored them and said we would cover them later. Here we are going to cover this part.
Spinlock
is the simplest lock implementation, the definition is as follows:
1 | // spinlock.rs |
From the definition, we can learn that it's basically a value holder,
locked == 1 indicates the lock is held, otherwise if
locked == 0 means the lock is released. Besides, there is a
reference cpu points to current cpu, which also means the
Spinlock is related to specific cpu.
So how does it work? Let's look closer:
1 | // spinlock.rs |
The Spinlock essentially using the atomic "test and
swap" instruction amoswap provided by risc-v, and in the
phase of acquire, since the lock might be held by another cpu, so it
simply retry forever inside a loop to keep applying the lock (there is
no logic such as wait in a queue to let it wait effectively, because
Spinlock is the simplest implementation here). But when it
comes to releasing the lock, since the lock has already been held by
current cpu, try loop is no longer needed.
However, any unexpected interruption is able to break the lock, so we can notice that once the lock is held, the cpu interrupt will be disabled. Of cause, this will significantly impact the performance, but after all, for a teaching OS, simplicity is more important than performance :) .
At last, the __sync_synchronize() internally call
fence instruction, to keep the memory ordering before and
after the "test and swap". And since the “AMO” instructions in risc-v by
default not support any memory barrier(need to add extra "aq, rl" after
the instruction), and to make sure the compiler can also realize the
memory ordering, the fence is added before and after the
"AMO" instructions to ensure the correct memory ordering in both cpu and
compiler. The memory model of risc-v is complicated, here is a good video
to talk about that.
Now we are familiar with the basic lock, in the next let's take a
look at Sleeplock:
1
2
3
4
5
6
7
8
9// sleeplock.rs
pub struct Sleeplock {
locked: u64, // Is the lock held?
lk: Spinlock, // spinlock protecting this sleep lock
// For debugging:
name: &'static str, // Name of lock.
pid: u32, // Process holding lock
}
Sleeplock holds a Spinlook, which utilize
Spinlook as an internal lock to protect its inner fields.
However, Sleeplock was designed to be a lock that is held
in a relatively long period of time. It doesn't rely on
Spinlock, instead, introduced a "sleep / wakeup" mechanism
to allow the lock sleeping wait until it woken up by the lock holder who
is releasing the lock:
1 | // sleeplock.rs |
In xv6, device interaction logic such as file system reading or
writing would need Sleeplock, as the interaction between
cpu with device often takes a long time. But, how does "sleep / wakeup"
work? Let's go to the next section to see how xv6 deals with process
switching.
4. Scheduling
With the introduction of virtual memory, our process can have its own memory to store the text and data, especially, its stack. Now, there is only one question left, how to put the process on a cpu and run? This question is asked from the process perspective, if we think as we are the kernel, this is an even more important question, how can the kernel run multiple processes simultaneously?
Before deep dive into the kernel implementation to answering the above questions, we should have a preliminary understanding, that is process doesn't decide when to run, kernel does, process doesn't control the switch, kernel does (but process do can influence the kernel‘s decision).
The following image shows the process management and scheduling of the xv6:
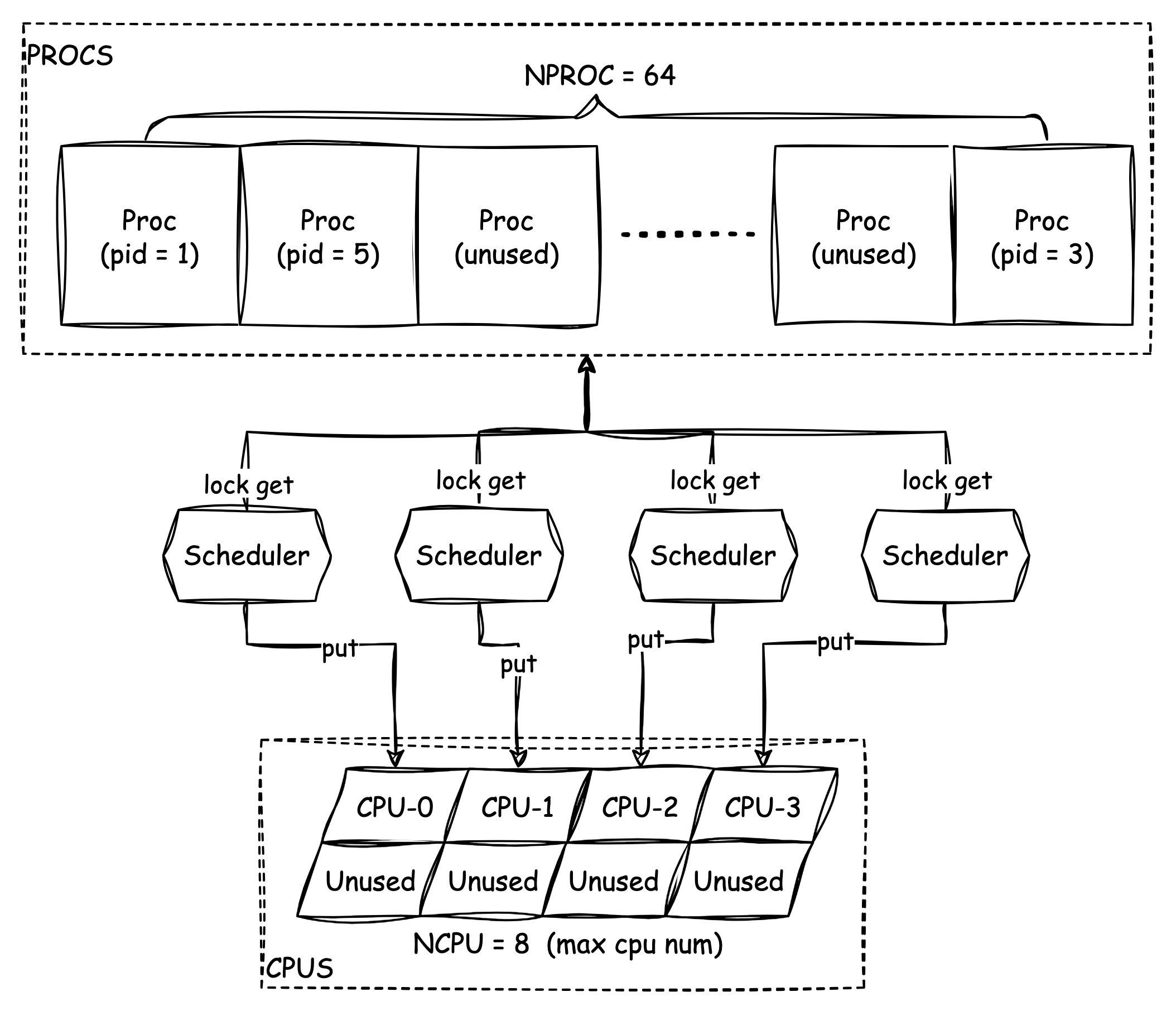
Firstly, there are two arrays that store 64 proc structs and 8 cpu structs respectively, all of the proc structs are empty at the beginning and each of them can hold real process data, as well as cpu structs, which can hold cpu data.
We have talked about what data fields are in the process at the first section, let's see what data filed that a cpu struct can hold:
1 | // proc.rs |
It's very straightforward that a cpu can hold a proc
reference, to indicate the current process that running on the cpu, and
this field can also be empty if there is not much process to be run.
The context hold the registers state that before the
current process has been switched. Therefore, no matter what happens
that let the kernel decide to switch the current process off the cpu,
the context can always be restored so that the kernel
scheduler code can be run to choose the next process.
Other two fields noff and intena are work
together to record the lock depth that is used for controling the
interrupt, we'll check them in the later chapter.
Now let's take a close look at the scheduling. Not like modern multi-tasks OS such as Linux, which has very complicated scheduling component that can make sure the cpu is fully utilized for many different scenarios, instead, the scheduling algorithm is very very simple in the xv6:
1 | // proc.rs |
The code comments have already made it quite clear. Just like the
previous image shows, each cpu has its own scheduler, and the scheduler()
function running in a loop, which only does one thing: pick up a
RUNNABLE process (ready to run but not run yet) and then
put it on current cpu. Of cause due to potential concurrency
modification in the scheduler(),
a lock should be held whenever access the PROCS array.
But how exactly is the process put on the cpu? That relies on a key
assembly function swtch:
1 | ### switch.S |
Basically the swtch
exchanges values of several registers, here is the calling
convention of risc-v:
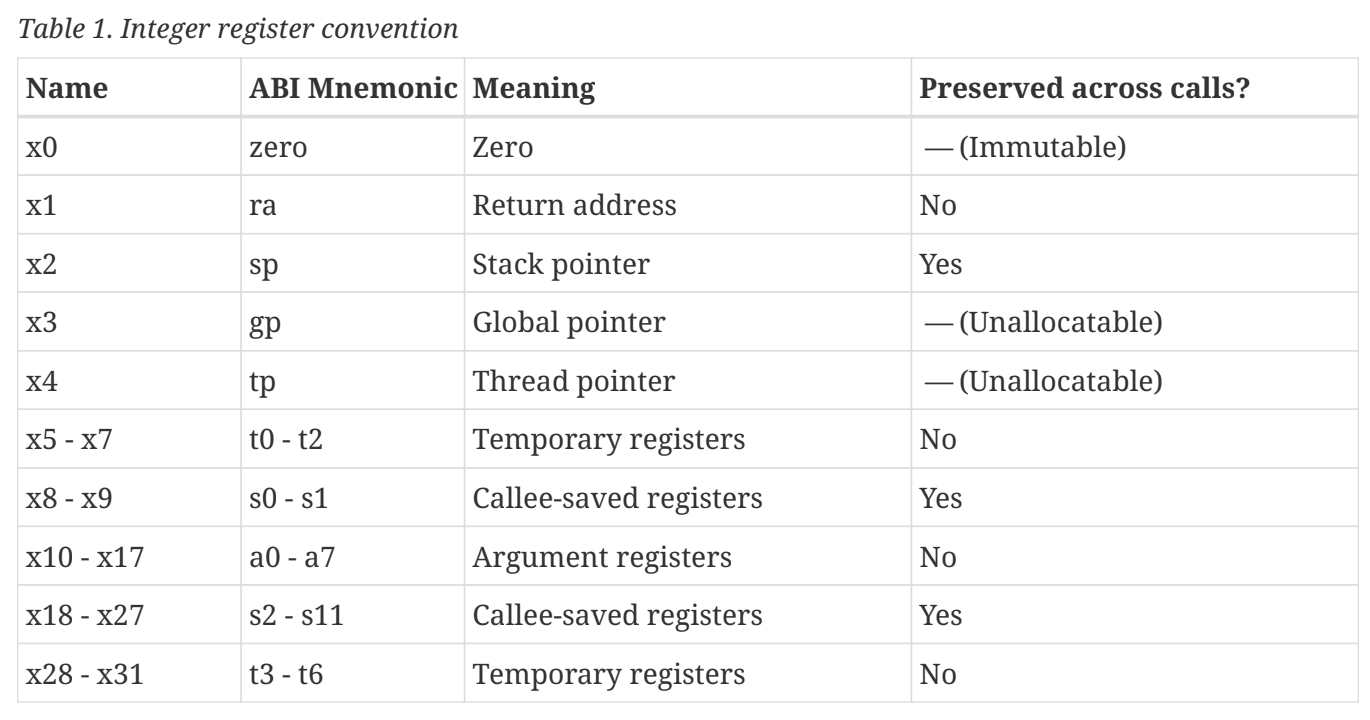
According to this, the ra refers to "return address",
which means after ret the cpu will run code from the
address stored in the ra. The fun thing is a function
usually returns to its calling address, however, swtch
no longer returns to the scheduler(),
instead it will return to the ra from the
p.context, which is the second argument of the swtch.
But what's in the p.context.ra? We need to check the
process creation function inner_alloc():
1 | fn inner_alloc<'a>(p: &'a mut Proc<'a>) -> Option<&'a mut Proc<'a>> { |
See, the ra set to forkret, and the
sp set to the kstack that initialized in the
proc_mapstacks()(we've talked about this function in the
second section). We won't discuss the details of the
forkret in this chapter, but all you need to know right now
is that through forkret
the program can eventually jump to the first line of code in the user
process.
Go back to the swtch, at the same time as the values
from p.context are set to cpu registers, the original
registers are also stored into the first argument
c.context, which is held by the CPU structure.
So next time when the current on-cpu process needs to be switched off
the cpu, the program can be restored to the scheduler().
In the following section, we'll see some cases that will make a process switch off its cpu.
5. Process Lifecycle
As mentioned in the first section, a process has a "State" field to record its status, there are several status defined:
1 | // proc.rs |
I suppose we have seen some of them, for example, when the
PROCS array has been initialized, all of the proc struct it
holds, are set their status to "UNUSED", and once a process has been
created, its state will be set to "USED", refer to the function inner_alloc()
we have just talked.
And if we recap the scheduler()
function, we'll find only a process that state is "RUNNABLE" can be
chosen to put on cpu, and in the meantime, its state will be updated to
"RUNNING".
There are two states left, a process will "SLEEPING" when sleep()
called, the typical case is the Sleeplock, when the lock is
held by another process, the current process that tries to acquire the
lock will go to sleep. While once a process exited by calling exit()
its state will become "ZOMBIE", a zombie process can only been recycled
by freeproc().
There are many new concepts and functions that were brought, don't worry, let's see the full picture of process lifecycle first:
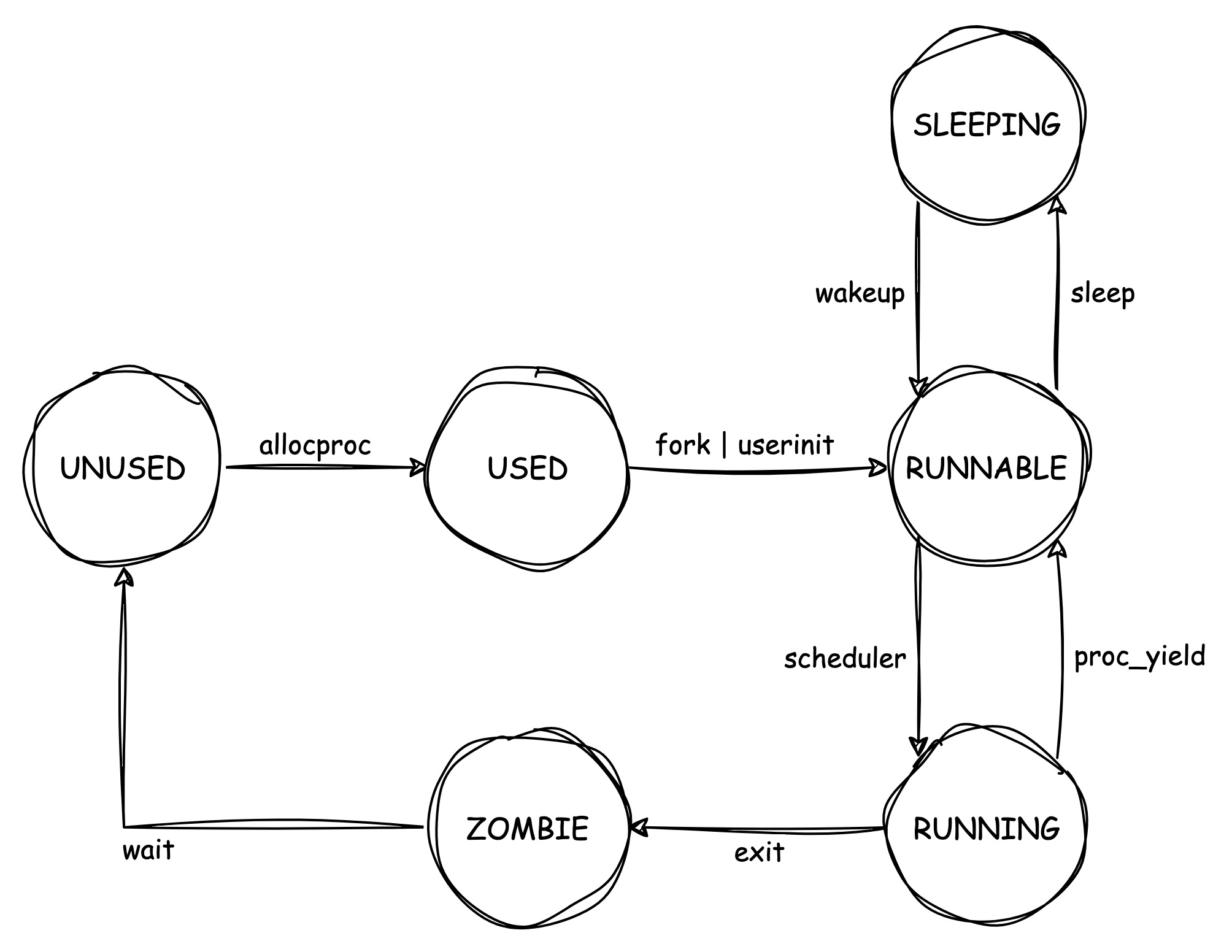
Interesting! There are many different functions that get involved in driving the state change. We'll briefly explain them, for more details please read the code directly.
Generally, from "USED" to "RUNNABLE" happens when a process is being
created. userinit
creates the very first process(the init process, pid = 1) in the entire
system, so the state will be changed in that function. Except for the
special init process, a normal process will often be created through the
fork()
syscall, it also changes state to "RUNNABLE".
We have discussed the scheduling procedure back in the scheduler()
function, but there is also a path that can put a process directly from
"RUNNING" to "RUNNABLE". Please note that, this kind of state change is
not very easy to implement.
For example, there is a user process with content is only an infinite
loop: loop {}, and this loop is running forever. You may
imagine how to stop the infinite loop and switch off the process from
the cpu. Even in the running kernel code in a privileged mode, it's also
impossible to stop it because the loop fully occupied the cpu, expect
for one case, interrupt. BTW, to directly interrupt a program from
running, this type of scheduling way is called "Preemptive
multitasking", conversely, the type that requires the program itself
to assist the scheduling is called "Cooperative
multitasking".
If you still remember, back to chapter 2, there was a function timerinit()
in the start(),
we didn't talk about it at that time, but now we can bring it up. This
function initializes the timer interrupt, which will send an interrupt
every 1/10 sec to every cpu. We'll see more details about trap and
interrupt in the next chapter, now we only need to know that the proc_yiled()
will be called while the timer interrupt is handled:
1 | // proc.rs |
And with the stat is changed to "RUNNABLE", it also calls sched(),
which call the swtch
again, to save the current process context, and restore the previous
context saved in the Cpu struct, the previous saved context
can go back to the scheduler()
and let it choose next process to be run.
Just like that, the sleep()
/ wakeup()
acts as a similar behavior:
1 | // proc.rs |
When a process calls sleep(),
its state will be set to "SLEEPING", and then switch off the cpu. At
that time, the process stops running, and its context is saved into
Proc struct.
Once the wakeup()
is called somewhere, the sleeping process will be found by the
chan filed (with a generic type and acts like a key), then
just simply set the state to RUNNABLE then do nothing,
because after some round of scheduling, it can eventually been chosen to
run. That also implies that a woke up process cannot immediately go back
to running, it must wait a period of time to be re-scheduled. If you
search in the xv6 code base about the sleep()
/ wakeup()
, you'll find that these pair of functions are usually used at the
places that corresponding to file system, uart device and inter process
communication. Because all of these cases share one thing in common,
which is long response time compared to cpu cycles.
At last, you can have a look at the "ZOMBIE" state. There is a
syscall exit(),
when a process finishes its job and wants to exit itself, it can call
it.
1 | // proc.rs |
In addition to setting the exit status and process state, the sched()
is called with a panic follows after it, which means there
is no another way to go back here, if that happens, something's
definitely wrong.
After exit, there is one more step to do, then the state can be changed to "UNUSED" eventually:
1 | pub(crate) fn wait(addr: usize) -> i32 { |
Actually the wait()
is also a syscall, it allows any process can wait its children to be
exited, according to the exit(),
the process will wake up its parent while exit, if the parent calls the
wait()
after create the child process, then the parent will be waken up to
recycle the process, and set its state to "UNUSED".
Generally, when a process creates a child process, it has the responsibility to take care of the exit of the child process as well. But what if there is a careless parent that only creates but never recycles? Or what if the parent process accidentally exits itself due to unexpected errors?
For the first case, if a parent never recycles its children, then
once a child process exited, it will remain in "ZOMBIE" state, until the
parent exits. And after parent exits (it's also the second case), then
all of its children will reparent() to the
init process, and the init will eventually
become their parent and take care of their exit (this behavior is just
like other systems such as Linux does):
1 | // proc.rs |
Let's see the first user process init:
1 | // user/src/init.rs |